📝 Paper Summary
Generative recommendation
Sequential recommendation
Foundation models for recommendation
RecGPT is a text-driven foundation model that replaces item IDs with quantized semantic tokens and uses a hybrid attention mechanism to enable zero-shot sequential recommendation across new domains without retraining.
Core Problem
Traditional sequential recommenders rely on specific item IDs, making them unable to generalize to new domains or items (cold-start) without extensive retraining.
Why it matters:
- Recommender systems fail in data-sparse environments or when introducing new product lines because ID embeddings lack semantic transferability.
- Current approaches require resource-intensive retraining cycles whenever the item catalog changes significantly.
- Existing ID-based methods cannot effectively handle the 'cold-start' problem where new items lack interaction history.
Concrete Example:
A system trained on Amazon 'Baby' products cannot recommend 'Games' because the item IDs (e.g., item_386) are disjoint. RecGPT processes the text description 'basketball' directly, allowing it to recommend sports items even if it was only trained on baby products.
Key Novelty
Text-Driven Foundation Model with Finite Scalar Quantization (RecGPT)
- Derives item representations exclusively from text using an encoder and Finite Scalar Quantization (FSQ) to create a domain-invariant discrete token space, eliminating the need for domain-specific item IDs.
- Employes a hybrid attention mechanism that is bidirectional within an item's token sequence (to maintain semantic coherence) but causal between items (to model sequential user history).
- Integrates auxiliary continuous semantic embeddings alongside discrete tokens to prevent information loss typically associated with quantization.
Architecture
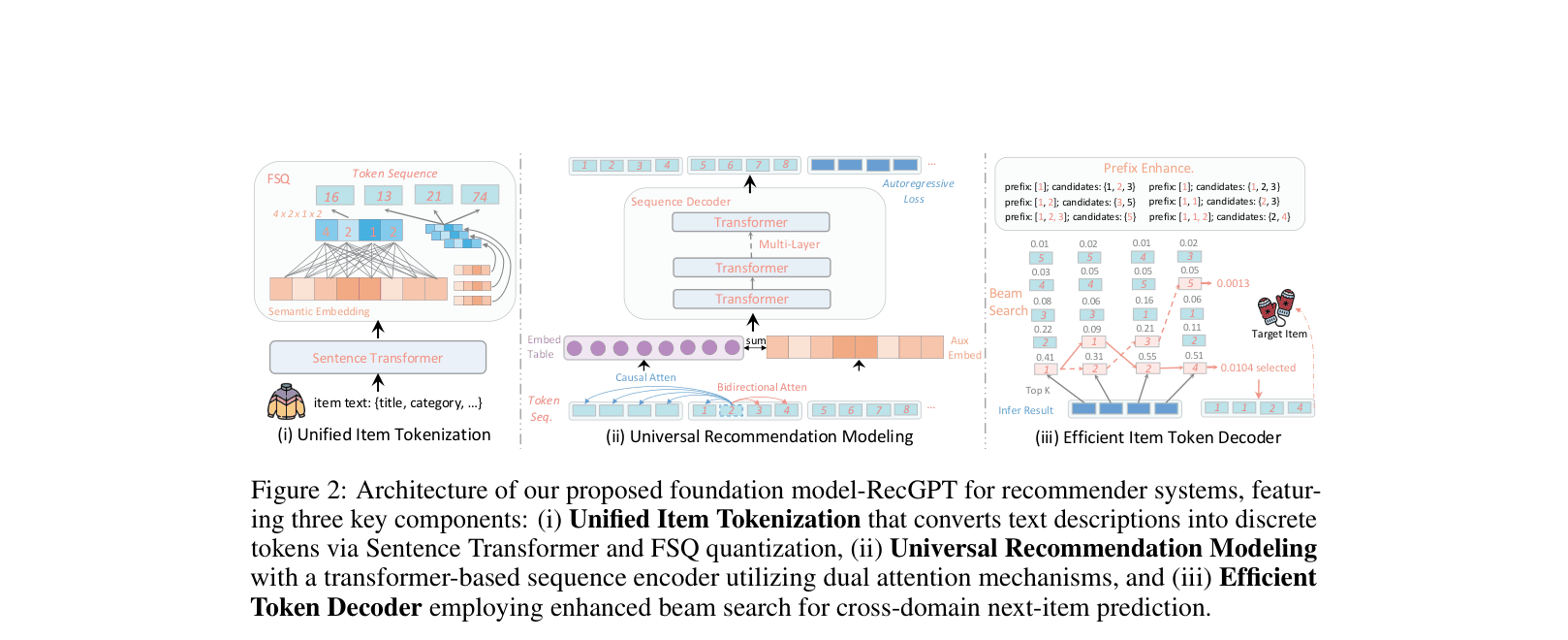
The complete RecGPT architecture including tokenization, modeling, and decoding.
Evaluation Highlights
- Achieves significantly higher zero-shot Hit@5 on the 'Baby' dataset (0.0283) compared to few-shot baselines like BERT4Rec (0.0099) that had access to 10% target data.
- Outperforms state-of-the-art methods in cold-start scenarios on the 'Office' dataset, reaching a Hit@5 of 0.0204 vs. 0.0207 for the strongest baseline (DuoRec) which was trained on domain data.
- Demonstrates power-law scaling properties similar to LLMs, where zero-shot performance consistently improves as pre-training data volume increases from 5% to 100%.
Breakthrough Assessment
9/10
Ideally solves the long-standing problem of ID dependency in recommenders. By successfully applying FSQ and LLM-style generation to recommendation, it achieves genuine zero-shot transfer, a major leap over ID-based transfer learning.
