📝 Paper Summary
Memory recall
Memory organization
Mem0 introduces a scalable memory architecture that dynamically extracts and updates salient information from conversations, enhanced by a graph-based variant for modeling complex entity relationships.
Core Problem
LLMs lack persistent memory mechanisms, relying on fixed context windows that cause them to forget user preferences and established facts across extended or multi-session interactions.
Why it matters:
- AI agents forget critical user details (e.g., dietary restrictions) across sessions, undermining trust and user experience
- Full-context approaches are computationally expensive and struggle to retrieve relevant details buried in long, thematically disconnected histories
- Existing RAG and extended context windows delay rather than solve the limitation of maintaining coherent, long-term reasoning
Concrete Example:
A user mentions being vegetarian in session one. In a later session, when asked for dinner ideas, a memory-less system suggests chicken, contradicting the preference. Mem0 retains the vegetarian constraint across sessions to suggest appropriate options.
Key Novelty
Dynamic Memory Management with Graph Enhancements (Mem0 and Mem0-graph)
- Implements a dual-phase pipeline (extraction and update) that uses an LLM to identify salient facts from new messages and determine whether to add, update, or delete existing memories
- Introduces a graph-based variant where entities are nodes and relationships are edges, enabling complex reasoning across interconnected facts via traversal rather than just semantic similarity
Architecture
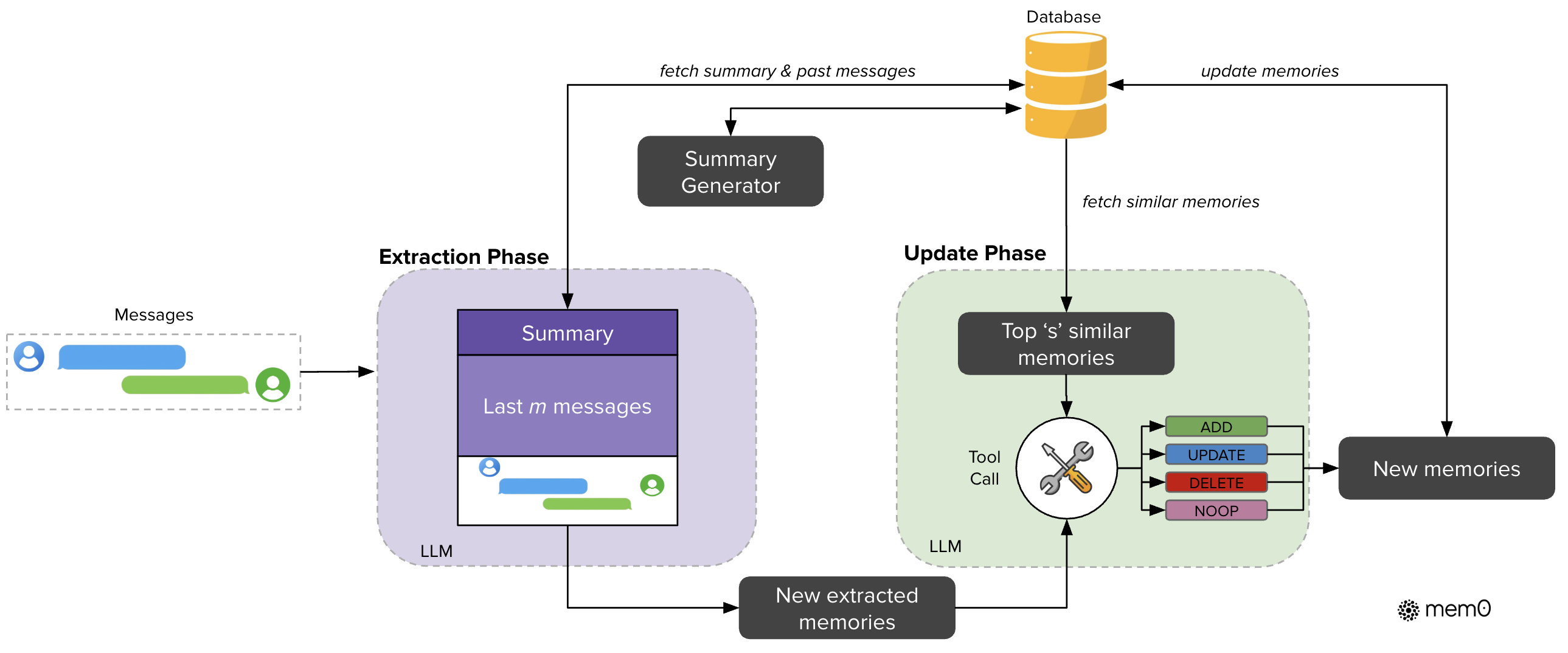
The core Mem0 pipeline showing the Extraction and Update phases.
Evaluation Highlights
- Mem0 achieves 26% relative improvement in LLM-as-a-Judge metric over OpenAI baseline on the LOCOMO benchmark
- Reduces p95 latency by 91% compared to full-context approaches while saving more than 90% in token costs
- Mem0 with graph memory scores approximately 2% higher overall than the base Mem0 configuration on LOCOMO
Breakthrough Assessment
7/10
Strong practical improvements in latency and cost for long-term memory, with a solid graph-based extension. While conceptually evolutionary, the operational efficiency gains are significant for production agents.