📊 Experiments & Results
Evaluation Setup
Zero-shot and few-shot evaluation on held-out tasks (MMLU, BBH, Reasoning, QA)
Benchmarks:
- MMLU (Multi-task knowledge (57 subjects))
- BBH (BIG-Bench Hard) (Challenging reasoning/logic tasks)
- Reasoning (GSM8K, SVAMP, ASDIV, StrategyQA) (Chain-of-Thought reasoning)
- QA (UnifiedQA, BoolQ, ARC) (Question Answering)
Metrics:
- Accuracy
- Exact Match
- Normalized Average (macro-average over normalized scores)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of the largest efficient MoE model (Flan-ST32B) against a larger dense model (Flan-PaLM62B) shows superior efficiency. | ||||
| MMLU (Few-shot) | Accuracy | 59.6 | 65.4 | +5.8 |
| BBH (Few-shot) | Accuracy | 49.1 | 54.4 | +5.3 |
| Impact of routing strategy on MMLU performance. | ||||
| MMLU-Direct | Accuracy | 38.0 | 39.9 | +1.9 |
| Quantifying the boost from instruction tuning specifically for MoE models vs Dense models. | ||||
| Aggregated Benchmarks | Relative Improvement | 0.0 | 45.2 | +45.2 |
Experiment Figures
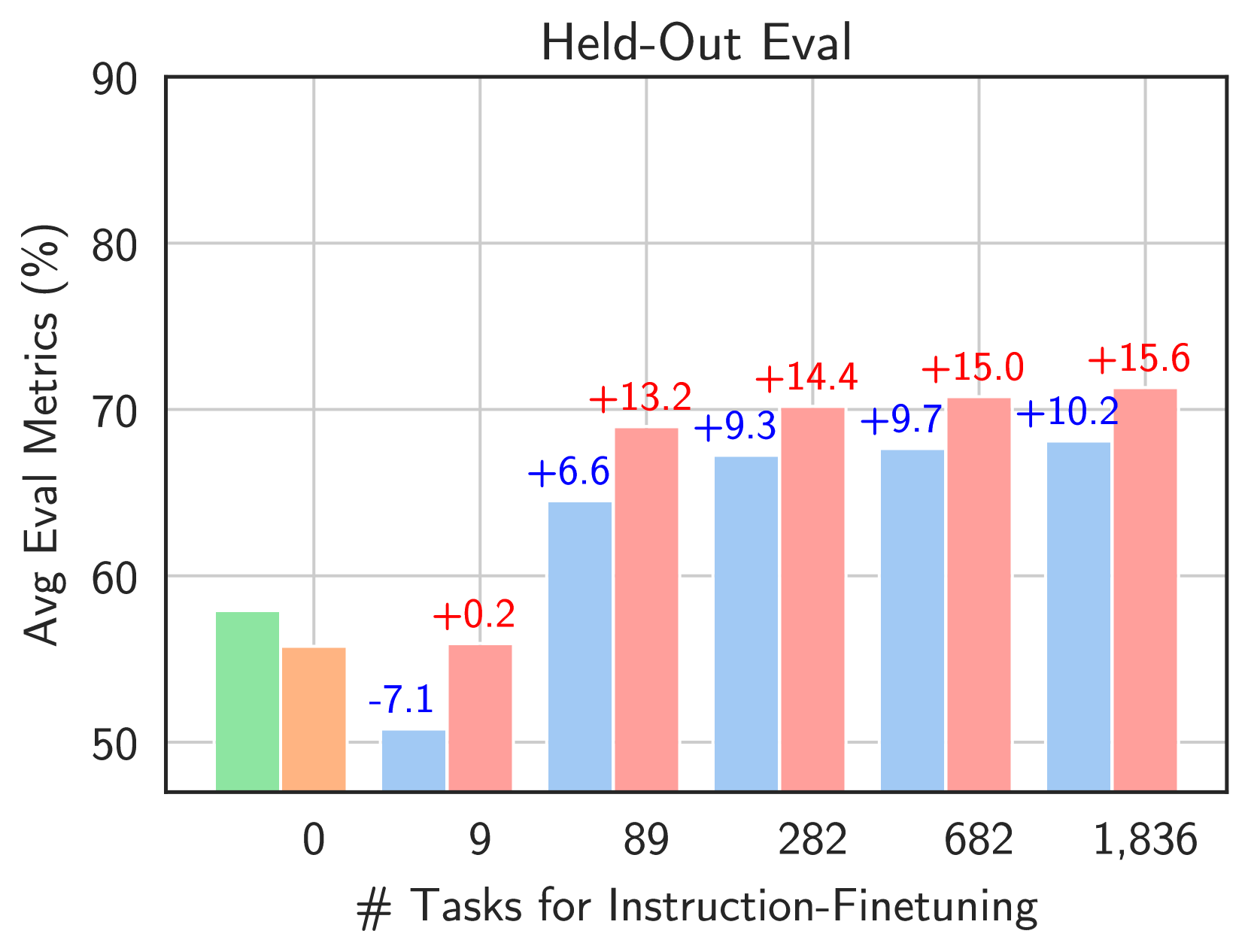
Performance vs. FLOPs (Computational Cost) for Flan-MoE vs Dense models.

Performance vs. Number of Experts.
Main Takeaways
- MoE models benefit significantly more from instruction tuning than dense models; without it, they often underperform dense baselines.
- Flan-MoE achieves a better cost-performance trade-off (Pareto frontier) than dense Flan-T5 models across all scales (small to xxl).
- Expert-choice routing (Flan-EC) consistently outperforms token-choice routing (Flan-GS/Switch) across scales.
- Increasing the number of experts improves performance initially but saturates; massive scaling of experts alone is not infinite.