📝 Paper Summary
Generative Recommendation
LLM Adaptation for Recommendation
Industrial Recommender Systems
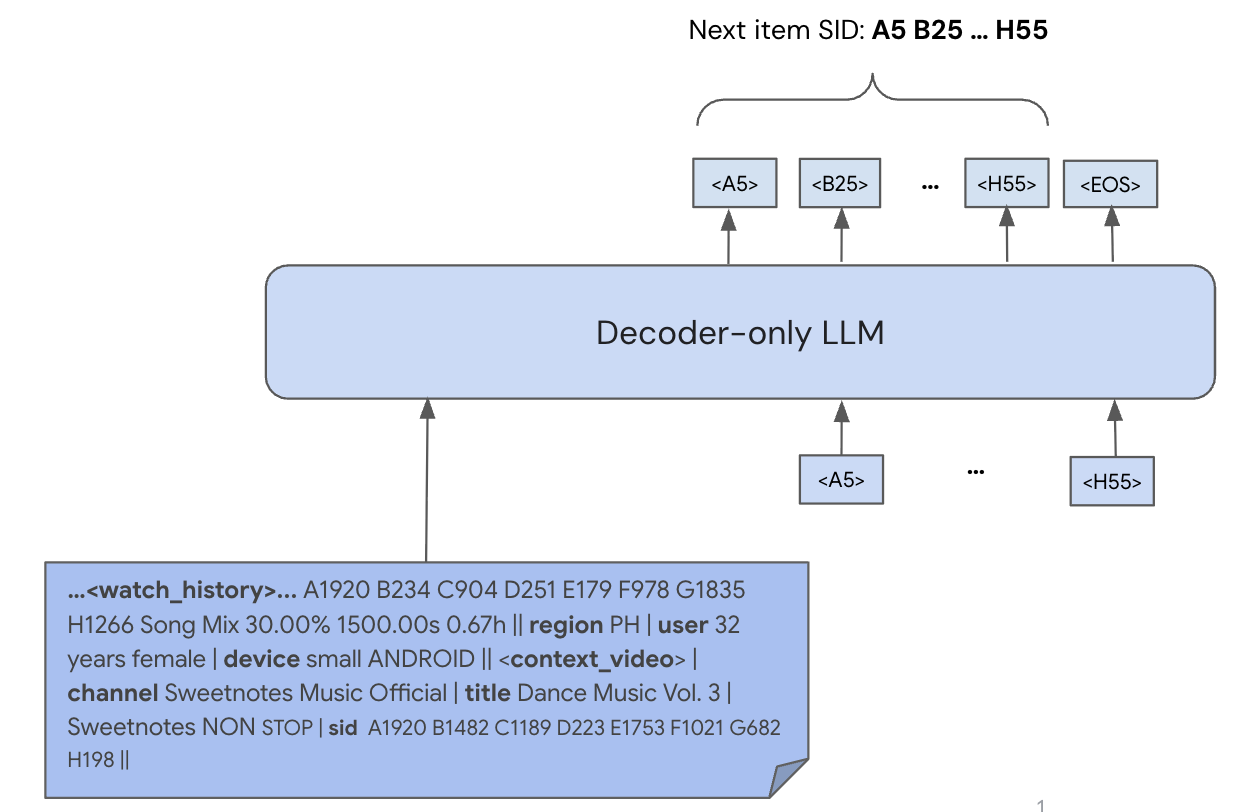
PLUM replaces massive embedding tables with compact Semantic IDs and adapts pre-trained LLMs via continued pre-training on user behavior data to perform generative retrieval at YouTube scale.
Core Problem
Standard Large Embedding Models (LEMs) rely on massive embedding tables that hit scaling bottlenecks and prevent using deeper networks, while off-the-shelf LLMs lack domain-specific knowledge of user behavior and item catalogs.
Why it matters:
- LEMs waste parameters on memorizing IDs rather than learning complex reasoning, limiting improvements from scaling neural networks
- Directly applying LLMs to recommendation fails because they don't understand user preferences or the specific item corpus (domain gap)
- Large embedding tables require massive training data, making it computationally expensive to train large Transformer architectures
Concrete Example:
A standard LLM might recommend a generic 'funny cat video' based on text, but fails to identify the specific video ID 'Vid123' that a user with a specific watch history (e.g., specific gaming channels) would actually click next.
Key Novelty
End-to-end framework aligning LLMs with discrete item tokens (SIDs) via Continued Pre-Training
- Replaces random item IDs with Semantic IDs (SIDs)—hierarchical discrete codes derived from multi-modal content and user co-occurrence patterns—allowing items to be processed as language tokens
- Bridges the domain gap by continuing to pre-train (CPT) the LLM on a mixture of user history sequences and video metadata, teaching it to predict SIDs from context before fine-tuning
- Shifts model complexity from massive memory-based embedding tables (LEMs) to compute-based deep neural networks, enabling better scaling with model size
Architecture
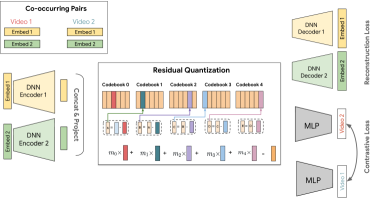
The SID-v2 training pipeline (RQ-VAE based).
Evaluation Highlights
- PLUM achieves substantially better sample efficiency than a heavily-optimized production LEM, matching performance with significantly fewer training examples
- Retrieval performance scales effectively with model size, continuing to improve up to a Mixture-of-Experts (MoE) model with over 900M activated parameters
- Hallucination rate (generating invalid SIDs) drops to < 5% after supervised fine-tuning
Breakthrough Assessment
9/10
Successfully deploys generative retrieval at YouTube scale (billions of users/items), proving LLMs can replace massive embedding tables in industrial settings. A major architectural shift from LEMs.