📊 Experiments & Results
Evaluation Setup
Causal language modeling on synthetic biographies
Benchmarks:
- Synthetic Factual Recall Task (Fact retrieval / Next token prediction) [New]
Metrics:
- Attribute Loss (Cross-entropy on attribute tokens)
- Attribute Accuracy (Exact match of attribute tokens)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Synthetic Factual Recall Task | Attribute Loss | Entropy of attribute distribution (Theoretical) | Matches baseline during plateau | 0 |
| Synthetic Factual Recall Task | Steps to Convergence | Includes Plateau Phase | Zero Plateau | Plateau removed |
Experiment Figures
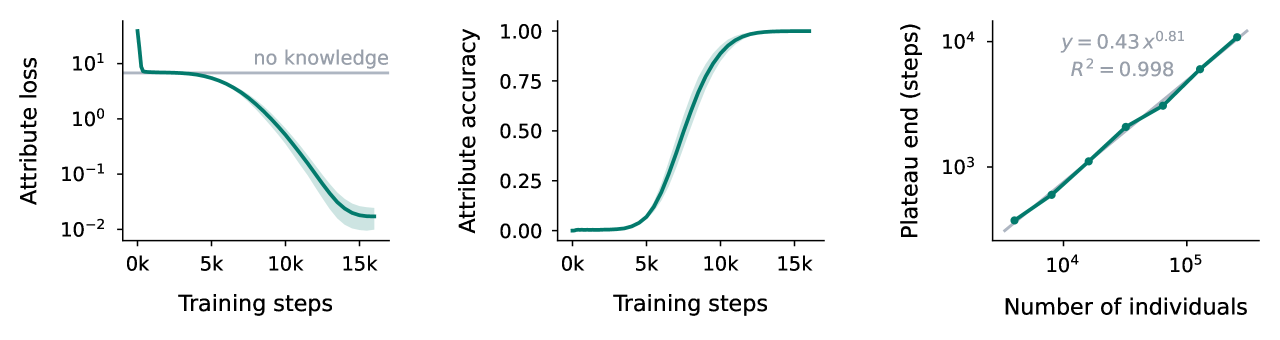
Evolution of attribute loss over training steps for different population sizes (N).
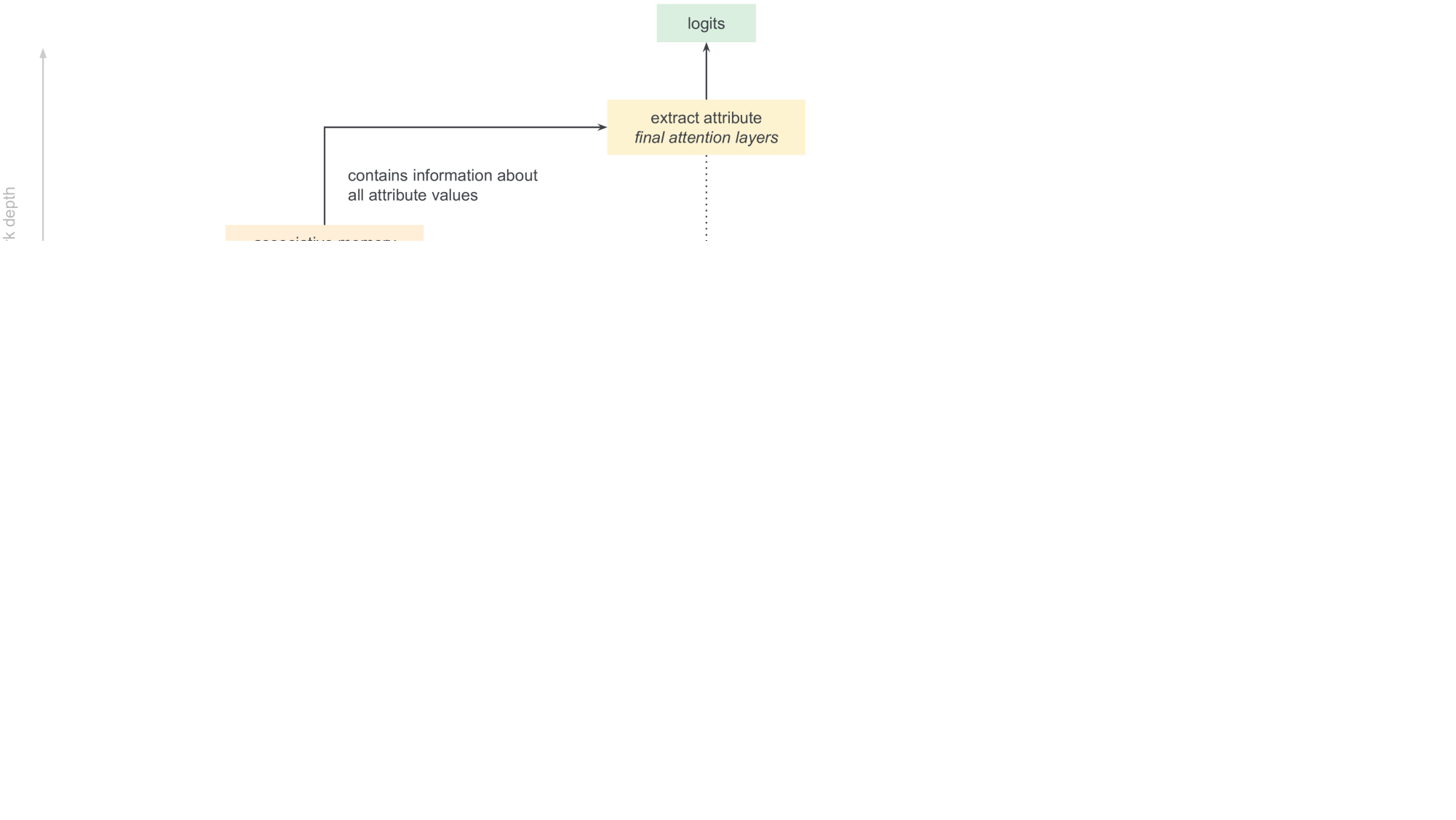
Attention patching results and attention map evolution.
Main Takeaways
- Models learn in three phases: (1) general statistics (reaching entropy baseline), (2) a plateau where loss is flat but attention circuits form, (3) rapid knowledge acquisition.
- Imbalanced data distributions shorten the plateau (faster circuit formation) but slow down the final acquisition of rare facts.
- Fine-tuning is ineffective for adding new knowledge because it corrupts existing memories (catastrophic forgetting in MLPs) and causes immediate hallucination.