📝 Paper Summary
Visual Question Answering (VQA)
Personal Photo/Video Retrieval
Memory Recall
Multimodal Reasoning
MemexQA introduces a task and architecture for answering natural language questions about personal photo collections by reasoning across multiple images, timestamps, and metadata simultaneously.
Core Problem
Standard VQA answers questions about single images, but personal memory recall requires reasoning over large, dynamic collections of photos/videos and multimodal metadata (time, GPS, titles).
Why it matters:
- People accumulate thousands of photos/videos and use them to recover memories, but manual searching is tedious
- Current VQA models lack the ability to localize answers across multiple media documents or leverage collective reasoning
- Personal assistants (Siri, Alexa) need to answer questions like 'When did we last go hiking?' which requires understanding the user's past data
Concrete Example:
A user asks 'Where did we last see the fireworks?'. A standard VQA model looking at one photo of fireworks might just say 'sky'. MemexQA must find the specific fireworks photo with the latest timestamp (Dec 11, 2010) and use its GPS metadata to answer 'Maryland'.
Key Novelty
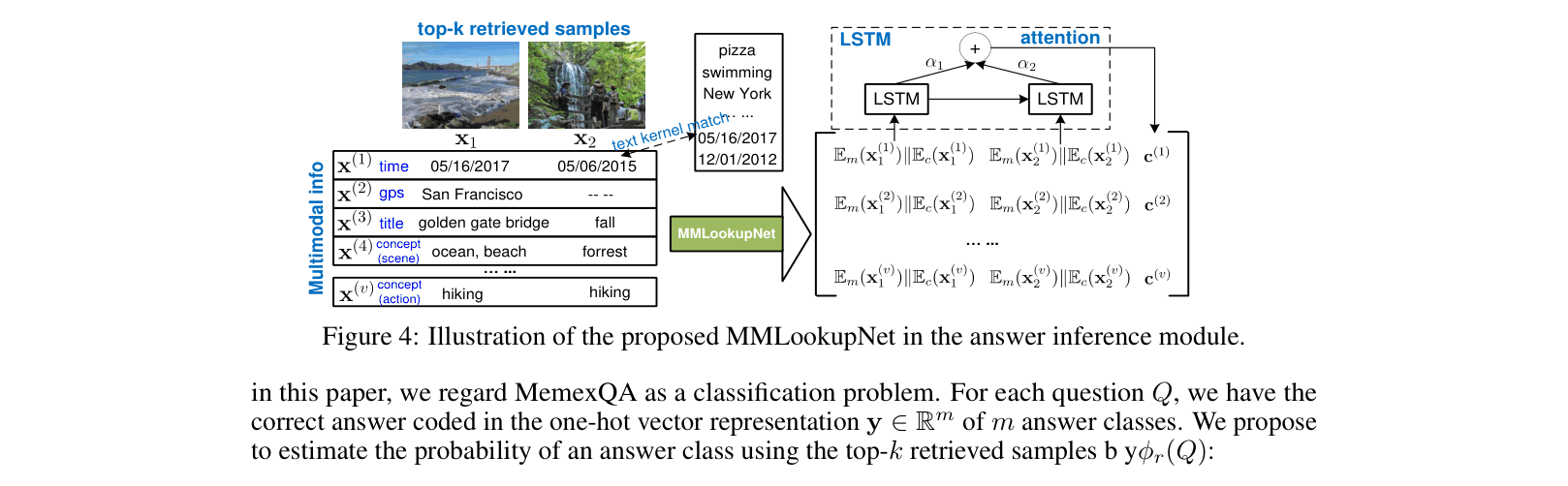
MemexNet with MultiModal Lookup Network (MMLookupNet)
- Treats QA as a retrieval-then-inference problem over a dynamic collection, rather than just visual analysis of a single static image
- Uses a unified end-to-end architecture that learns to attend to specific retrieved samples and specific modalities (time vs. text vs. image content) based on question type
Architecture
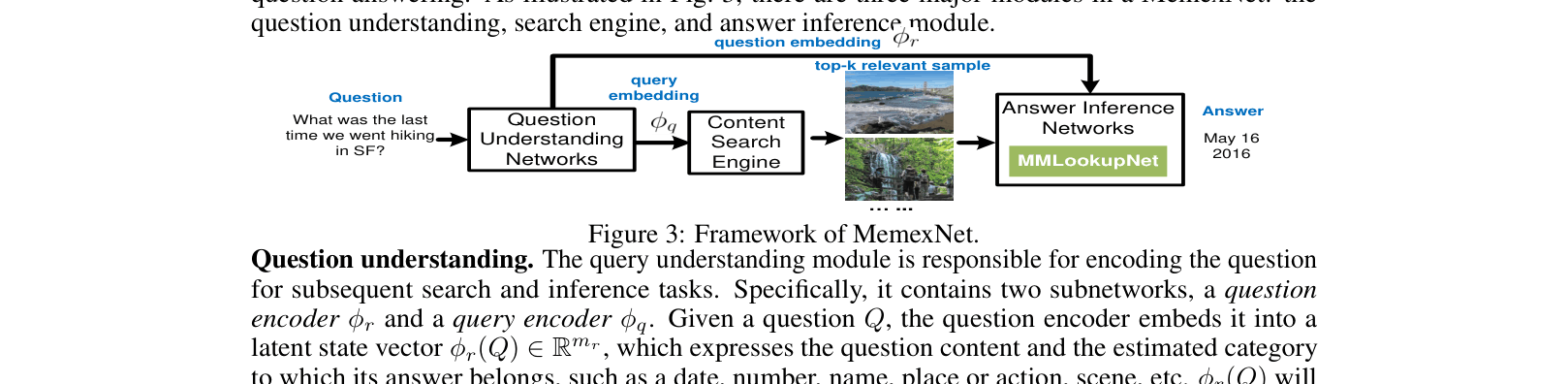
The overall framework of MemexNet
Evaluation Highlights
- MemexNet achieves 48.4% overall accuracy on MemexQA, outperforming strong LSTM baselines (39.0%) and attention models (43.3%)
- Human performance is significantly higher (92.7% with all data), indicating the task remains challenging for AI
- Adapts to TextQA (SQuAD) yielding 0.767 F1, comparable to specialized text-only QA models like BiDAF (0.760)
Breakthrough Assessment
7/10
Pioneered the 'VQA over collections' task with a large dataset and a novel multimodal architecture. While accuracy is low compared to humans, it established a necessary extension of VQA to real-world personal data.