📝 Paper Summary
LLM-based Recommendation
Zero-shot/Few-shot Recommendation
The paper empirically evaluates ChatGPT's ability to perform recommendation tasks by reformulating point-wise, pair-wise, and list-wise ranking policies into domain-specific prompts.
Core Problem
While LLMs excel in NLP, their capabilities and limitations as off-the-shelf recommender systems—specifically in aligning with traditional information retrieval ranking policies—remain unclear.
Why it matters:
- Standard supervised recommendation models struggle with data sparsity (cold start) and long-tailed items, where LLMs might generalize better
- It is unknown which ranking strategy (point, pair, or list) yields the best cost-performance balance for LLM-based recommenders
- Understanding how to trigger recommendation capabilities via prompts without fine-tuning is crucial for utilizing closed-source LLMs like ChatGPT
Concrete Example:
In a movie recommendation scenario, a standard model fails on a new user with little history. ChatGPT, given a prompt with 5 example interactions, can be asked to rank 5 candidate movies (list-wise), compare two movies (pair-wise), or score one movie (point-wise) to predict preferences.
Key Novelty
Aligning LLMs with Information Retrieval Ranking Policies via Prompting
- Reformulate three traditional ranking policies (point-wise, pair-wise, list-wise) into distinct prompt templates tailored for LLMs
- Evaluate ChatGPT as a zero/few-shot recommender across diverse domains (Movie, Book, Music, News) to determine which ranking perspective is most effective
Architecture
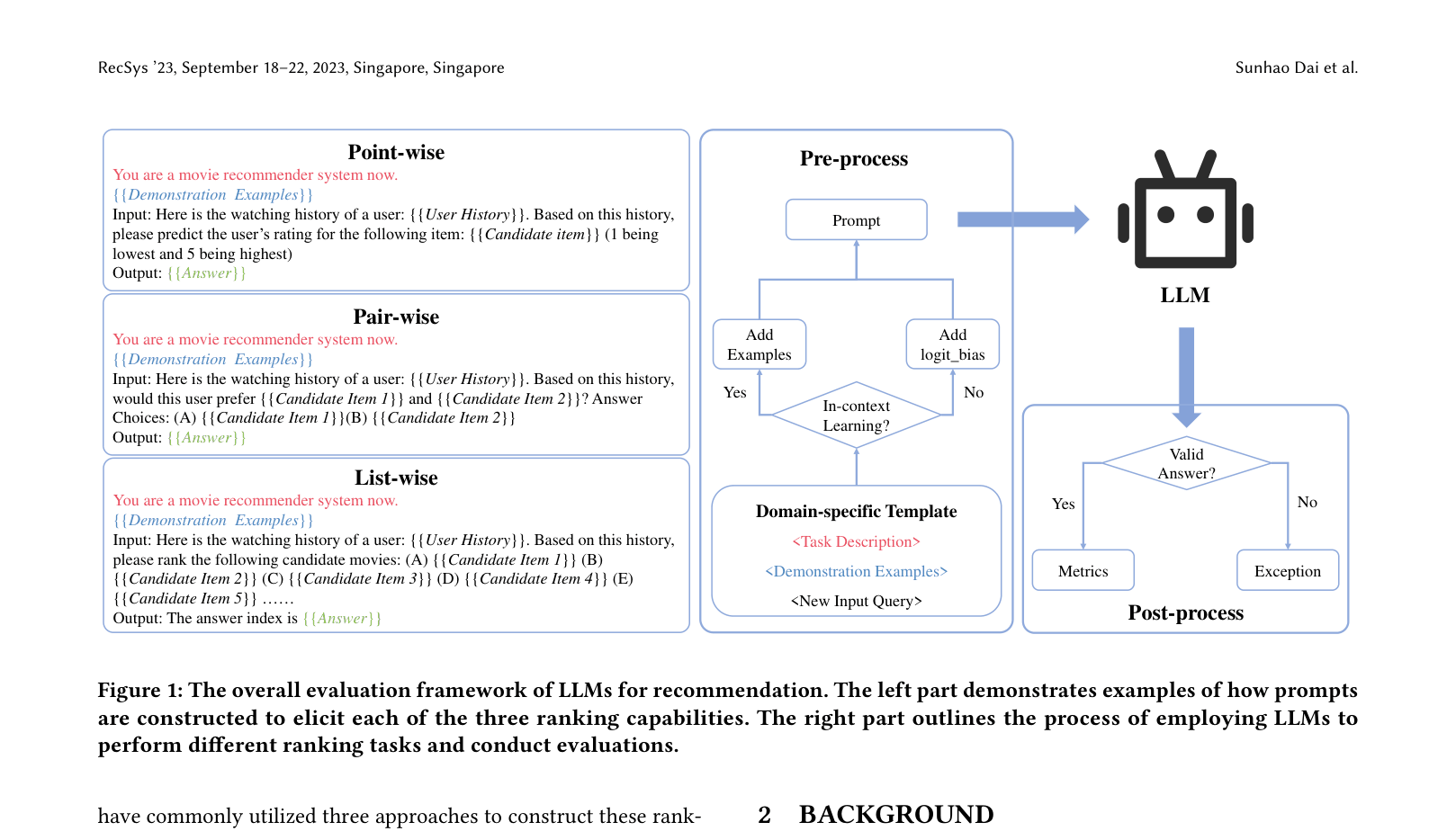
The framework for evaluating LLM recommendation capabilities using three prompting strategies: Point-wise, Pair-wise, and List-wise ranking.
Evaluation Highlights
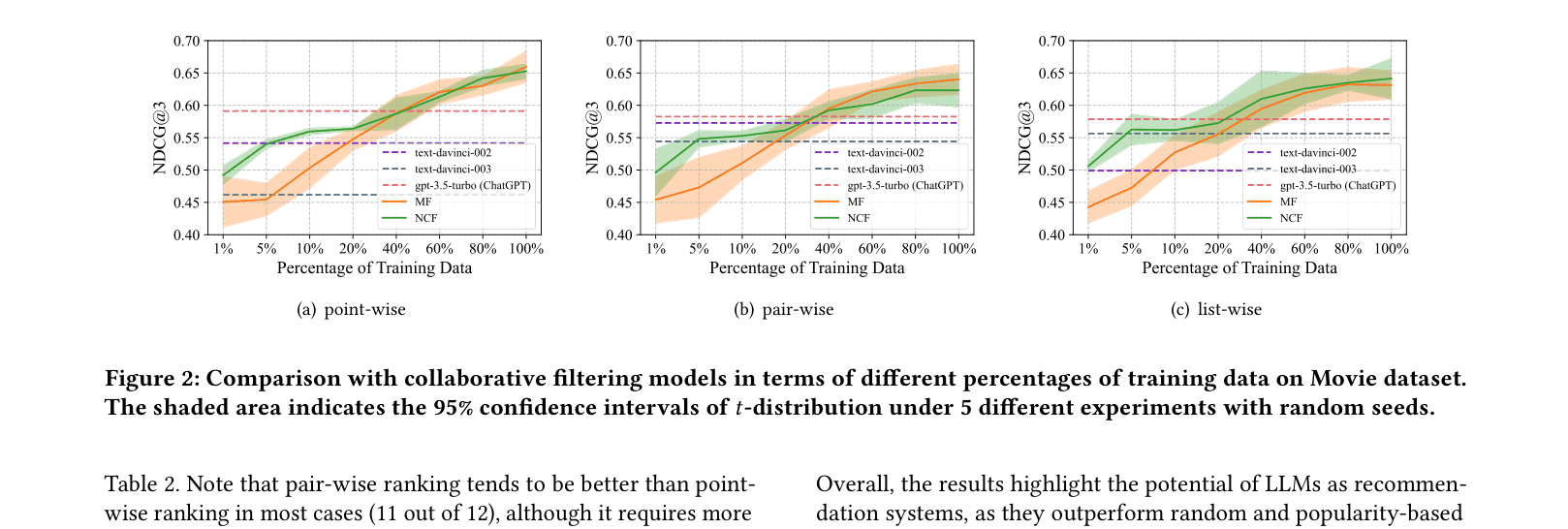
- ChatGPT consistently outperforms GPT-3.5 baselines (text-davinci-002/003) across all three ranking capabilities on Movie, Book, and Music datasets
- ChatGPT outperforms traditional trained baselines (Matrix Factorization, NCF) when training data is limited (<40% on Movie dataset)
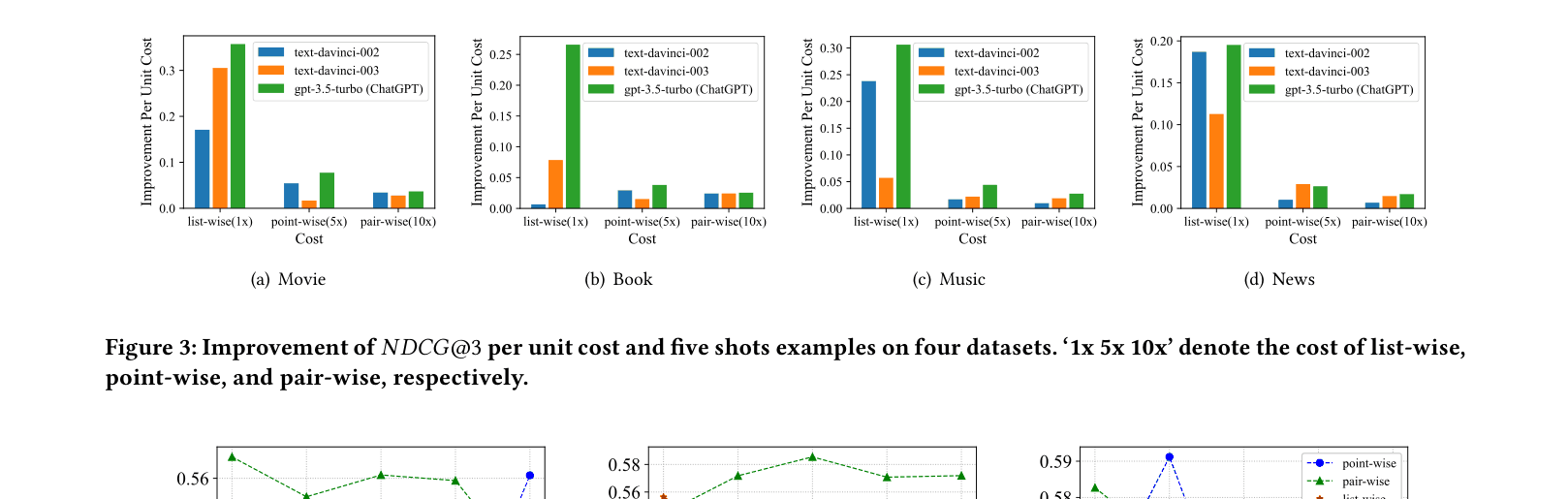
- List-wise ranking offers the best trade-off between performance and cost compared to point-wise (5x cost) and pair-wise (10x cost) prompting approaches
Breakthrough Assessment
7/10
A solid empirical study establishing baselines for ChatGPT in RecSys. While not introducing a new architecture, it provides the first comprehensive comparison of ranking policies for LLMs, offering practical guidance on cost vs. performance.