📝 Paper Summary
Vision-Language Pre-training
Multimodal Few-Shot Learning
Prompt Tuning
Frozen enables large language models to perform multimodal tasks by learning a vision encoder that translates images into continuous embeddings the frozen LLM can interpret as text prompts.
Core Problem
Large language models are powerful few-shot learners but are blind to visual modalities, while existing multimodal models are typically specialized for single tasks and lack rapid adaptation capabilities.
Why it matters:
- Philosophical limitations: Ungrounded language models may lack true understanding of the language they process
- Practical limitations: Users cannot communicate visual concepts or questions to standard LLMs
- Efficiency gap: Existing multimodal methods require fine-tuning the full model for each new task, losing the few-shot flexibility of pure LLMs
Concrete Example:
When an LLM is asked 'Who invented this?' about an image of a plane, it fails because it cannot see. Frozen converts the plane image into embedding vectors that look like 'words' to the LLM, triggering it to retrieve the fact 'The Wright brothers' from its frozen text knowledge.
Key Novelty
Frozen: Visual Prefix Tuning for Frozen LLMs
- Treat images as continuous 'words': A vision encoder is trained to output vectors that align with the pre-trained LLM's word embedding space
- Keep the brain frozen: The massive language model's weights remain unchanged, preserving its encyclopedic knowledge and few-shot reasoning abilities
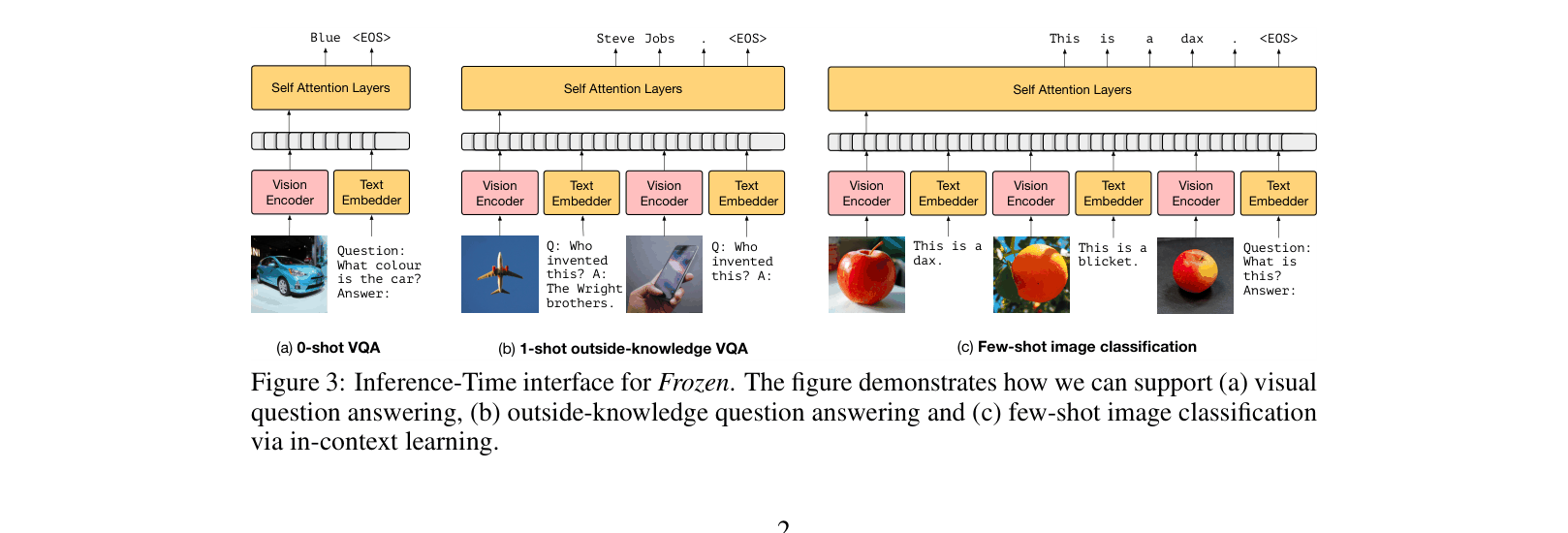
- Interleaved prompting: The system can process sequences of multiple images and text strings in any order, enabling 'in-context' learning where the model sees examples before being tested
Architecture
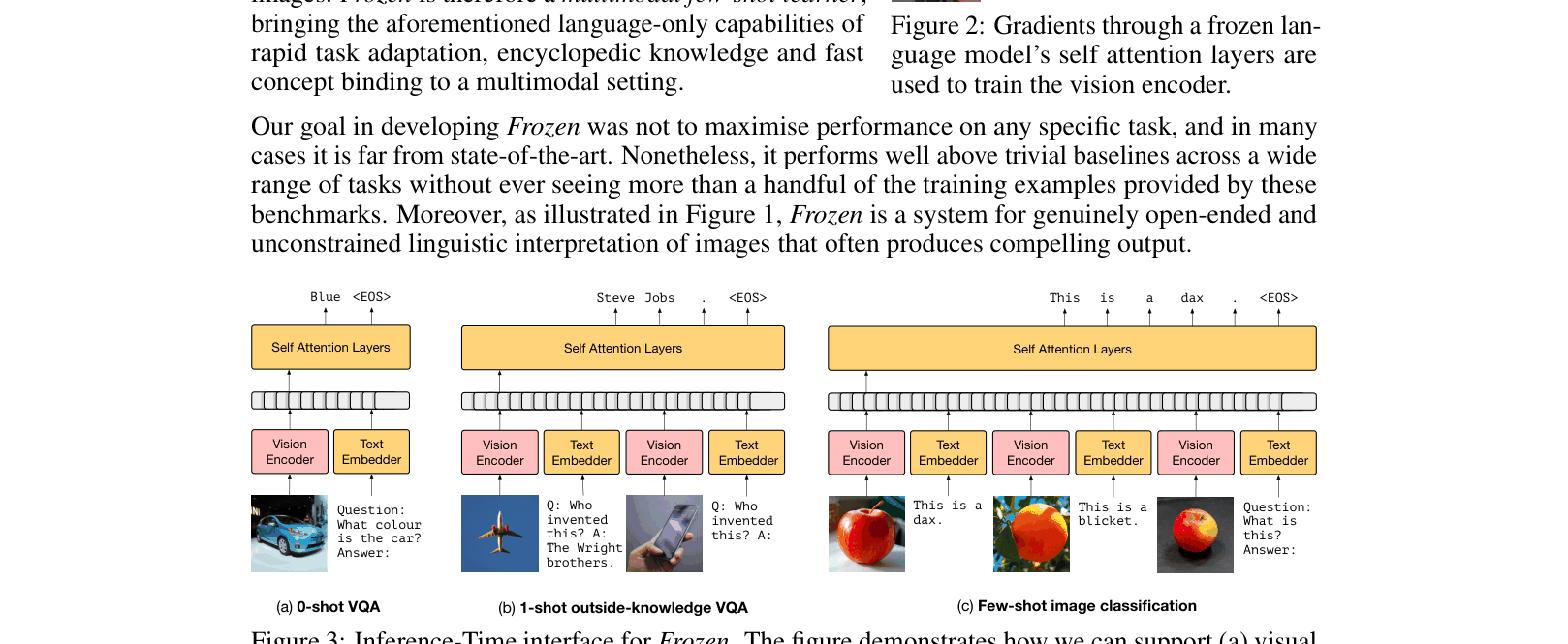
Training diagram showing the Vision Encoder being updated via gradients backpropagated through the Frozen Language Model's self-attention layers.
Evaluation Highlights
- Achieves 38.2% accuracy on VQAv2 with just 4 examples (4-shot), significantly closing the gap between zero-shot (29.5%) and full supervision (48.4%)
- Demonstrates 'fast binding' on Open-Ended miniImageNet (2-way), improving from ~29% (1-shot) to 58.9% (5-shot) by learning new nonsense words for visual categories in-context
- Outperforms fine-tuning baselines on outside-knowledge tasks: 5.9% zero-shot on OKVQA vs 4.2% for a fine-tuned version, showing frozen weights preserve factual knowledge better
Breakthrough Assessment
9/10
Seminal work establishing the paradigm of multimodal few-shot learning via frozen LLMs. It proved that vision can be mapped to LLM input space effectively, influencing major successors like Flamingo and GPT-4V.