📝 Paper Summary
Multi-agent
Automated Machine Learning (AutoML)
LLM-based Agents
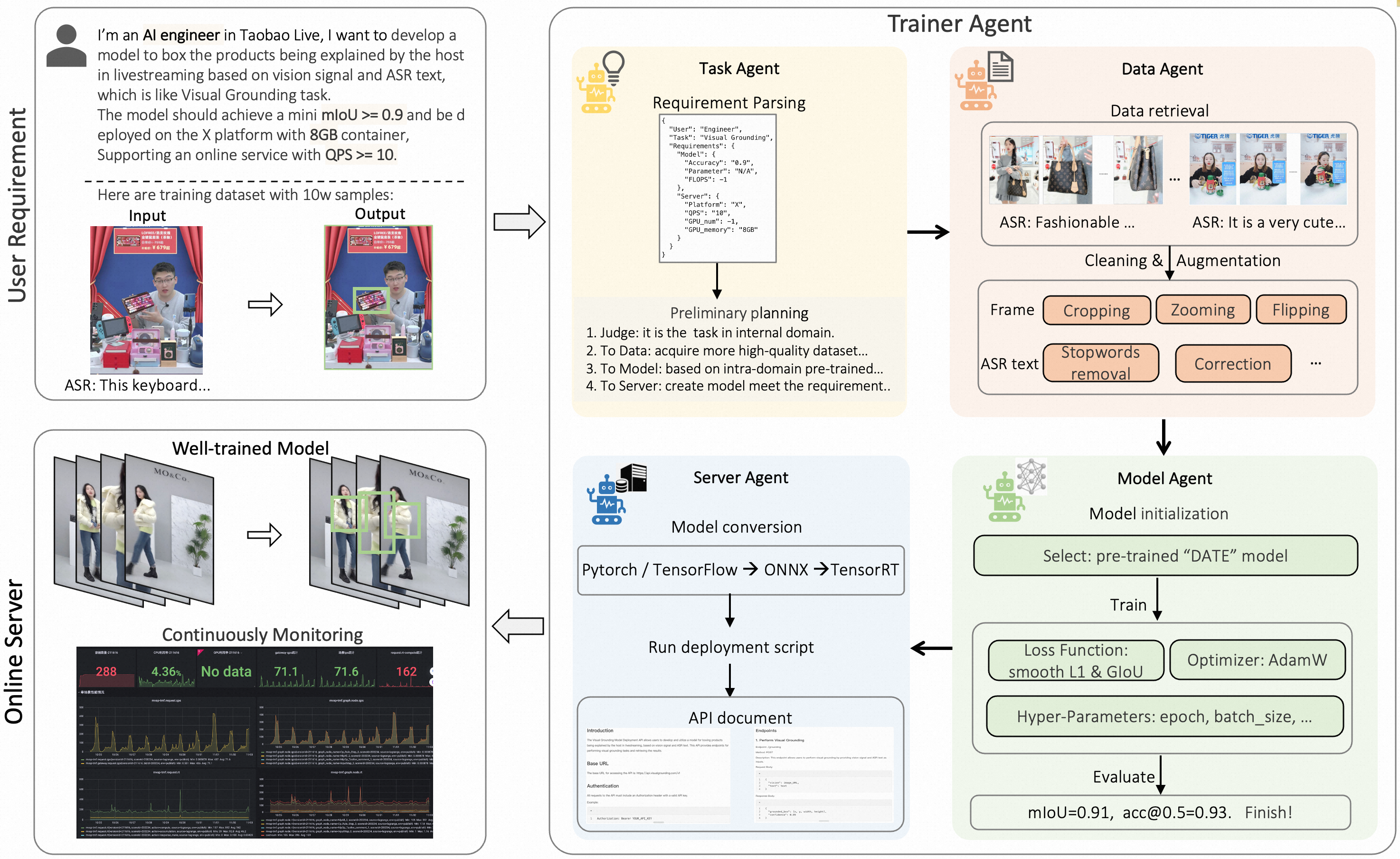
TrainerAgent is a multi-agent system that automates the full AI development lifecycle—from parsing user requests to training and deploying models—by coordinating specialized agents for task planning, data processing, model optimization, and serving.
Core Problem
Training custom AI models for specific business requirements is complex and time-consuming, requiring expert knowledge to navigate data cleaning, model selection, hyperparameter tuning, and deployment.
Why it matters:
- Non-experts struggle to translate business needs into technical model specifications
- Existing agents (e.g., HuggingGPT) focus on inference via API calls rather than training new models from scratch
- AutoML tools often require rigid inputs or high algorithmic understanding, lacking the flexibility of natural language interaction
Concrete Example:
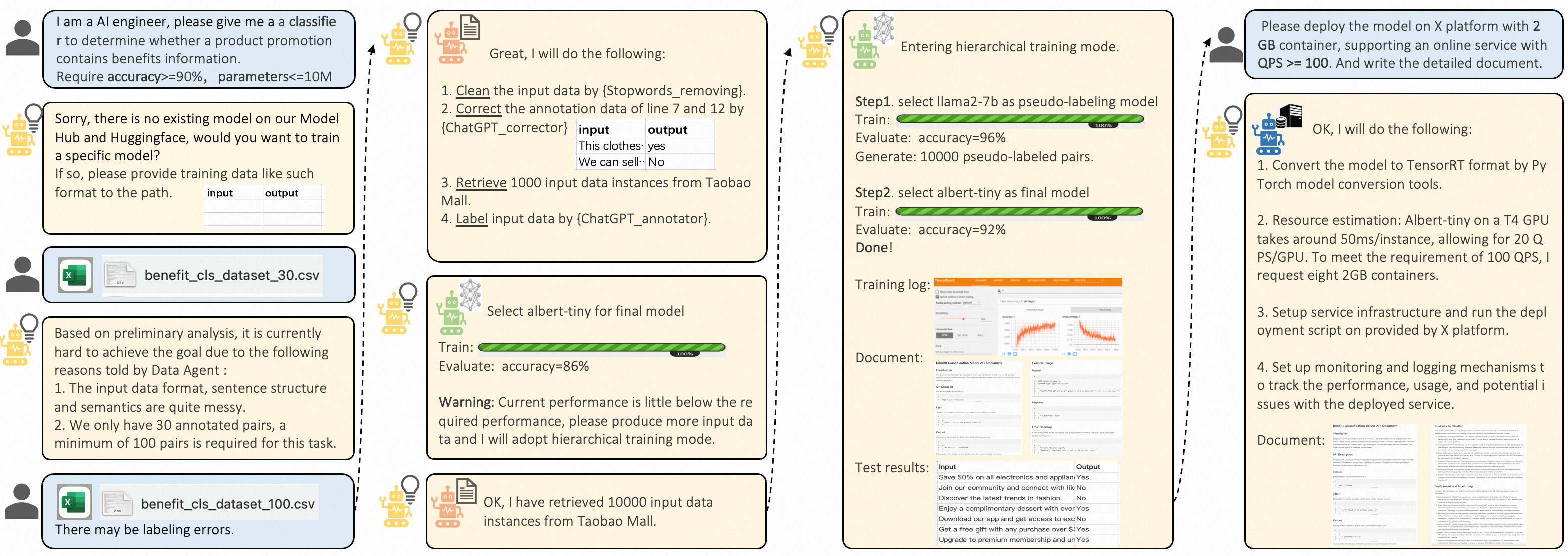
A user wants a 'cat vs dog' classifier but only provides raw images. A standard AutoML tool might fail if the data isn't pre-formatted or if the user requests specific speed/accuracy trade-offs in natural language. TrainerAgent parses the request, autonomously cleans the data, selects a model, trains it, and deploys a service API.
Key Novelty
End-to-End LLM-Driven Model Development via Role-Based Agents
- Decomposes the machine learning lifecycle into four specialized agents: Task (management), Data (processing), Model (training/tuning), and Server (deployment)
- Uses a central Task Agent as a hub to translate natural language requirements into structured plans that coordinate the other three agents
- Integrates domain-specific knowledge bases (SOPs) into agent prompts, allowing them to autonomously handle errors, reject unattainable tasks, and optimize for specific metrics like accuracy or latency
Architecture
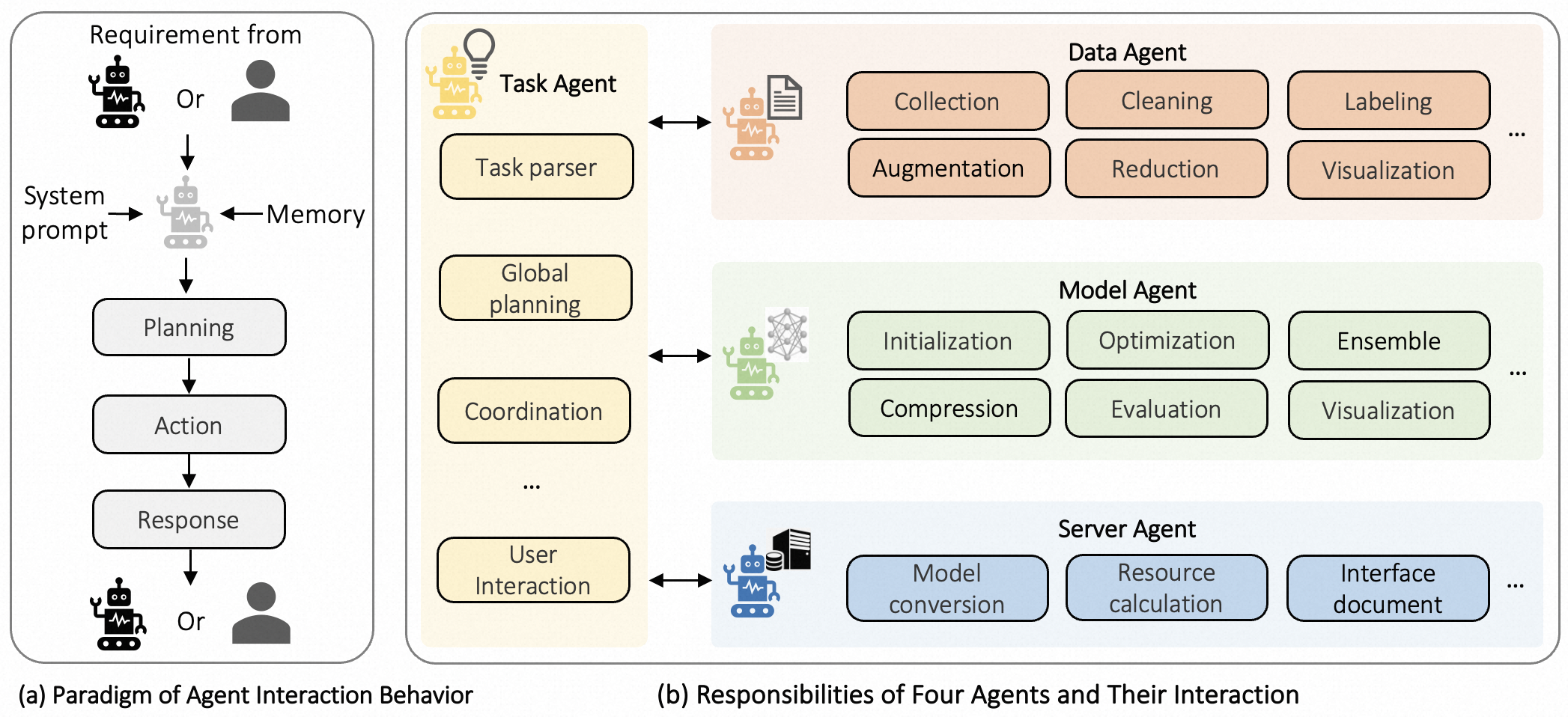
Overview of the TrainerAgent framework. (a) shows the internal structure of a single agent (Profile, Memory, Perception, Planning, Action). (b) shows the multi-agent collaboration workflow where the Task Agent coordinates the Data, Model, and Server Agents.
Evaluation Highlights
- Successfully automates training for diverse tasks including Visual Grounding, Image Generation, and Text Classification based on natural language prompts
- Demonstrates capability to identify and reject unattainable or unethical tasks (e.g., fantastical scenarios) during the planning phase
- Produces deployable service interfaces and documentation automatically after model training
Breakthrough Assessment
7/10
A solid application of multi-agent frameworks to the specific domain of AutoML/MLOps. While it relies on existing LLMs and tools, the structural decomposition of the training pipeline into agent roles is a practical step forward for accessible AI development.