📝 Paper Summary
User-profile based personalization
Post-training (RL/Self-training)
REST-PG improves personalized text generation by training models to explicitly reason about user preferences and background before answering, using reinforced self-training to discover high-quality reasoning paths.
Core Problem
Personalization often requires using context that seems irrelevant to the prompt but reveals implicit preferences (e.g., mentioning children implies a safety preference), which standard LLMs fail to reason over effectively.
Why it matters:
- Existing retrieval methods struggle with 'implicit relevance'—context that isn't semantically similar to the prompt but is crucial for personalization
- Human-annotated data for 'personalized reasoning' is scarce and costly, making supervised training difficult
- Standard supervised fine-tuning on synthetic reasoning data is insufficient because the model's initial reasoning may not actually align with user preferences
Concrete Example:
If a user profile says 'I have two children age 3 and 4' and the user asks 'Suggest room heater brands', a standard model might ignore the children. A personalized model should reason: 'User has young kids -> Safety is a priority -> Suggest heaters with child-safe features.'
Key Novelty
Reasoning-Enhanced Self-Training (REST-PG)
- Generates synthetic 'reasoning paths' (summaries of user style/preferences) using an LLM to bridge the gap between user profile and expected output
- Uses Expectation-Maximization Reinforced Self-Training to let the model explore different reasoning paths and iteratively train on the ones that produce responses most similar to the user's ground truth
- Treats reasoning as a latent variable optimized via reinforcement learning without needing human-labeled reasoning steps
Architecture
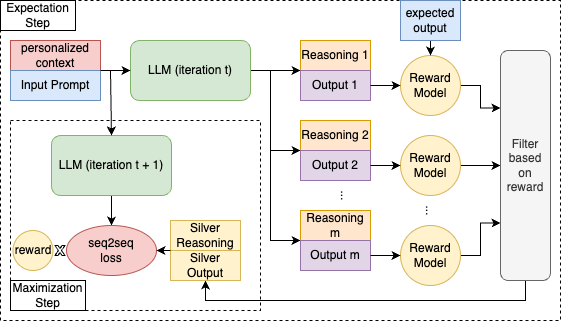
Overview of the REST-PG optimization framework including the Expectation and Maximization steps.
Evaluation Highlights
- +14.5% average relative performance gain across LongLaMP benchmark tasks compared to Supervised Fine-Tuning (SFT) baselines
- Outperforms self-training without reasoning enhancement by 6.5% on average, proving the specific value of the reasoning step
- Achieves best-in-class performance on 4 diverse tasks: Email Completion, Abstract Generation, Review Writing, and Topic Writing
Breakthrough Assessment
7/10
Strong methodological contribution by combining reasoning generation with reinforced self-training for personalization. Significant empirical gains on established benchmarks, though relies on synthetic data.