📝 Paper Summary
Generative Recommendation
Large Language Models (LLMs) for Recommendation
Preference Alignment
OneRec replaces traditional cascade ranking systems with a single-stage generative model that produces session-wise video lists, optimized via Direct Preference Optimization using self-hard negative sampling.
Core Problem
Traditional recommender systems rely on a complex cascade of independent rankers (recall, pre-ranking, ranking), where errors propagate and isolated optimization limits overall performance.
Why it matters:
- The effectiveness of each isolated stage limits the upper bound of subsequent stages in cascade systems
- Current generative retrieval models act only as selectors in the retrieval stage and fail to match the accuracy of well-designed multi-stage rankers
- Point-by-point generation lacks context awareness, requiring hand-crafted rules to ensure diversity and coherence within a recommendation session
Concrete Example:
In a standard cascade system, if the 'recall' stage fails to retrieve a relevant niche video, the subsequent 'ranking' stage never sees it, making recovery impossible. OneRec generates the final list directly from the full item space, avoiding this bottleneck.
Key Novelty
Unified Single-Stage Generative Session Recommendation
- Replaces the multi-stage retrieve-and-rank pipeline with a single encoder-decoder model that generates a full list (session) of items directly from user history
- Uses a session-wise generation approach rather than next-item prediction, allowing the model to implicitly learn list-level context, coherence, and diversity
- Employs Iterative Preference Alignment with a personalized reward model to select 'self-hard' negative samples from beam search results for DPO training
Architecture
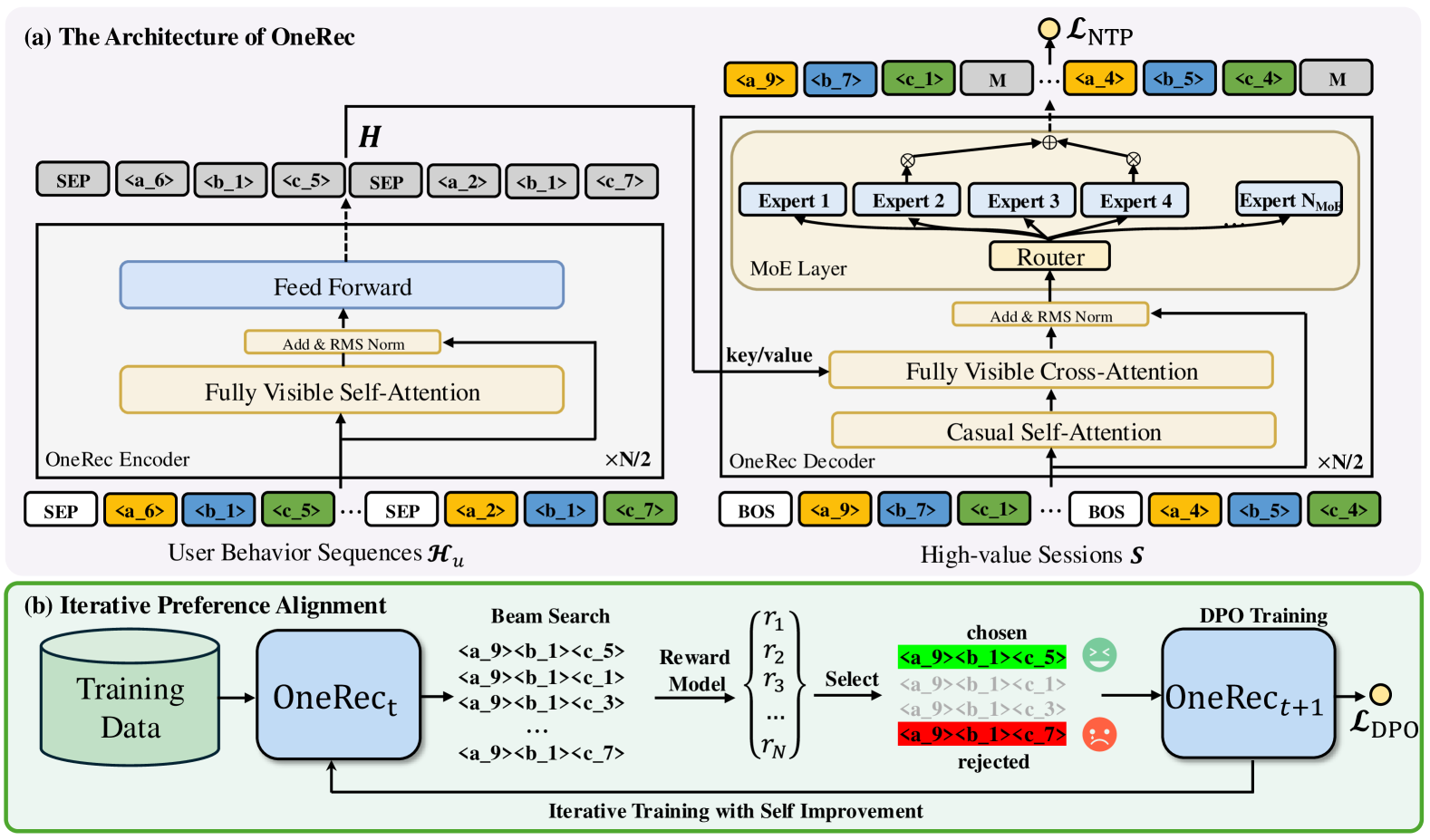
The overall training pipeline of OneRec, including the session-wise generation task and the Iterative Preference Alignment (IPA) process.
Evaluation Highlights
- Achieved a 1.6% increase in watch-time in online A/B testing on Kuaishou (a platform with hundreds of millions of DAUs)
- Significantly outperforms strong baselines like SASRec and TIGER on offline metrics, particularly in session-based watch time (swt) and view probability (vtr)
- Scaling the model using sparse Mixture-of-Experts (MoE) activates only 13% of parameters during inference while maintaining high model capacity
Breakthrough Assessment
8/10
One of the first successful industrial deployments of an end-to-end generative recommender that replaces, rather than augments, the traditional cascade ranking pipeline, with significant online gains.