📝 Paper Summary
Memory recall
Memory organization
SGMem organizes dialogue history as a sentence-level graph to retrieve coherent context across turns, rounds, and sessions without relying on expensive LLM-based entity extraction.
Core Problem
Existing long-term memory methods suffer from fragmentation where relevant information is dispersed across coarse-grained units (turns/sessions) and generated summaries, making it difficult to retrieve precise, coherent context.
Why it matters:
- Coarse retrieval (whole sessions/turns) includes irrelevant noise that distracts the LLM
- Generated memories (summaries/facts) often lose fine-grained details needed for specific questions
- Entity-centric graph methods are computationally expensive and discard non-entity contextual information
Concrete Example:
If a user asks about a specific detail mentioned in a long conversation, a session-level retriever might pull the entire 50-turn session (too much noise), while a summary-based retriever might miss the specific detail entirely because it was compressed out.
Key Novelty
Sentence Graph Memory (SGMem)
- Decomposes dialogue into sentences (atomic units) and links them via semantic similarity edges, creating a graph that connects related statements across different timeframes
- Jointly indexes and retrieves raw dialogue sentences alongside generated memories (summaries, facts, insights) to combine precision with high-level understanding
- Uses a lightweight graph construction (NLTK segmentation + embedding similarity) rather than expensive LLM-based entity-relation extraction
Architecture
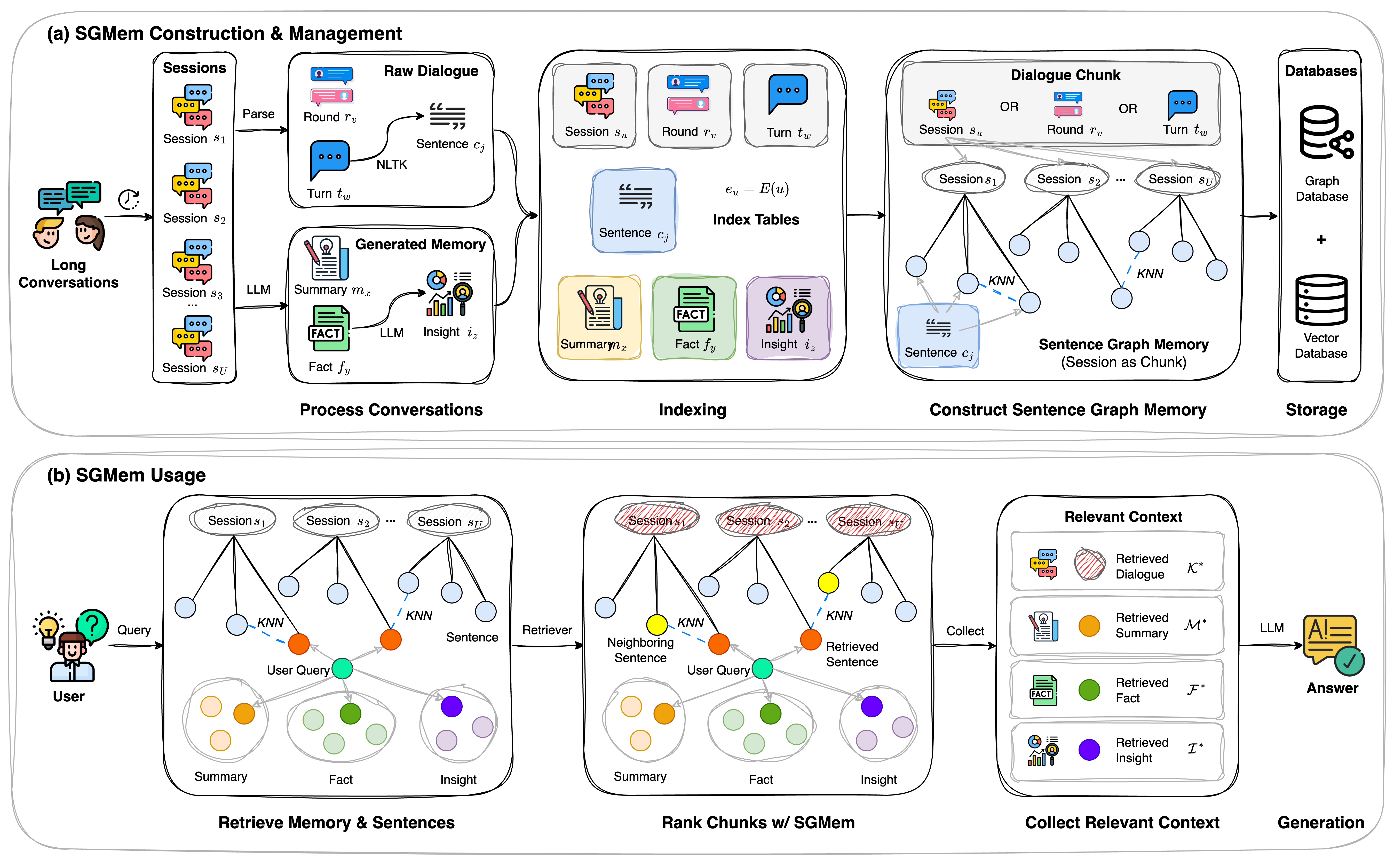
Overview of SGMem framework, split into Construction & Management (left) and Usage (right)
Evaluation Highlights
- Outperforms strong baselines (including LightRAG and MemoryScope) on LongMemEval and LoCoMo benchmarks in accuracy
- Demonstrates consistent accuracy gains across single-hop, multi-hop, and temporal reasoning question types compared to turn/round/session-based retrieval
- Ablation studies show that integrating all memory types (sentences + summaries + facts + insights) yields the highest performance
Breakthrough Assessment
7/10
Offers a practical, lightweight alternative to complex entity-graph memories by using sentence graphs. While not a fundamental architectural shift in LLMs, it significantly improves RAG precision for long conversations.