📝 Paper Summary
LLM-based recommendation
Content-based recommendation
ONCE combines open-source LLMs (fine-tuned as content encoders) and closed-source LLMs (prompted as data augmenters) to significantly enhance content-based recommendation systems.
Core Problem
Existing content-based recommenders using CNNs or small PLMs (like BERT) fail to fully comprehend deep semantic content or capture knowledge about rare entities, limiting recommendation quality.
Why it matters:
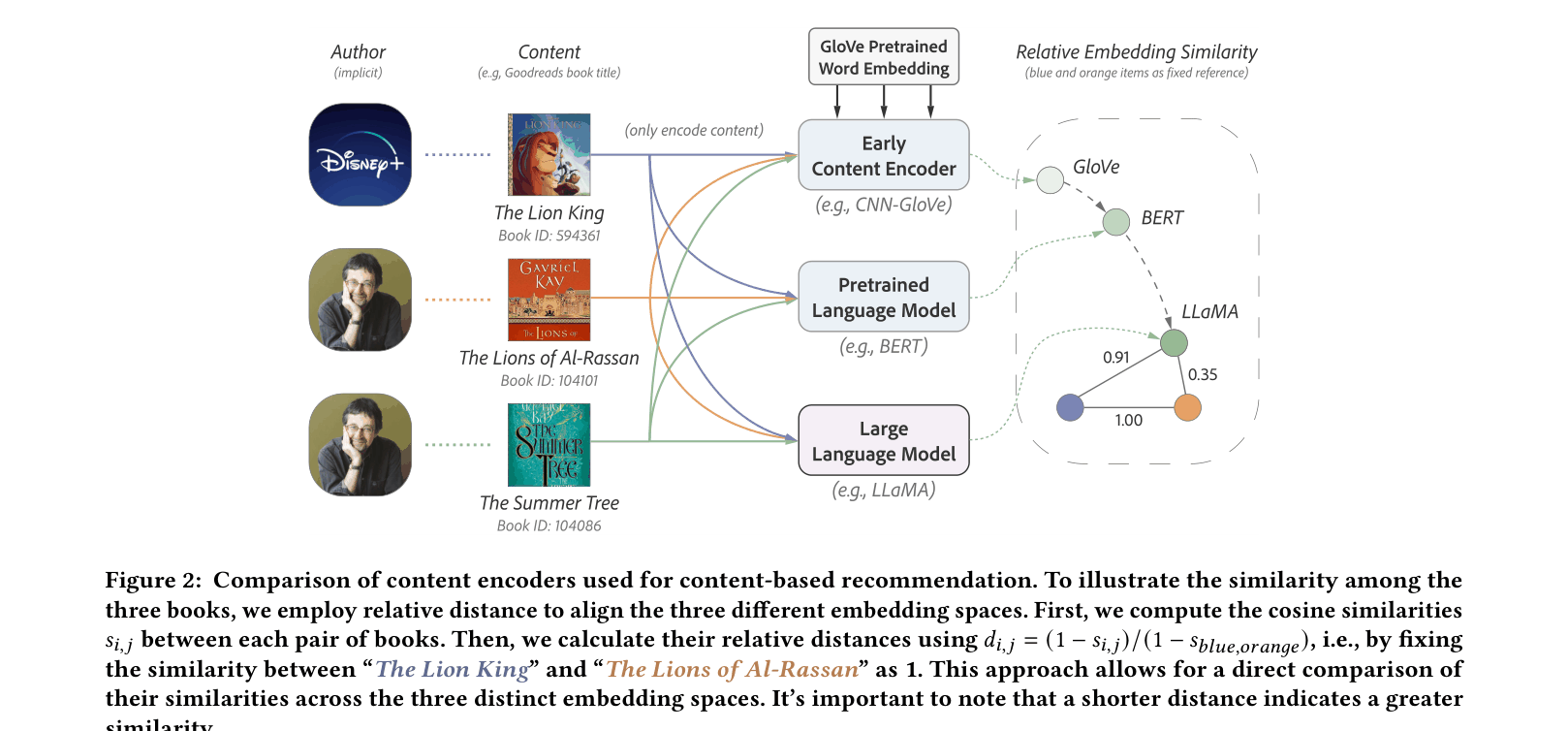
- Current encoders struggle with word-level ambiguity (e.g., confusing 'Lion King' with 'Lions of Al-Rassan') and lack the external knowledge needed for accurate semantic matching
- Purely prompting closed-source LLMs often underperforms traditional methods due to latency and lack of fine-grained signal, while open-source models are rarely optimized for recommendation tasks
Concrete Example:
Standard encoders incorrectly rate 'The Lion King' (Disney movie) and 'The Lions of Al-Rassan' (historical fantasy) as highly similar due to word overlap. In contrast, LLaMA correctly identifies that 'The Lions of Al-Rassan' is semantically closer to 'The Summer Tree' (same author, genre).
Key Novelty
Hybrid Open-Closed LLM Synergy (ONCE)
- DIRE (Discriminative Recommendation): Replaces traditional content encoders with open-source LLMs (LLaMA), fine-tuning their upper layers to produce dense embeddings optimized for recommendation
- GENRE (Generative Recommendation): Uses closed-source LLMs (GPT-3.5) to generate synthetic user profiles, summaries, and personalized content, enriching the training data for the discriminative model
Architecture
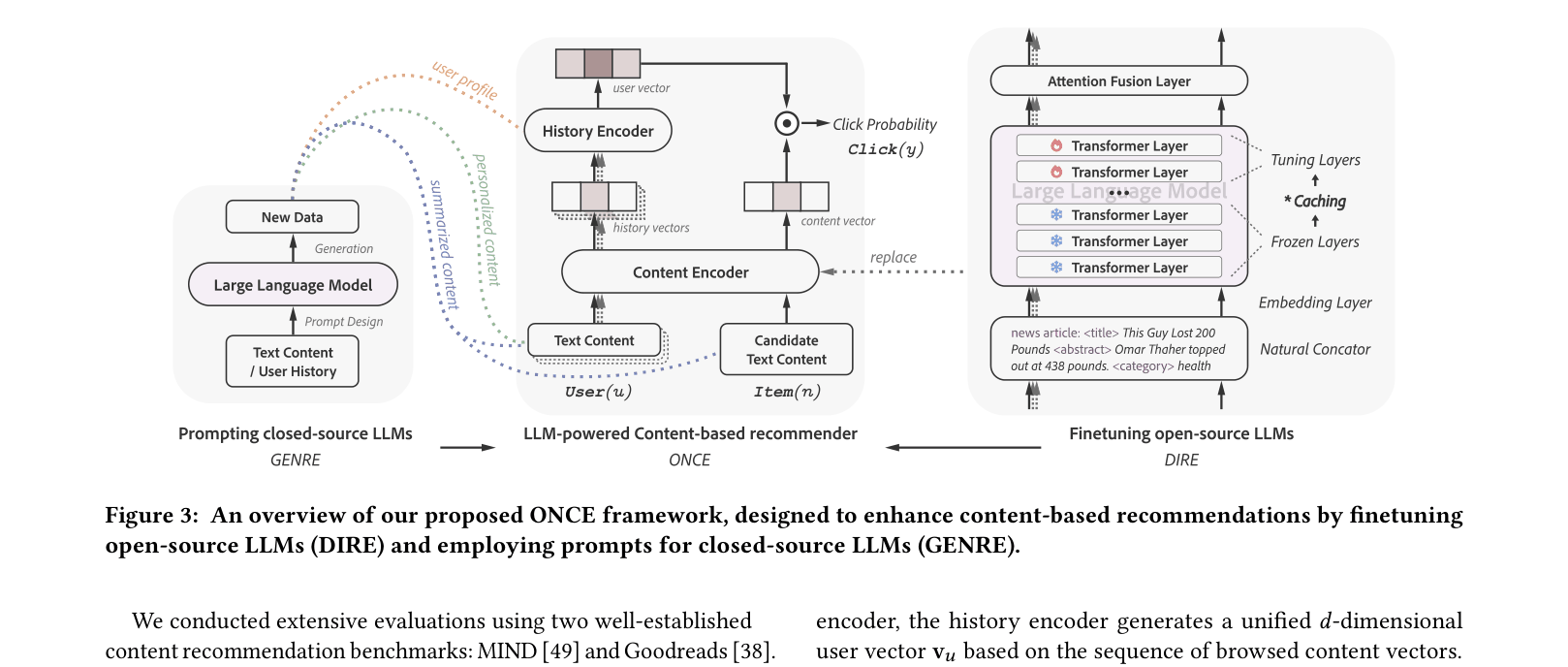
The ONCE framework integrating GENRE (Prompting) and DIRE (Fine-tuning)
Evaluation Highlights
- +19.32% improvement in nDCG@5 on the MIND news recommendation dataset compared to state-of-the-art baselines using ONCE
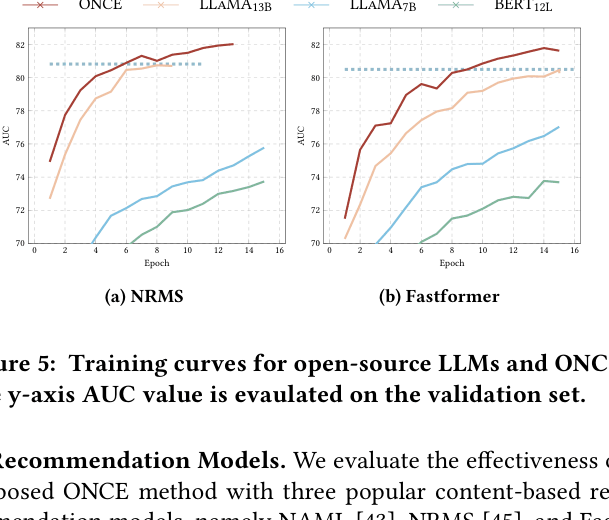
- Fine-tuning LLaMA alone (DIRE) consistently yields >10% gains over BERT-based baselines across multiple metrics
- Using generated data from GPT-3.5 accelerates LLaMA fine-tuning convergence by ~25-40% (reaching peak performance significantly earlier in training)
Breakthrough Assessment
8/10
Strong empirical results demonstrating how to effectively combine the complementary strengths of open weights (fine-tunability) and closed APIs (generation quality) for recommendation.