📝 Paper Summary
RAG-based personalization
Generative personalization
The paper improves personalized text generation by decomposing it into retrieval, ranking, summarization, and synthesis stages, enhanced by a multi-task objective that teaches the model to identify authorship.
Core Problem
Most personalized generation approaches rely on domain-specific features or short sentence-level tasks, failing to generalize to passage-length generation across different domains using generic LLMs.
Why it matters:
- Personalized AI assistants need to generate long-form content (emails, reviews) that matches a specific user's style without relying on rigid, pre-defined user attributes.
- Existing methods often struggle with long user histories; simply retrieving recent documents (RecentDoc) or using embeddings (RankDocDense) can miss diverse stylistic nuances or specific content needs.
- Zero-shot LLMs often fail to capture deep personal style without explicit finetuning or structured context.
Concrete Example:
When generating a book review, a standard retriever might pull generic positive reviews like 'I love this book.' However, the specific user might typically write detailed critiques about character development. A standard model fails to capture this 'why,' generating a generic response instead of one reflecting the user's analytical style.
Key Novelty
Writing-Education Inspired Multi-Stage Framework
- Decomposes generation into education-inspired steps: retrieving past writings, ranking them by relevance/evidence, summarizing key topics, and synthesizing important vocabulary before generating.
- Introduces 'RankDocBySnpt': A novel retrieval strategy that retrieves short snippets to maximize relevance but ranks the full parent documents to provide broader context.
- Correlates reading with writing: Adds an auxiliary 'author distinction' task where the model must determine if two texts were written by the same person, improving its ability to model user style.
Architecture
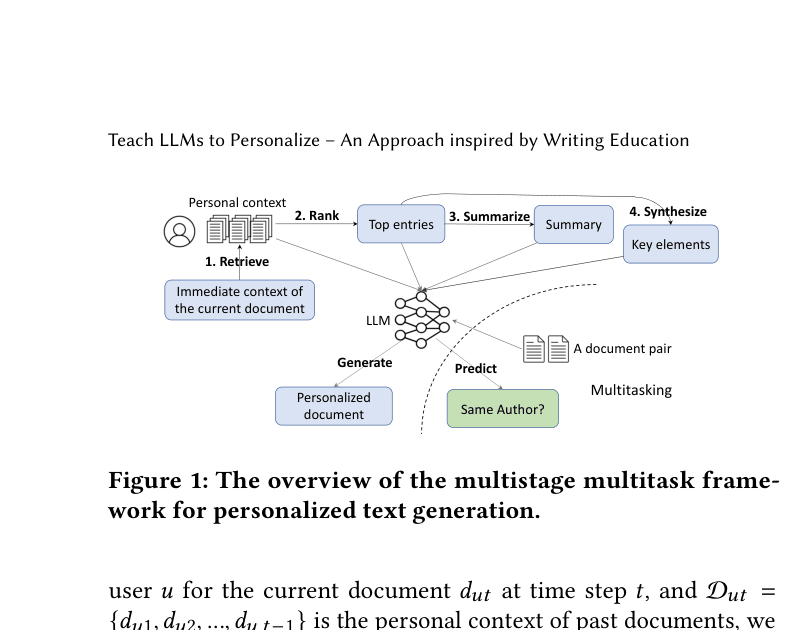
Overview of the multistage multitask framework. It shows the flow from Immediate Context -> Retrieval -> Ranking -> Summarization/Synthesis -> Generation.
Evaluation Highlights
- Outperforms strong baselines (including BM25 and zero-shot PaLM 2) on Avocado emails, Amazon reviews, and Reddit comments across BLEU and ROUGE metrics.
- Multi-task learning (AuthorPred) achieves best performance: +2.08 BLEU on Avocado emails compared to BM25 baseline.
- RankDocBySnpt retrieval strategy consistently outperforms standard dense and sparse retrieval methods on passage-level generation tasks.
Breakthrough Assessment
7/10
Strong empirical results on passage-level personalization across three diverse domains. The multi-stage pipeline and auxiliary authorship task are intuitive and effective, though the components themselves (T5, standard retrieval) are established technologies.