📝 Paper Summary
Conversational personalization
Recommendation personalization
User modeling
This survey unifies two historically separate fields—personalized text generation and downstream task personalization—under a single theoretical framework, providing taxonomies for methods, data, and evaluation.
Core Problem
Research on personalized LLMs has fragmented into two disconnected streams: direct personalized text generation (e.g., chatbots) and downstream task improvement (e.g., recommendations), slowing progress.
Why it matters:
- Siloed research prevents cross-pollination; generation techniques could improve recommenders and vice versa.
- Lack of standardized definitions and evaluation metrics makes it difficult to compare approaches or measure true personalization effectiveness.
- Current systems struggle to seamlessly transition between conversational engagement and task-oriented reasoning (like product recommendation).
Concrete Example:
A mental health chatbot generates empathetic text (stream 1) but fails to recommend specific resources effectively (stream 2), while a movie recommender suggests accurate films (stream 2) but cannot explain why in a personalized conversational style (stream 1).
Key Novelty
Unified Taxonomy of Personalized LLM Usage
- Proposes a unified view where personalization is categorized by whether the LLM output is the end product (Direct Generation) or an intermediate signal for another system (Indirect Downstream Task).
- Formalizes personalization granularity into three levels: User-level (finest), Persona-level (group-based), and Global preference (general public), characterizing trade-offs between data requirements and specificity.
- Introduces the 'Adaptation Function' concept to mathematically formalize how user data is integrated into prompts or embeddings across both generation and downstream tasks.
Architecture
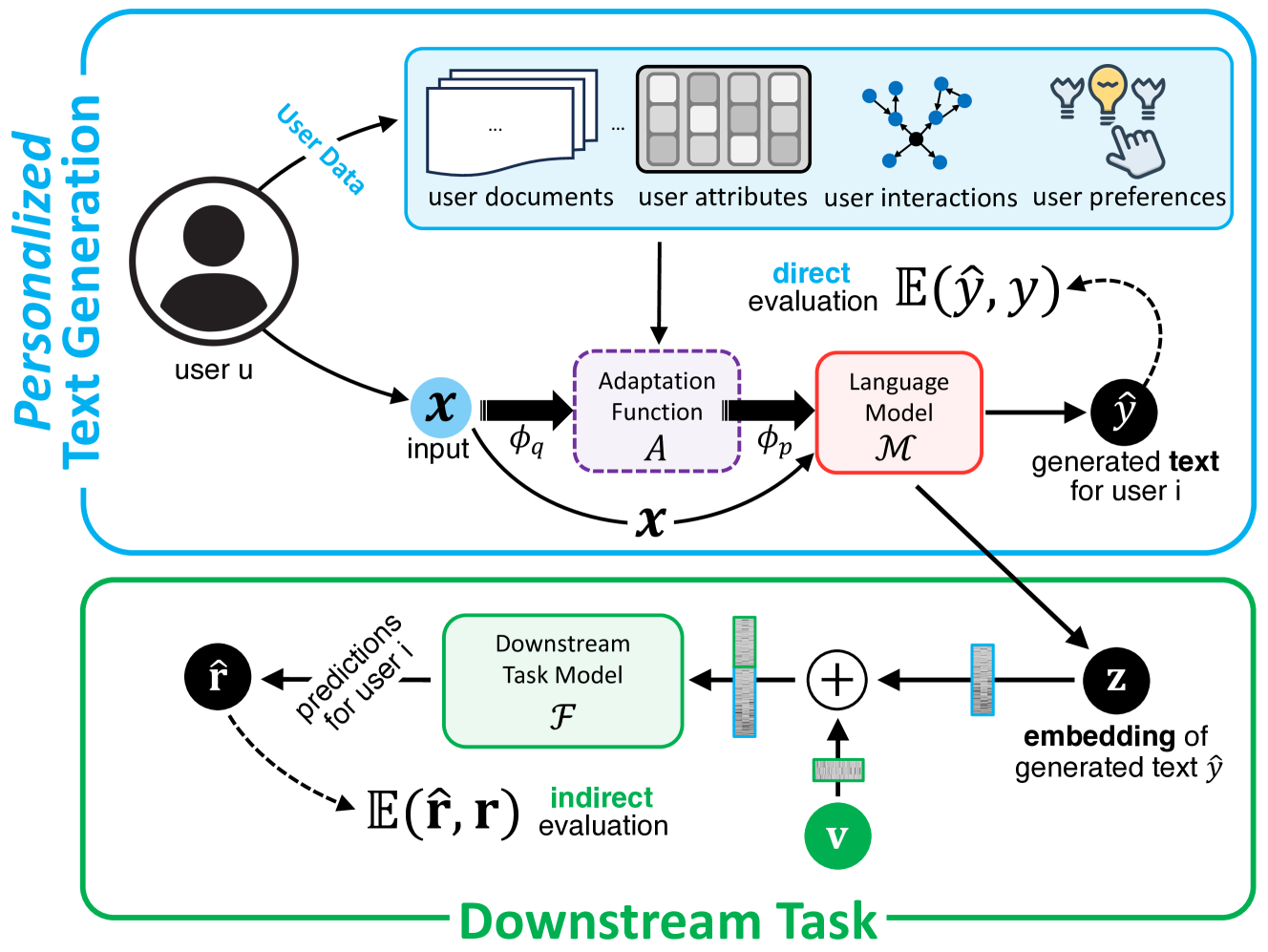
A unifying taxonomy and workflow distinguishing between 'Direct Personalized Text Generation' and 'Indirect Downstream Task Personalization'.
Evaluation Highlights
- Categorizes existing metrics into 'Direct Evaluation' (e.g., alignment with user-written text) and 'Indirect Evaluation' (e.g., recommendation accuracy).
- Identifies that direct evaluation often relies on scarce user-written ground truth, while indirect evaluation assesses performance boosts in external applications.
- Highlights the critical gap in datasets that support both conversational text generation and structured recommendation tasks simultaneously.
Breakthrough Assessment
7/10
A comprehensive survey that theoretically unifies fragmented subfields. While it doesn't propose a new model, the taxonomy and formalization are valuable for structuring future research.