📝 Paper Summary
Memory organization
Conversational Recommendation
A conversational recommendation framework that maintains a dynamic user memory graph to enable structure-preserving reasoning and zero-shot policy generation for unseen users.
Core Problem
Existing conversational recommender systems typically isolate long-term history from short-term dialog state, fail to reason holistically over user knowledge, and struggle with zero-shot adaptation to new users.
Why it matters:
- Asking good questions requires soft-matching knowledge between users and items, which is difficult without holistic reasoning
- Most Collaborative Filtering (CF) systems overfit to existing user embeddings, failing on cold-start users
- Conversational recommendation requires an open policy space (innumerable items/slots) rather than a fixed pre-defined space
Concrete Example:
A user who previously visited 'Sea's' (history) and currently asks for 'Thai food' (current dialog) needs a recommendation like 'Basil'. A standard system might treat history and current requests separately, whereas this approach links 'Sea's' to 'affordable' and 'Thai' to 'Basil' via a graph to infer the user wants affordable Thai food.
Key Novelty
Memory Graph Convolutional Network for Policy Reasoning (UMGR)
- Constructs a User Memory Graph (MG) merging offline history (visited items) and online dialog state (current preferences) into a unified heterogeneous graph
- Uses a graph neural network (R-GCN) to reason directly over this graph, generating dialog policies (items to recommend, slots to ask) by ranking graph nodes
- Enables zero-shot application by learning reasoning patterns over graph structures rather than memorizing user-specific IDs
Architecture
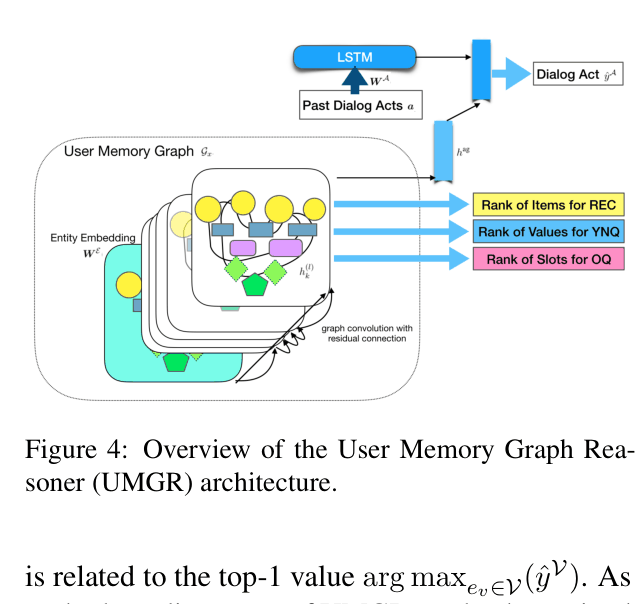
The architecture of the User Memory Graph Reasoner (UMGR).
Evaluation Highlights
- +6.24% improvement in Act Accuracy over Memory Network baseline on the MGConvRex dataset
- +19.01% improvement in Item Matching Rate (IMR) over Pretrained Embeddings baseline
- Achieved 67.93% Success Rate in online simulation, significantly outperforming RandomAgent (6.55%) and MemoryNetwork (4.73%)
Breakthrough Assessment
7/10
Proposes a solid graph-based reasoning framework for conversational recommendation and introduces a new dataset (MGConvRex) filling a gap in memory-grounded dialog. However, the reliance on ground-truth NLU for graph updates limits immediate end-to-end applicability.
