📝 Paper Summary
Memory organization
Agentic memory management
Reinforcement Learning for Agents
Mem-α uses reinforcement learning to train LLM agents to actively manage a complex, multi-component memory system, optimizing directly for downstream question-answering accuracy rather than relying on fixed rules.
Core Problem
Current memory-augmented agents rely on fixed, pre-defined rules or prompts to update memory, but LLMs often fail to determine what to store, how to structure it, or when to update it effectively, especially in complex scenarios.
Why it matters:
- Pre-defined rules are brittle and cannot adapt to diverse interaction patterns, leading to information loss or bloated memory
- Even state-of-the-art models like GPT-4o struggle to spontaneously select the correct tools for complex memory updates without explicit training
- Small models with weak instruction-following capabilities get overwhelmed by complex memory tool sets, making effective long-term memory inaccessible to efficient models
Concrete Example:
When an agent receives a long stream of information containing a mix of casual conversation, storytelling, and factual documents, a rule-based system might save everything (overflowing context) or miss subtle plot points. Mem-α learns to specifically extract only the facts necessary to answer future questions while discarding noise.
Key Novelty
Reinforcement Learning for Active Memory Construction
- Formulates memory management as a sequential decision-making problem where the agent decides how to update Core, Episodic, and Semantic memory chunks
- Optimizes memory construction directly against downstream QA performance (RAG accuracy) rather than supervising the memory trace itself, allowing the agent to discover its own optimal storage strategies
- Achieves massive length generalization: trained on 30k token sequences but generalizes to >400k tokens
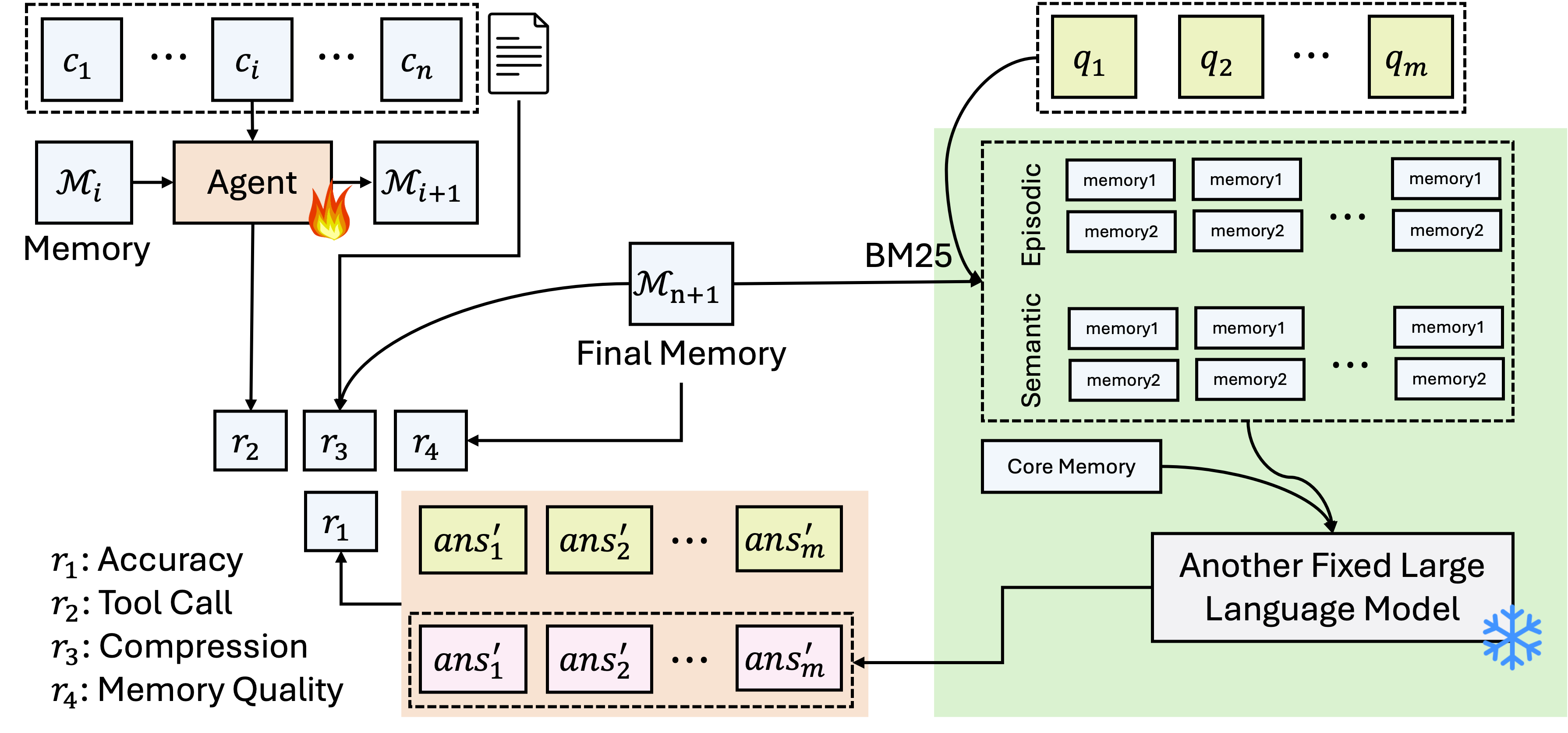
Architecture

The memory architecture and interaction flow. It displays the three memory components (Core, Semantic, Episodic) and the allowed operations for each.
Evaluation Highlights
- Generalizes to sequences exceeding 400k tokens (13× the max training length of 30k) while maintaining high retrieval accuracy
- Outperforms existing memory baselines (including MemGPT and Mem0) across diverse interaction patterns
- Demonstrates that RL enables agents to learn fundamental memory principles (what to keep/discard) rather than just memorizing patterns
Breakthrough Assessment
8/10
Significant advance in making memory agents 'active' learners rather than passive rule-followers. The 13x length generalization from training to inference is a particularly strong result for RL-based methods.