📝 Paper Summary
Agent memory systems
Test-time scaling for agents
ReasoningBank distills generalizable strategies from both successes and failures to guide future agent actions, further enhancing performance through memory-aware test-time scaling that converts diverse exploration into better memory.
Core Problem
LLM agents deployed in continuous roles fail to learn from accumulated history, repeating errors and treating every task in isolation.
Why it matters:
- Agents discard valuable insights from related problems, leading to stagnant performance over time rather than self-evolution
- Existing memory systems mostly store raw trajectories or successful routines, ignoring critical lessons hidden in failure cases
- Current approaches lack a mechanism to scale experience effectively at test time, missing the synergy between computation scaling and memory quality
Concrete Example:
In a web shopping task, an agent might repeatedly fail to navigate a specific checkout flow because it doesn't remember previous failures. Without ReasoningBank, it retries blindly; with it, it retrieves a 'preventative lesson' from a past failure to avoid the specific error path.
Key Novelty
ReasoningBank & Memory-Aware Test-Time Scaling (MaTTS)
- Extracts structured memory items (title, description, reasoning content) from both successful and failed trajectories using self-judged outcomes, rather than just storing raw logs
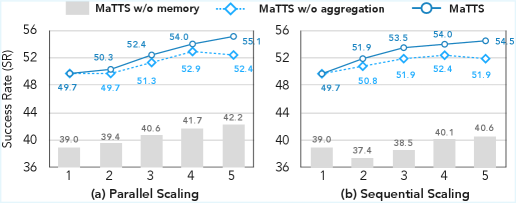
- MaTTS (Memory-aware Test-Time Scaling) uses this memory to guide diverse exploration (parallel or sequential) during test time, generating richer contrastive signals that in turn improve the memory bank itself
Architecture
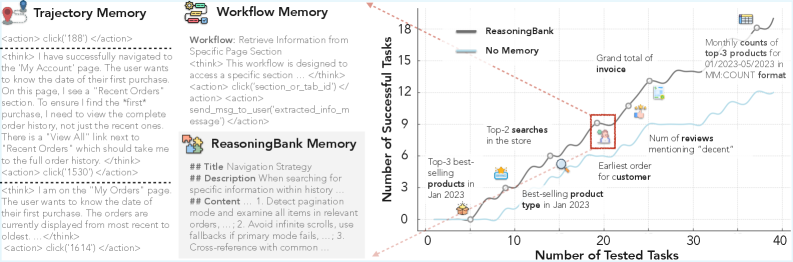
Overview of ReasoningBank showing the cycle of retrieving memory, executing the task, judging the outcome, and extracting reasoning from both success and failure.
Evaluation Highlights
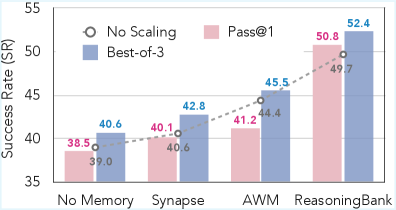
- +8.3% success rate improvement on WebArena using Gemini-2.5-flash compared to memory-free agents
- +34.2% relative improvement in success rate on WebArena-Shopping using MaTTS with parallel scaling (k=5) compared to non-scaling baselines
- Reduces interaction steps by 1.6 on WebArena and 2.8 on SWE-Bench-Verified, demonstrating improved efficiency alongside effectiveness
Breakthrough Assessment
8/10
Strongly integrates memory with test-time scaling—a timely direction. The focus on learning from failures and distilling reasoning (not just actions) addresses key limitations in current agentic memory systems.