📝 Paper Summary
Memory organization
Graph-based memory
A-Mem is a memory system for LLM agents that autonomously structures knowledge by creating atomic notes, dynamically linking them based on content, and evolving existing memories as new information arrives.
Core Problem
Existing memory systems rely on rigid, predefined storage structures (like static databases or fixed schemas) that cannot adaptively organize information or forge new connections as an agent learns.
Why it matters:
- Rigid structures limit generalization in open-ended tasks where relationships between concepts are not known in advance
- Current graph databases require predefined schemas, preventing the autonomous discovery of novel patterns or mathematical solutions outside the preset framework
- Fixed workflows fail to maintain effectiveness in long-term interactions where context and understanding must evolve over time
Concrete Example:
When an agent learns a novel mathematical solution, current systems can only categorize it within a preset framework. They fail to link it to related concepts or update previous partial solutions because the database schema doesn't anticipate the new relationship.
Key Novelty
Zettelkasten-inspired Agentic Memory (A-Mem)
- treats every interaction as an 'atomic note' containing both raw content and LLM-generated metadata (keywords, tags, context)
- uses the LLM itself to actively analyze and generate links between new and existing notes, rather than relying solely on passive embedding similarity
- implements a 'memory evolution' mechanism where new experiences trigger rewrites of old memory contexts to reflect deeper understanding
Architecture
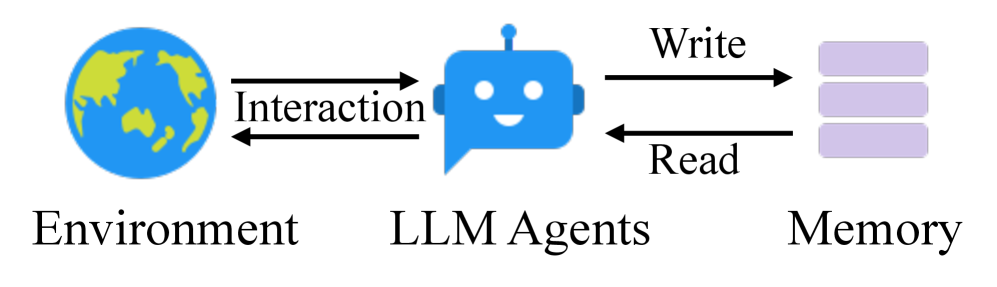
The workflow of the A-Mem system, contrasting it with traditional static memory systems
Evaluation Highlights
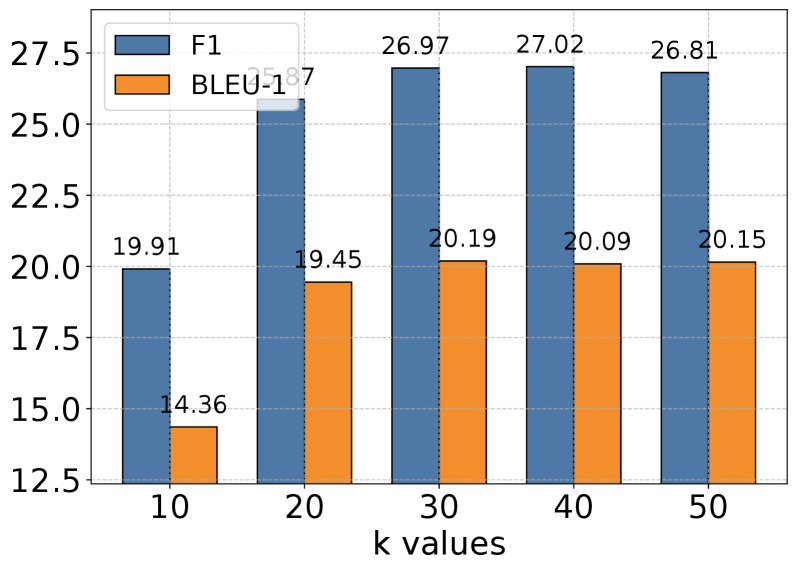
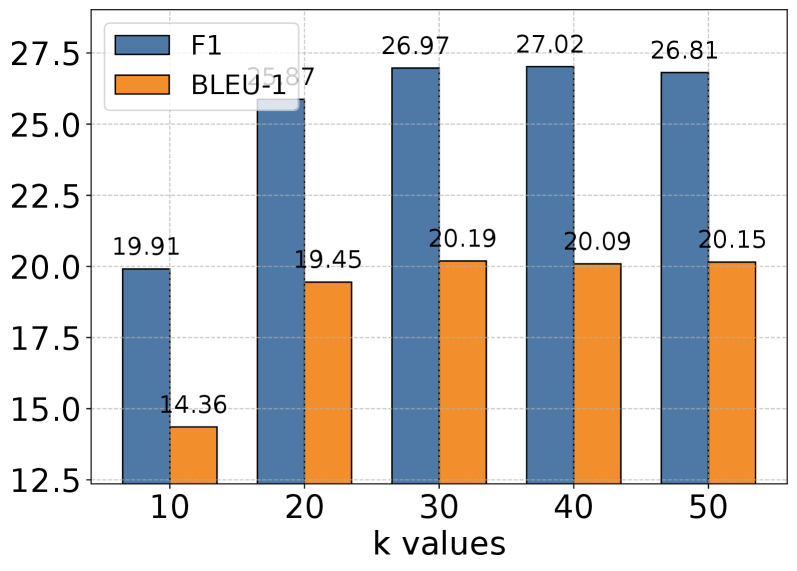
- Achieved 3.45 F1 score on DialSim dataset, a 35% improvement over LoCoMo (2.55) and 192% higher than MemGPT (1.18)
- Doubled performance on complex Multi-Hop reasoning tasks in the LoCoMo dataset compared to GPT-based baselines
- Reduced token usage by 85-93% per memory operation (approx. 1,200 tokens) compared to MemGPT and LoCoMo baselines
Breakthrough Assessment
7/10
Strong conceptual novelty in applying Zettelkasten principles to agent memory with self-evolution. Significant performance gains on reasoning tasks, though primarily evaluated on conversation datasets rather than complex action environments.