📝 Paper Summary
Memory recall
Memory organization
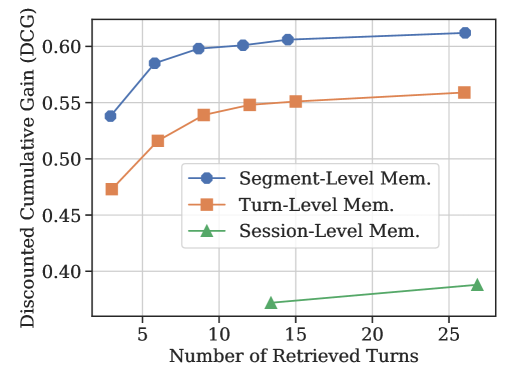
SeCom improves long-term conversational memory by segmenting history into topically coherent units and compressing them to remove redundancy before retrieval, outperforming turn-level and session-level approaches.
Core Problem
Existing retrieval-augmented generation methods use suboptimal memory granularities: turn-level retrieval misses dispersed context, while session-level retrieval introduces irrelevant noise.
Why it matters:
- Turn-level retrieval often fails when keywords are missing from a specific historical turn, leading to fragmentary context
- Session-level retrieval brings in extraneous topics (e.g., a chat about World War II mixed with a chat about probability), distracting the LLM
- Summarization-based memory often suffers from information loss and hallucination, degrading response quality in long-term interactions
Concrete Example:
User asks 'What is the answer?' referring to a probability question asked 5 turns ago. Turn-level retrieval misses the original question because the current turn lacks keywords. Session-level retrieval pulls the entire chat, including an irrelevant debate about World War II, confusing the model.
Key Novelty
Segment-Level Memory with Compression-Based Denoising (SeCom)
- Partitions long conversations into 'segments'—topically coherent blocks larger than a turn but smaller than a session—using an LLM-based segmenter refined via self-reflection
- Applies prompt compression (LLMLingua-2) to these segments to remove inherent natural language redundancy, acting as a denoising step that improves retrieval accuracy without information loss
Architecture
Overview of the SeCom framework: Segmentation → Compression → Retrieval → Generation
Evaluation Highlights
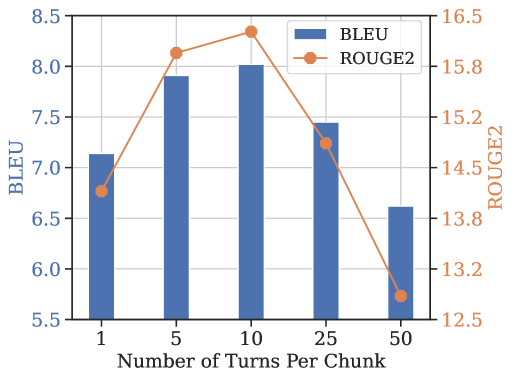
- SeCom outperforms turn-level baselines by +4.8% and session-level by +8.2% on LOCOMO benchmark (averaged across metrics)
- Achieves superior retrieval recall (Hit@1) compared to raw segments when compression rate is >50% using LLMLingua-2
- Segmentation model surpasses baselines on DialSeg711 with a +5.7 improvement in WindowDiff score
Breakthrough Assessment
7/10
Strong empirical evidence that segment-level granularity is the 'sweet spot' for memory. The combination with prompt compression as a denoiser is a clever, effective insight.