📝 Paper Summary
Distributed Language Model Training
Data Privacy and Sovereignty
Mixture-of-Experts (MoE)
FlexOlmo enables training language models on distributed, private datasets without sharing data by independently training expert modules anchored to a public model and merging them into a Mixture-of-Experts architecture.
Core Problem
Standard LM training requires centralized data pooling, which is impossible for organizations with regulatory/privacy restrictions (HIPAA, GDPR), and offers no mechanism to cleanly remove specific data influences after training.
Why it matters:
- Organizations in healthcare and finance possess valuable data they cannot share due to regulations (HIPAA, GDPR) or IP protection
- Current federated learning approaches suffer from high synchronization costs and performance degradation
- Model developers currently make irreversible one-time decisions on data inclusion, limiting adaptability to changing copyright or consent laws
Concrete Example:
A healthcare institution wants to improve a general LM with patient records but cannot send data to a central server. Currently, they cannot contribute. With FlexOlmo, they train a local expert module that plugs into the central model without raw data ever leaving their premise.
Key Novelty
Coordinated Independent Expert Training
- Trains expert modules on private data independently while keeping a shared public model frozen as an anchor to force coordination
- Learns router representations solely from local data domains without joint training, enabling 'plug-and-play' merging of experts
- Uses a domain-informed routing mechanism where experts compete against the public model during training but against each other during inference
Architecture
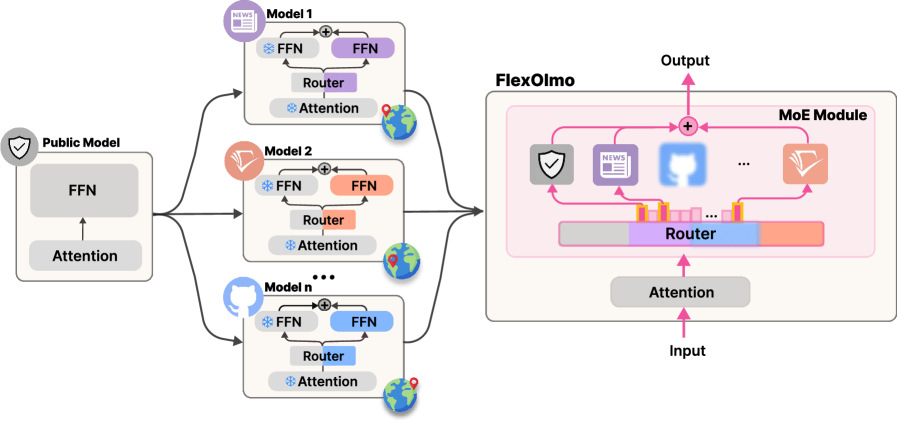
Overview of FlexOlmo training and inference. Left: Independent training where each data owner trains an expert + router embedding relative to a frozen public model. Right: Inference where experts are merged into a single MoE.
Evaluation Highlights
- +41% relative improvement over the public seed model when combining a general expert with independently trained experts from other data owners
- Outperforms prior model merging methods (model soup, ensembling) by 10.1% on average across 31 downstream tasks
- Achieves performance surpassing a standard MoE trained jointly without data restrictions (oracle baseline) using equivalent training FLOPs
Breakthrough Assessment
8/10
Strong conceptual breakthrough for privacy-preserving collaborative AI. Successfully decouples training from data centralization while maintaining or exceeding the performance of centralized baselines.