📊 Experiments & Results
Evaluation Setup
Zero-shot and Few-shot evaluation on standard NLP benchmarks
Benchmarks:
- Common Sense Reasoning (Multiple Choice (BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC, OpenBookQA))
- Closed-book QA (Exact Match generation (Natural Questions, TriviaQA))
- Reading Comprehension (QA (RACE))
- Mathematical Reasoning (Generation (MATH, GSM8k))
- Code Generation (Programming (HumanEval, MBPP))
- MMLU (5-shot Knowledge)
Metrics:
- Accuracy
- Exact Match (EM)
- Pass@1
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Common Sense Reasoning results demonstrate LLaMA-65B competing with Chinchilla and PaLM, and LLaMA-13B outperforming GPT-3. | ||||
| HellaSwag | Accuracy | 78.9 | 79.2 | +0.3 |
| HellaSwag | Accuracy | 80.8 | 84.2 | +3.4 |
| BoolQ | Accuracy | 60.5 | 78.1 | +17.6 |
| Closed-book QA results show LLaMA-65B achieving state-of-the-art performance. | ||||
| NaturalQuestions | Exact Match | 21.2 | 23.8 | +2.6 |
| TriviaQA | Exact Match | 55.4 | 68.2 | +12.8 |
| Results on MMLU show LLaMA-65B lagging slightly behind Chinchilla and PaLM, likely due to data mix. | ||||
| MMLU | Average Accuracy | 67.5 | 63.4 | -4.1 |
| Code generation results show LLaMA outperforming PaLM on comparable sizes. | ||||
| HumanEval | pass@1 | 15.9 | 23.7 | +7.8 |
Experiment Figures
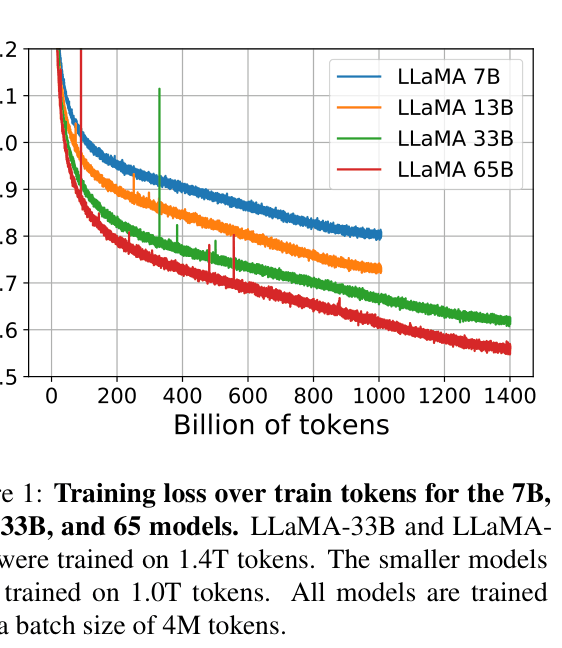
Training loss curves over tokens for 7B, 13B, 33B, and 65B models
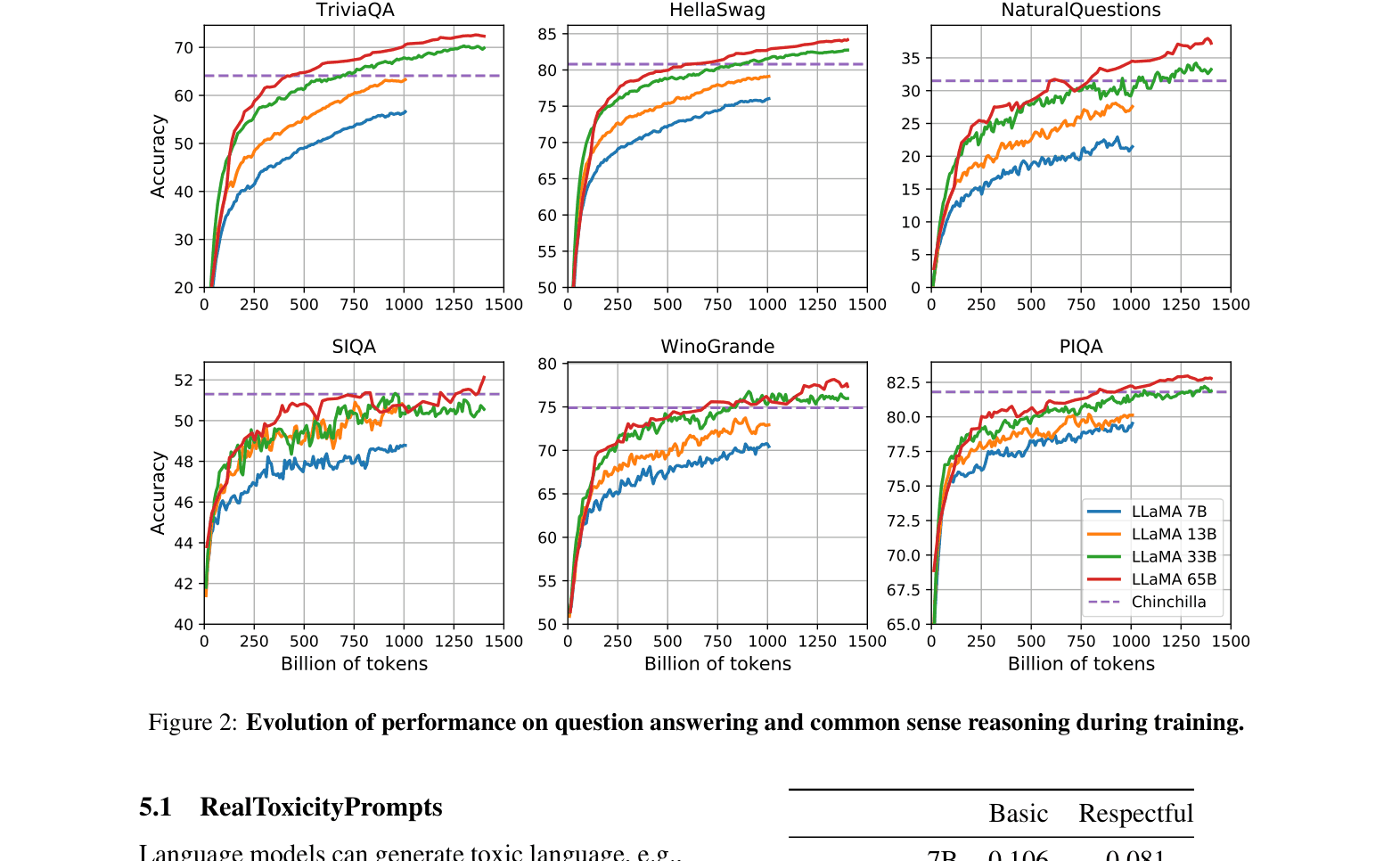
Evolution of downstream task performance (TriviaQA, HellaSwag, NQ, SIQA) during training
Main Takeaways
- Performance of the 7B model continues to improve even after 1T tokens, contradicting Chinchilla scaling laws which suggest stopping earlier for optimal training efficiency
- LLaMA-13B is a highly efficient model that outperforms GPT-3 (175B) on most benchmarks while running on a single V100 GPU
- Using only publicly available data is sufficient to train state-of-the-art foundation models, removing the need for proprietary datasets
- Brief instruction fine-tuning (LLaMA-I) significantly improves MMLU performance (63.4 -> 68.9 on 65B model)