📝 Paper Summary
LLM-based recommendation
Zero-shot ranking
The paper demonstrates that LLMs can serve as effective zero-shot rankers in recommender systems if position bias and order perception issues are mitigated via specialized prompting and bootstrapping.
Core Problem
Traditional recommender systems struggle to capture complex user preferences solely from behavior history and lack general world knowledge, while adapting PLMs typically requires expensive fine-tuning.
Why it matters:
- Existing models act as 'narrow experts' lacking common sense or background knowledge required for complex recommendation tasks
- Fine-tuning large models on task-specific data is computationally expensive and limits generalization to diverse tasks
- Understanding how to leverage LLMs for zero-shot ranking is crucial for the next generation of recommender systems
Concrete Example:
When given a sequence of watched movies, a standard LLM prompt often fails to perceive the chronological order or gets biased by the order of candidate items (e.g., preferring items listed first), leading to suboptimal recommendations.
Key Novelty
Conditional Ranking with LLMs (LLMRank)
- Formalizes recommendation as a conditional ranking task where historical interactions act as conditions and retrieved items as candidates
- Identifies and addresses specific LLM deficiencies in recommendation: lack of order perception, position bias, and popularity bias
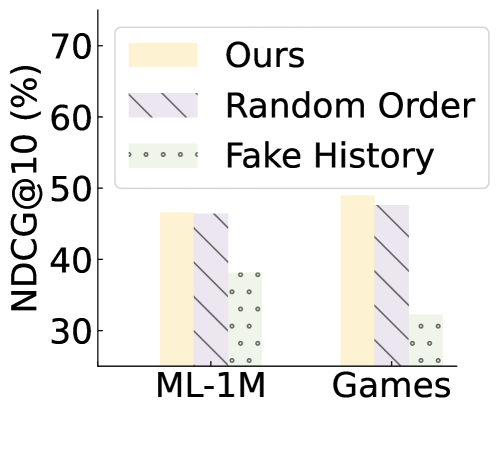
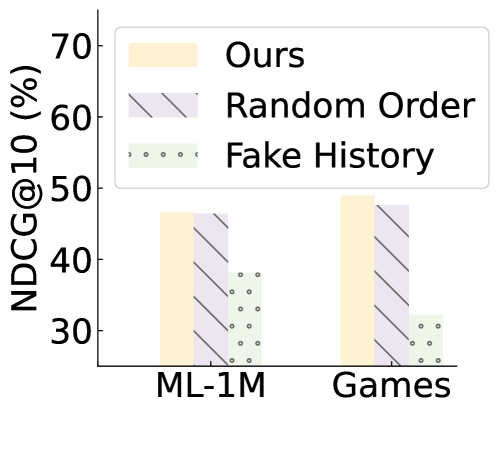
- Proposes 'Recency-focused prompting' and 'In-context learning' (using the sequence itself as examples) to trigger order perception without external data
Architecture
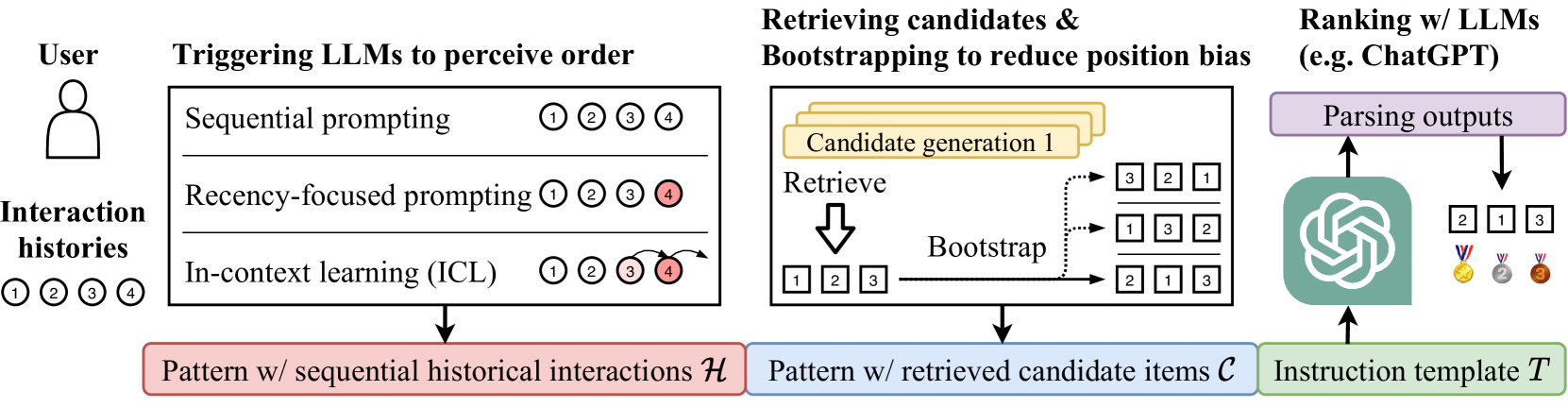
The overall framework of using LLMs as rankers via instruction following.
Evaluation Highlights
- Zero-shot LLMs (specifically GPT-3.5) outperform existing zero-shot baselines (e.g., UniSRec) and even challenge trained baselines (e.g., BPRMF) on the Games dataset
- Bootstrapping (repeated ranking with shuffled candidates) significantly improves performance, alleviating position bias
- LLMs effectively rank candidates from multiple diverse retrievers, outperforming conventional models like Pop and BPRMF in complex candidate scenarios
Breakthrough Assessment
7/10
Provides a solid empirical foundation for using LLMs as rankers, identifying key biases and offering practical prompting solutions. While not a new architecture, it systematically validates LLMs for zero-shot ranking.