📝 Paper Summary
Multimodal Retrieval
Open-domain Question Answering
LILaC structures multimodal documents into a two-layer graph of coarse and fine components, using late interaction to accurately retrieve relevant subgraphs for complex queries without fine-tuning.
Core Problem
Current multimodal retrieval methods either lose visual information by converting everything to text (TextRAG) or retrieve fixed, coarse-grained screenshots (VisRAG) that include irrelevant noise and miss structural connections.
Why it matters:
- Fixed-granularity retrieval (e.g., full pages) dilutes the signal of small but crucial details needed for precise answers
- Independent retrieval of pages ignores explicit links and semantic relationships, failing at multihop reasoning required for complex open-domain questions
- Text-only conversion loses critical visual cues (e.g., specific objects in images) that are essential for answering visual queries
Concrete Example:
A query asks about 'minarets' around the Taj Mahal. A TextRAG summarizer might omit the word 'minarets,' causing retrieval failure. A VisRAG retriever pulls the whole page screenshot, where the relevant text is tiny compared to irrelevant content, diluting the embedding match. Furthermore, neither method connects the 'Taj Mahal' page to a 'Shah Jahan' page via hyperlinks to answer a multihop question about who built it.
Key Novelty
Layered Component Graph with Late Interaction (LILaC)
- Constructs a graph with two layers: a coarse layer (paragraphs, tables, images) for context and traversing links, and a fine layer (sentences, rows, objects) for precise matching
- Traverses this graph starting from coarse candidates, but scores edges dynamically by matching decomposed sub-queries against the fine-grained sub-components inside the nodes (late interaction)
Architecture
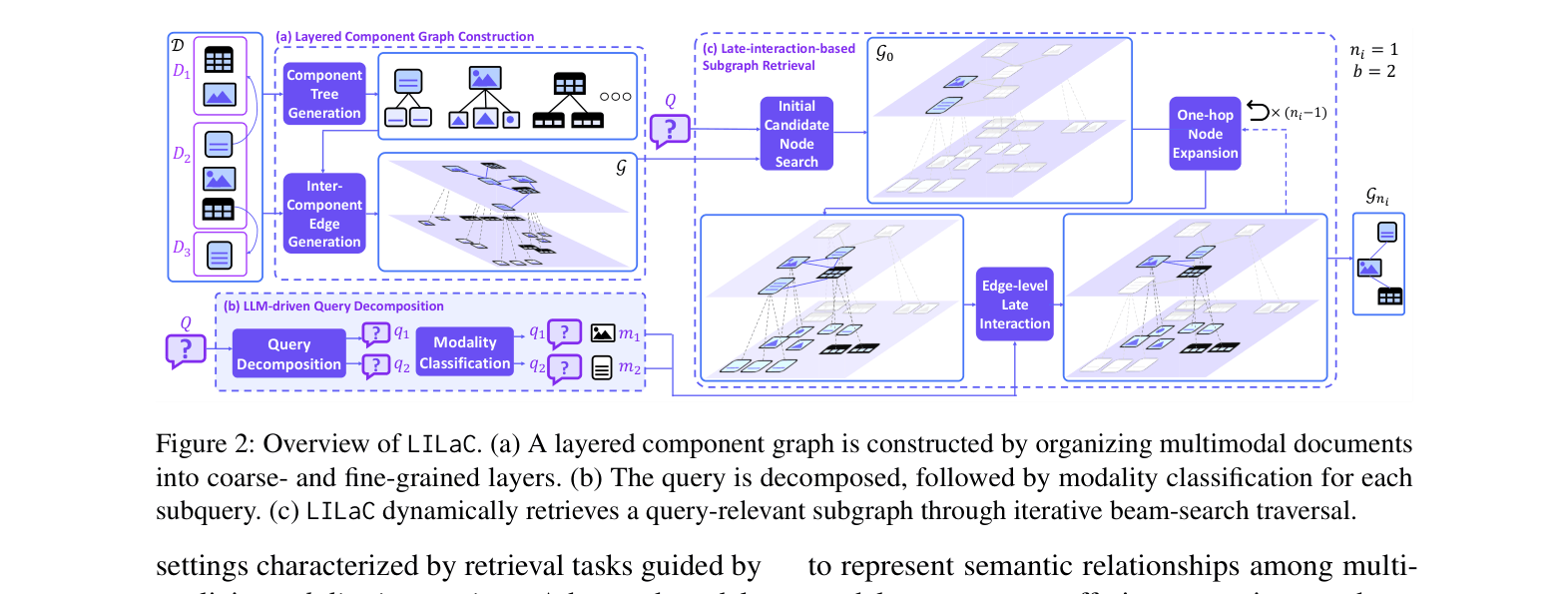
Overview of LILaC framework: (a) Graph Construction, (b) Query Decomposition, and (c) Late-interaction Retrieval
Evaluation Highlights
- Achieves state-of-the-art retrieval accuracy on 5 benchmarks, outperforming VisRAG by 15.75% and ColPali by 11.74% on average MRR@10
- Improves Recall@3 on multihop-heavy datasets (MultimodalQA) by ~60% compared to previous VisRAG approaches
- Attains SOTA end-to-end QA performance with 52.56% Exact Match average, surpassing the best VisRAG setup by over 18%
Breakthrough Assessment
9/10
Significantly outperforms SOTA (including ColPali) without any training, solving key granularity and multihop issues in multimodal RAG via a clever graph structure.