📝 Paper Summary
Deep Learning Recommendation Systems (DLRS)
Click-Through Rate (CTR) Prediction
Scaling Laws
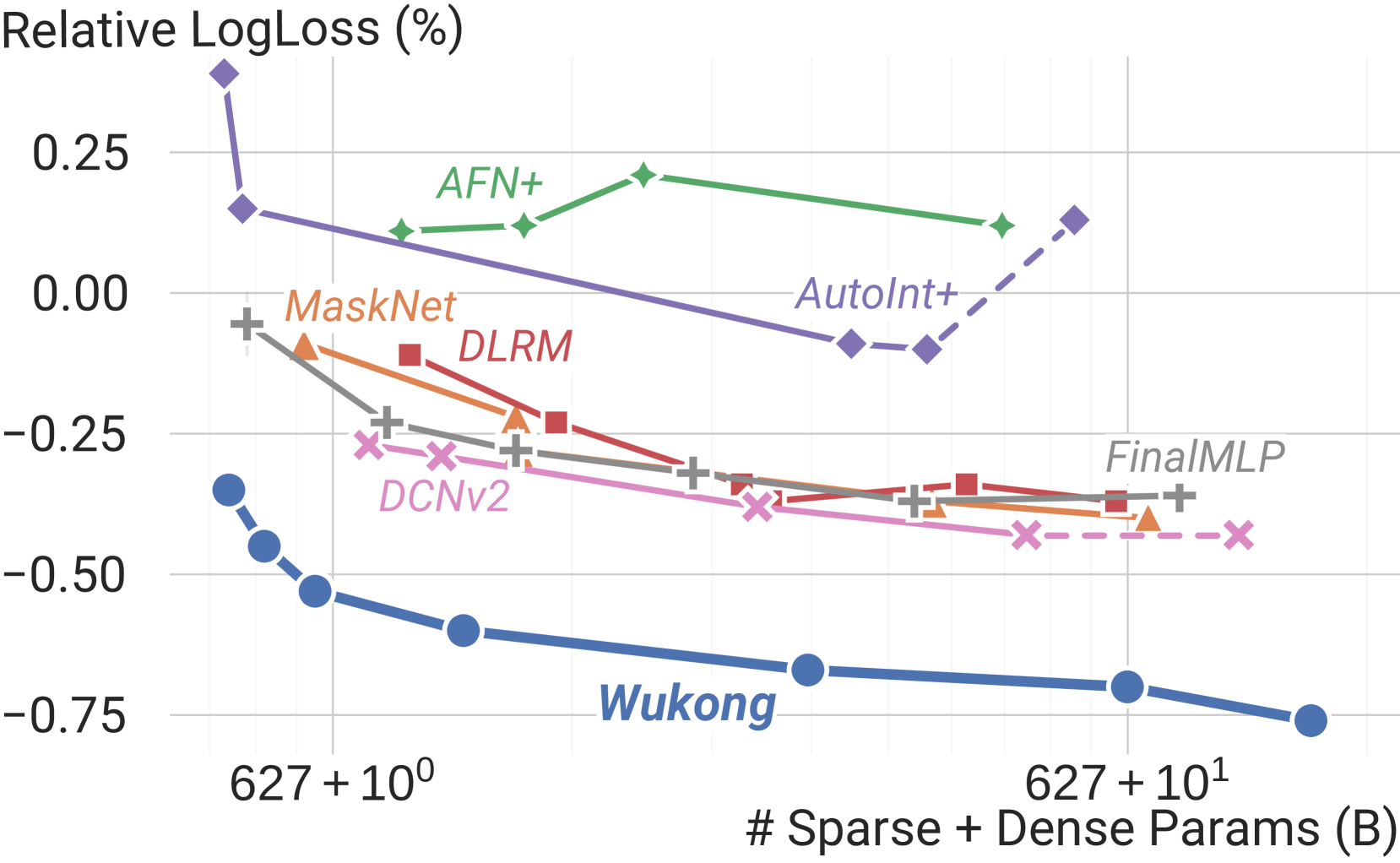
Wukong establishes a scaling law for recommendation systems by replacing standard embedding-table scaling with a stacked Factorization Machine architecture that captures any-order interactions through deeper and wider layers.
Core Problem
Current recommendation models rely on 'sparse scaling' (expanding embedding tables) to improve quality, which fails to capture complex feature interactions and cannot efficiently utilize modern hardware compute capacity.
Why it matters:
- Sparse scaling leads to massive parameter counts (trillions) dominated by memory-bound embedding tables, causing prohibitive infrastructure costs
- Existing interaction architectures (DLRM, DCNv2) lack effective mechanisms for 'dense scaling' (adding compute/layers), showing diminishing returns or instability when scaled up
- Modern hardware accelerators improve primarily in compute capacity, which embedding lookups cannot utilize effectively
Concrete Example:
DLRM captures only 2nd-order interactions and cannot scale depth effectively. When scaling up complexity beyond 100 GFLOP/example, prior arts fall short in quality improvements, whereas Wukong continues to improve.
Key Novelty
Stacked Factorization Machines (Wukong)
- Uses a multi-layer stack where each layer contains a Factorization Machine Block (FMB) and a Linear Compression Block (LCB), conceptually inspired by binary exponentiation
- By stacking FMs, the system captures exponentially higher-order interactions (layer i captures orders 1 to 2^i) without the computational cost of explicit high-order tensor products
- Replaces the standard 'dot product then MLP' paradigm with a recursive interaction structure where embeddings are updated layer-by-layer
Architecture
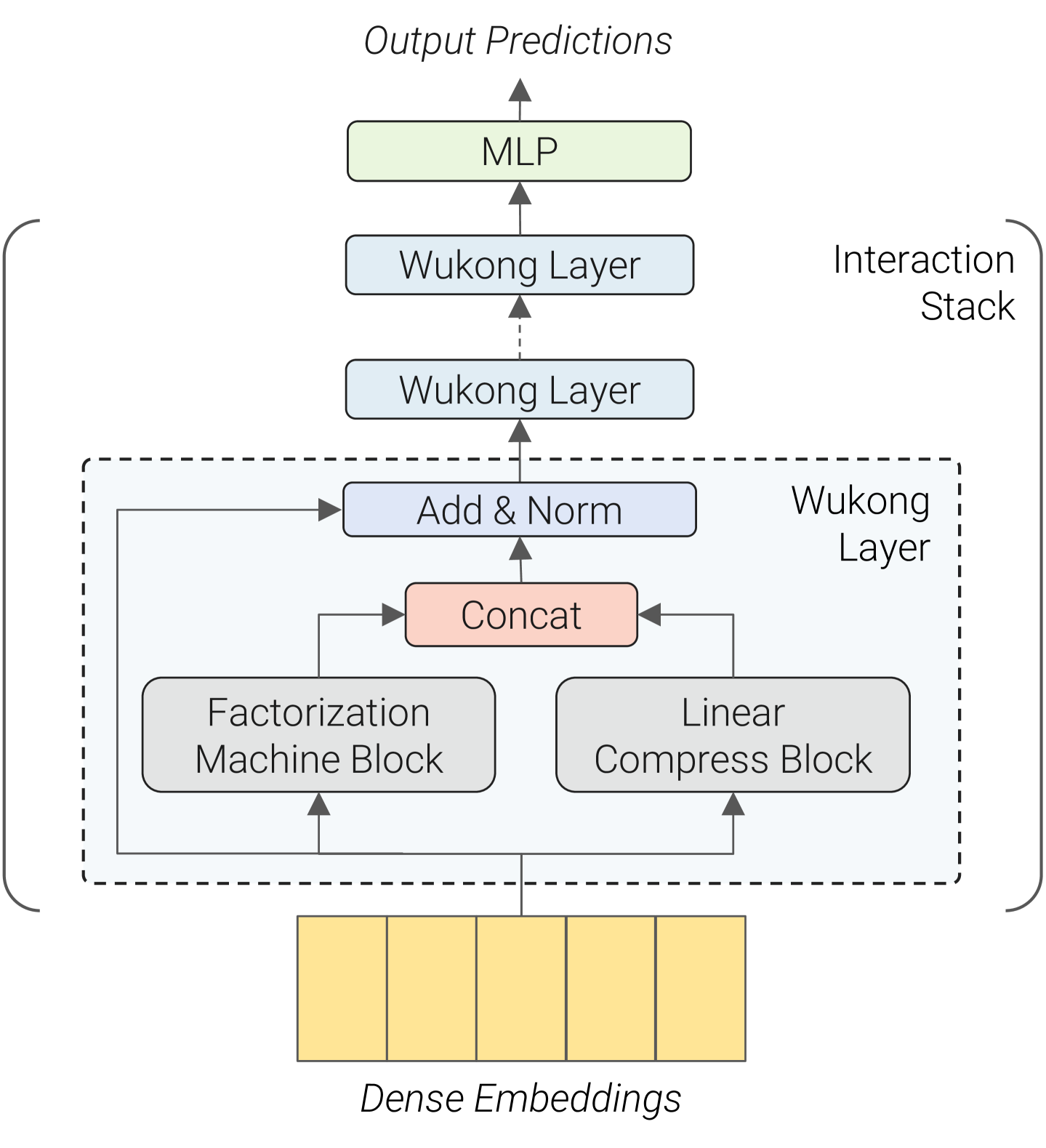
The complete Wukong architecture, detailing the Embedding Layer, Interaction Stack, and internal structure of the Interaction Layer (FMB + LCB).
Evaluation Highlights
- Outperforms state-of-the-art models (DCNv2, FinalMLP, MaskNet) across all six public datasets in terms of AUC
- Scales effectively on a large-scale internal dataset up to >100 GFLOP/example, maintaining quality gains where baselines saturate or degrade
- Reduces interaction complexity from O(n^2) to O(nk) using a low-rank optimized FM formulation
Breakthrough Assessment
8/10
Significant architectural shift from sparse to dense scaling in recommendation systems. Successfully demonstrates scaling laws in a domain where they have been elusive, addressing a major industry bottleneck.