📝 Paper Summary
Tabular Foundation Models (TFMs)
Synthetic Data Generation
Adversarial Training
RTFM improves tabular foundation models by adversarially optimizing the synthetic data generator to create datasets where the model currently underperforms relative to strong tree-based baselines.
Core Problem
Tabular Foundation Models are pretrained on synthetic data from fixed prior distributions, which underrepresent challenging regions of the parameter space, causing them to lag behind tree-based methods on some real-world tasks.
Why it matters:
- Fixed priors in data generation leave blind spots where TFMs fail to generalize to complex real-world structures.
- Deep learning methods still struggle to consistently beat gradient boosted trees (XGBoost, CatBoost) on structured data benchmarks.
Concrete Example:
A TFM trained on balanced synthetic data might fail on a real-world dataset with high class imbalance or specific categorical feature ratios because those conditions were rare in its training distribution, while XGBoost handles them robustly.
Key Novelty
Adversarial Training over the Data Generator Space (RTFM)
- Treats the parameters of the synthetic data generator (e.g., feature correlations, sparsity) as the adversarial space.
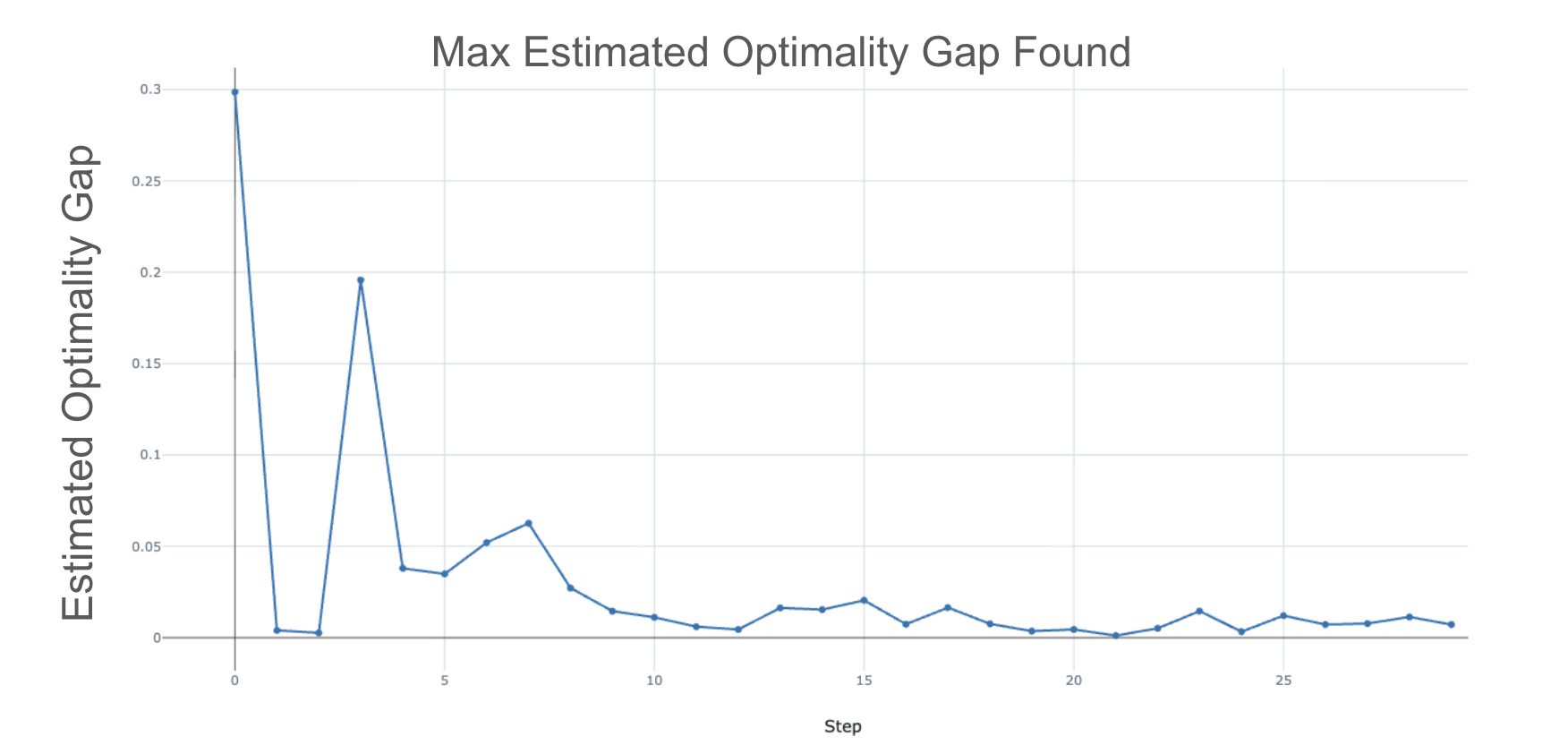
- Maximizes an 'optimality gap': the difference between the TFM's loss and the loss of strong baselines (like XGBoost) on generated data.
- Updates the sampling distribution to focus training on these 'hard' regions where the TFM is currently worse than traditional methods.
Architecture
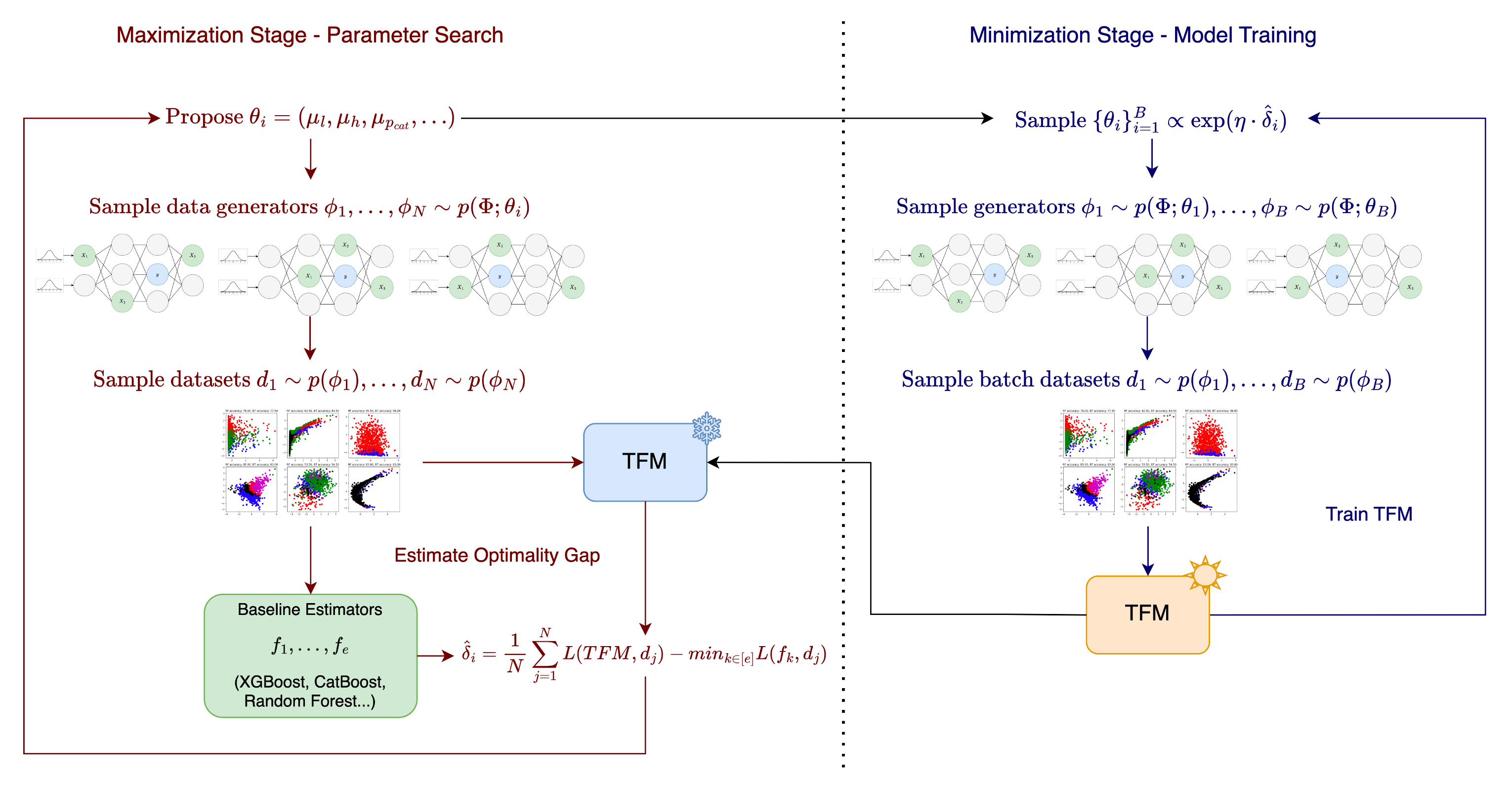
The two-stage RTFM optimization loop. Stage 1 (Maximization) searches for SCM parameters with high optimality gaps using baseline models. Stage 2 (Minimization) trains the TFM on datasets sampled from these hard parameter regions.
Evaluation Highlights
- +6% increase in mean normalized AUC over the original TabPFN V2 on TabArena and TabPertNet benchmarks.
- Achieves state-of-the-art ranking (Rank 1.9 on TabArena) compared to XGBoost (3.4) and CatBoost (2.2).
- Requires only <100k additional synthetic datasets for fine-tuning, a tiny fraction (~1%) of the original pretraining data.
Breakthrough Assessment
8/10
Offers a highly efficient, model-agnostic method to close the gap between deep learning and tree-based methods on tabular data using targeted synthetic data, demonstrating significant gains with minimal compute.