📝 Paper Summary
LLM Benchmarking
Reasoning Evaluation
HLE is a new, expert-curated multi-modal benchmark designed to be the final closed-ended academic exam for LLMs, containing problems that currently stump frontier models.
Core Problem
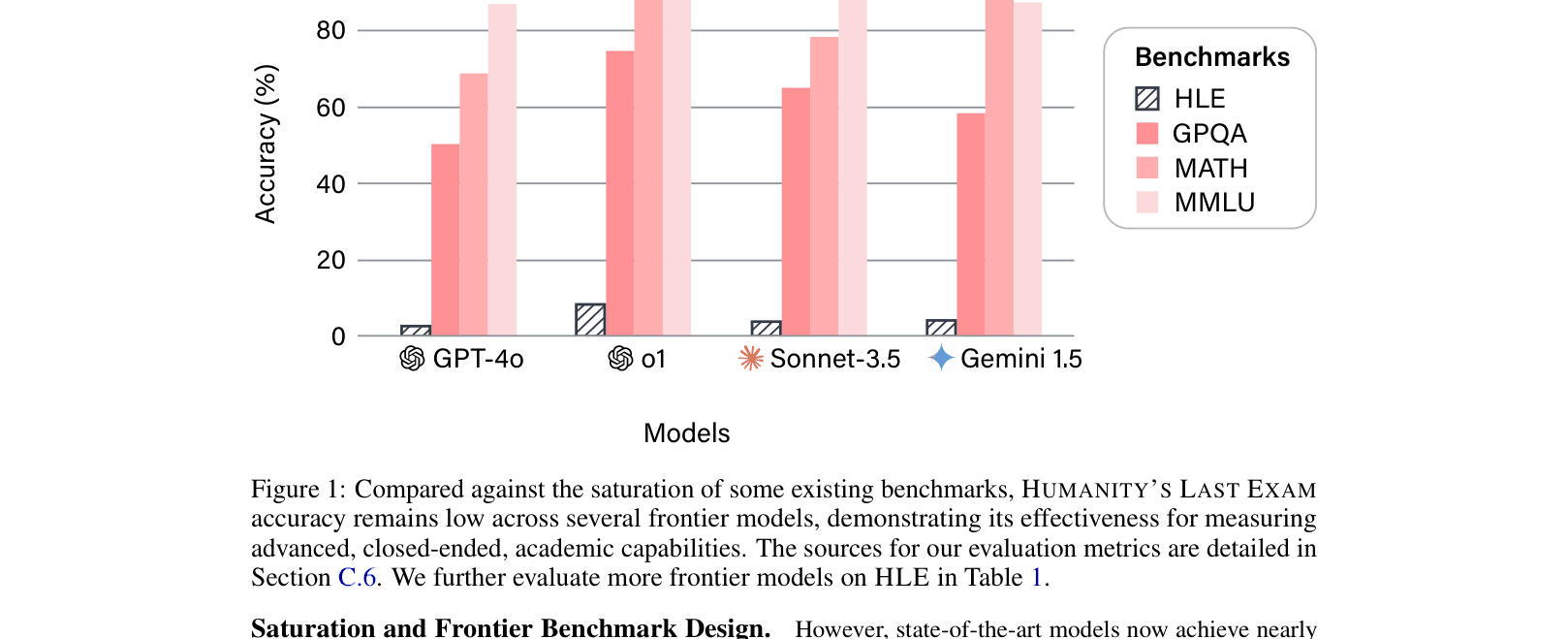
Existing academic benchmarks like MMLU are saturated, with LLMs achieving >90% accuracy, making it impossible to distinguish capabilities at the frontier of human knowledge.
Why it matters:
- Saturation obscures the true gap between AI and expert human capabilities, hindering informed research and policy decisions.
- Current benchmarks often rely on retrievable information rather than deep reasoning, allowing models to memorize answers rather than solve problems.
Concrete Example:
Frontier models achieve near-perfect scores on MMLU, yet fail on HLE questions like translating Palmyrene script or solving specific chemical reaction cascades (see Figure 2), showing they lack true expert proficiency.
Key Novelty
Expert-Sourced Frontier Hardness
- Filters questions via a 'negative check' against current LLMs: only questions that state-of-the-art models fail to answer are accepted.
- Crowdsources content from ~1,000 subject-matter experts (mostly PhDs/graduates) rather than generic annotators to ensure depth and precision.
Architecture

The dataset creation pipeline from submission to release.
Evaluation Highlights
- Current state-of-the-art models (including o3-mini and DeepSeek-R1) achieve <15% accuracy on HLE, compared to >90% on MMLU.
- Models exhibit severe overconfidence, with RMS calibration errors >70%, indicating they do not know when they are hallucinating answers to hard questions.
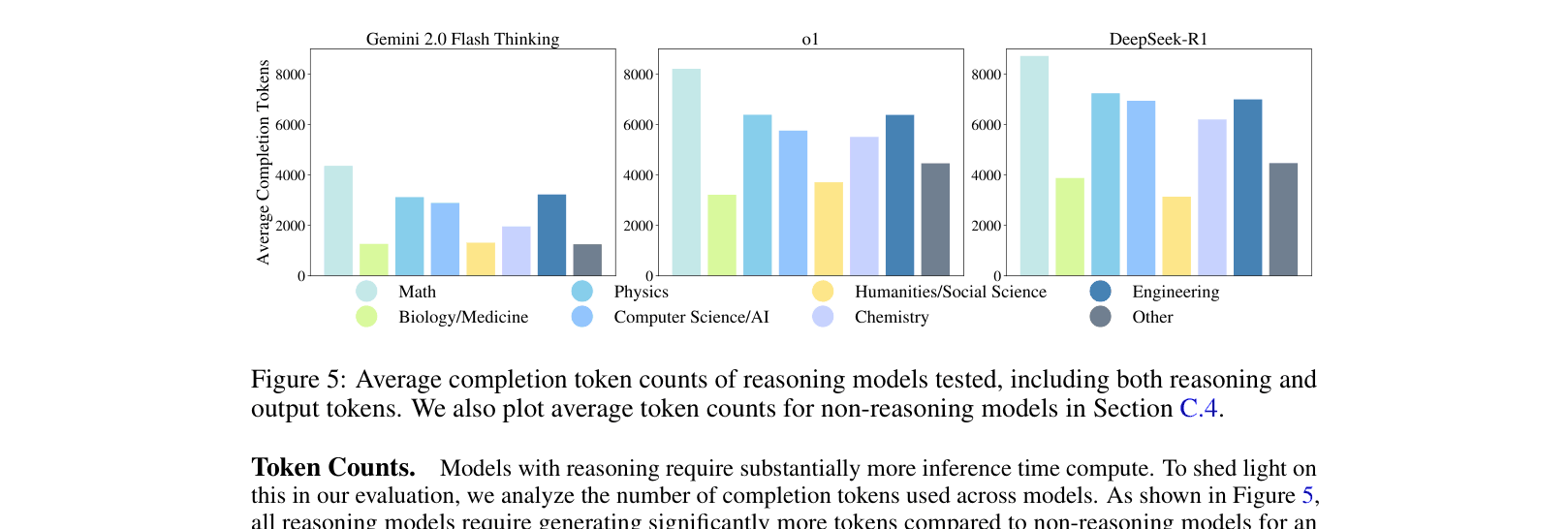
- Reasoning models like o1 require significantly more tokens to achieve marginal accuracy gains over non-reasoning models.
Breakthrough Assessment
9/10
Sets a new standard for difficulty in LLM evaluation, effectively uncapping the measurement scale just as MMLU becomes obsolete. Likely to be the primary target for next-gen models.