📝 Paper Summary
Industrial Recommender Systems
Sequence Modeling
LONGER enables efficient end-to-end modeling of user behavior sequences up to length 10,000 in industrial recommenders by combining token merging, hybrid attention, and system-level optimizations.
Core Problem
Modeling ultra-long user sequences (length > 1,000) is computationally prohibitive with standard Transformers due to quadratic complexity, forcing systems to use lossy two-stage retrieval or pre-trained embeddings.
Why it matters:
- Ultra-long sequences capture crucial long-term interests, improving accuracy and diversity while mitigating information cocoons in recommender systems.
- Current industrial practices (two-stage retrieval) create upstream-downstream inconsistency, sacrificing raw information fidelity.
- Scaling laws suggest significant performance gains from longer contexts, but hardware constraints prevent direct application of vanilla architectures.
Concrete Example:
A user might have clicked a niche item 5,000 interactions ago that is highly relevant to a current candidate. A standard retrieval system selecting only the top-100 recent items would miss this signal, while a full Transformer would run out of GPU memory processing the full history.
Key Novelty
GPU-Efficient End-to-End Long Sequence Modeling
- Token Merge: Compresses adjacent tokens into groups using a lightweight inner-transformer to reduce sequence length while preserving local details.
- Hybrid Attention: Uses a cross-attention layer to select relevant history followed by self-attention on compressed sequences, drastically reducing computational cost.
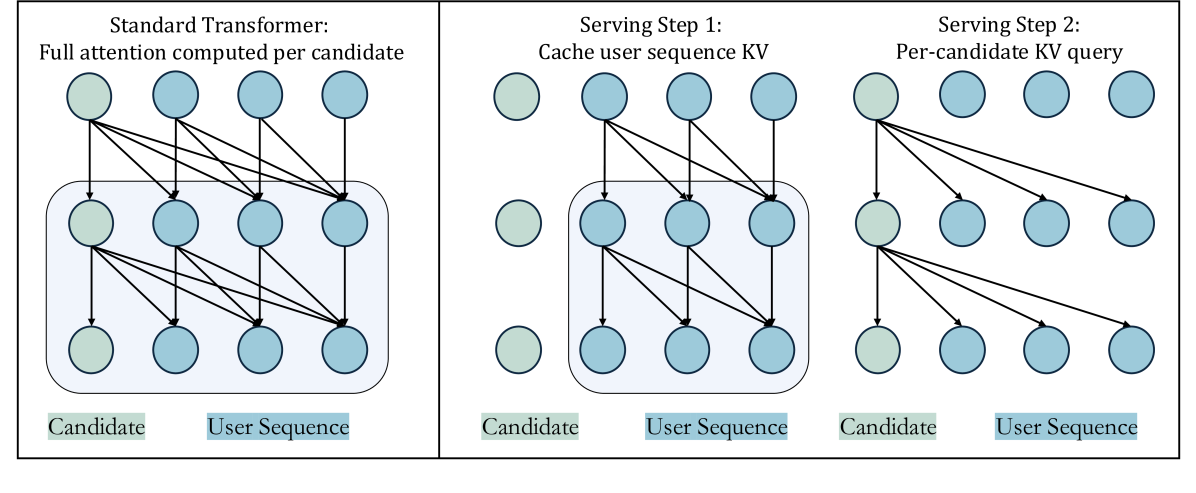
- System Optimizations: Deploys KV caching to reuse user sequence computations across candidate items, plus mixed-precision training to handle massive scale.
Architecture
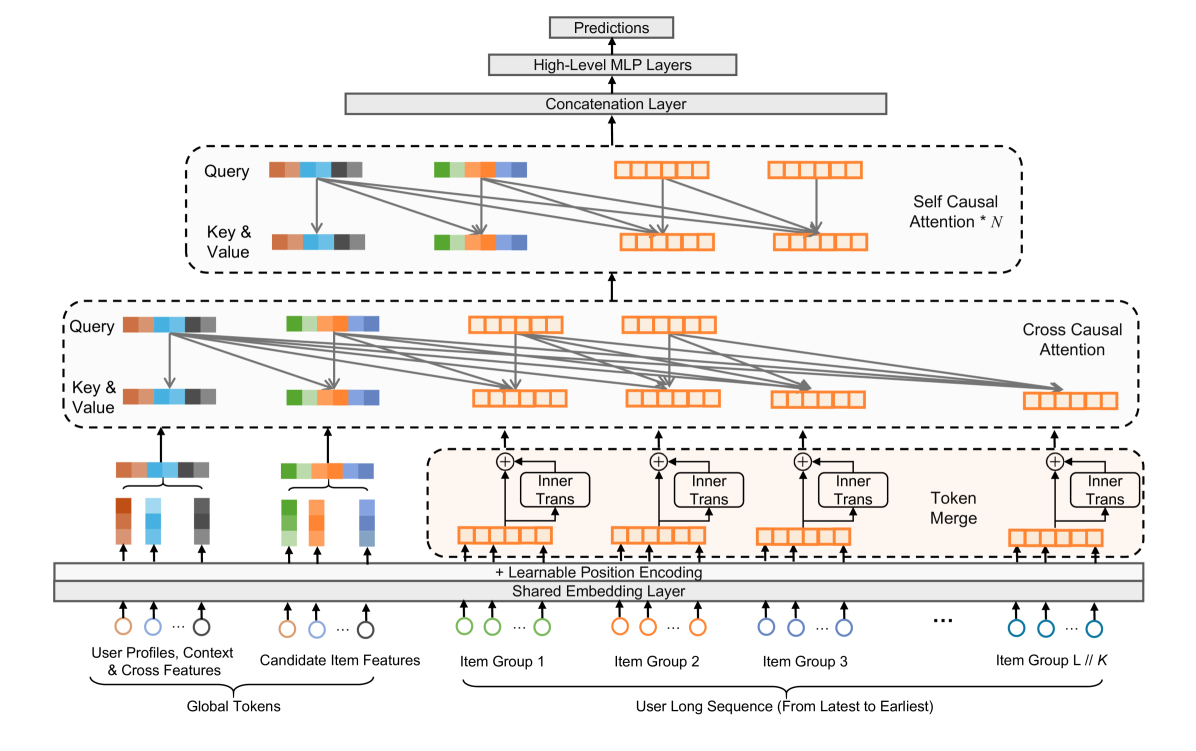
The overall architecture of LONGER, illustrating the data flow from input to prediction.
Evaluation Highlights
- Reduces FLOPs by ~42.8% compared to vanilla Transformers while maintaining model performance through token merging.
- KV Cache Serving optimization reduces online throughput degradation from -40% to only -6.8% when scaling sequence length.
- Successfully deployed in dozens of scenarios at ByteDance (including Douyin), scaling user sequences to length 10,000 in production.
Breakthrough Assessment
8/10
Significant industrial contribution. Successfully scales end-to-end long-sequence modeling (10k length) to billion-user production, solving major efficiency bottlenecks that previously forced suboptimal two-stage approaches.