📊 Experiments & Results
Evaluation Setup
Comprehensive benchmark sweep across General, Code, Math, Reasoning, Tool Use, and Long Context tasks
Benchmarks:
- MMLU (General Knowledge (5-shot))
- GSM8K (Math Reasoning (8-shot, CoT))
- HumanEval (Python Coding (0-shot))
- ARC Challenge (Reasoning (0-shot))
Metrics:
- Accuracy
- Pass@1
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| The flagship Llama 3 405B model competes directly with top-tier proprietary models like GPT-4 and GPT-4o. | ||||
| MMLU (5-shot) | Accuracy | 85.4 | 88.6 | +3.2 |
| GSM8K (8-shot, CoT) | Accuracy | 94.2 | 96.8 | +2.6 |
| HumanEval (0-shot) | Pass@1 | 86.6 | 89.0 | +2.4 |
| ARC Challenge (0-shot) | Accuracy | 96.4 | 96.9 | +0.5 |
| Llama 3 70B significantly outperforms open-weights models in its size class. | ||||
| MMLU (5-shot) | Accuracy | 76.9 | 83.6 | +6.7 |
| HumanEval (0-shot) | Pass@1 | 75.6 | 80.5 | +4.9 |
Experiment Figures
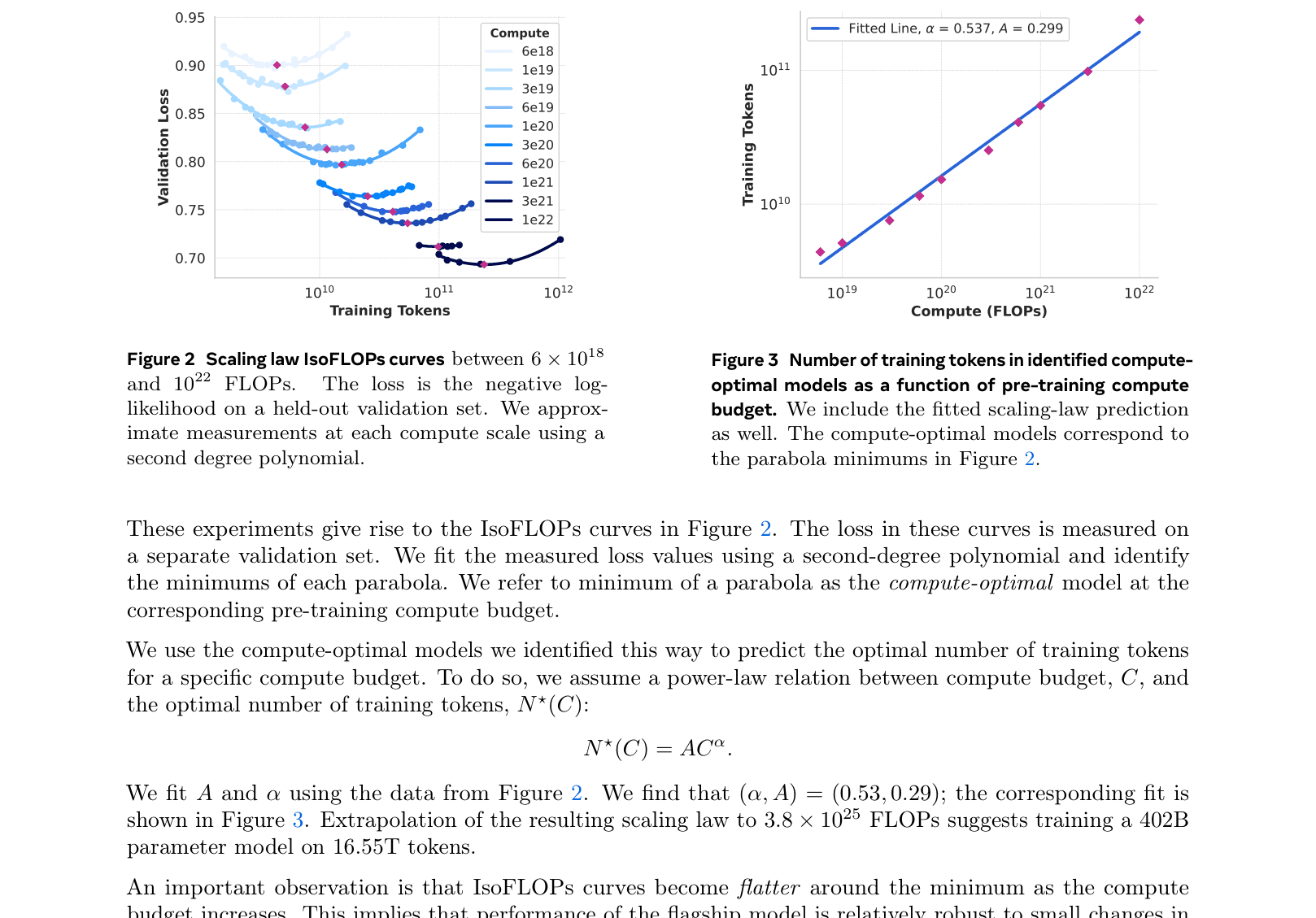
Scaling law IsoFLOPs curves
Main Takeaways
- Scaling laws hold: The 405B model, trained on 15T+ tokens, delivers state-of-the-art performance, validating the 'compute-optimal' approach adjusted for inference budget
- High-quality data is critical: Heavy curation, de-duplication, and synthetic data (annealing) were key to performance gains over Llama 2
- Simple architecture wins: Standard dense Transformers with minor tweaks (GQA, RoPE) are sufficient for SOTA results if scaled properly; MoE is not strictly necessary for quality, though it helps inference cost
- Multimodal composition works: Adding vision and speech via adapters to a frozen language model yields competitive performance without training a multimodal model from scratch (though these models are unreleased)