📝 Paper Summary
Inference-time compute scaling
Constrained generation
Probabilistic programming
DISCIPL enables a Planner LM to write task-specific probabilistic programs that steer a population of smaller Follower LMs through efficient parallel inference to solve complex constrained generation tasks.
Core Problem
Language models struggle to perform complex reasoning or constrained generation using standard autoregressive decoding, and existing search methods (like Tree of Thoughts) require manual engineering for each new task.
Why it matters:
- Standard LMs often fail simple constraints (e.g., specific word counts or positioning) even when they 'know' the rules abstractly.
- Chain-of-Thought reasoning is serial, slow, and expensive, while hand-engineered search algorithms lack flexibility.
- Effective inference scaling requires bridging the gap between flexible natural language planning and rigorous, verifiable search procedures.
Concrete Example:
When asked to write a sentence with exactly 18 words where the 4th is 'Glasgow', a standard LM might write fluent text that violates the count. DISCIPL writes a program that explicitly forces 'Glasgow' at index 3 and tracks word counts programmatically.
Key Novelty
DISCIPL (Distributional Constraints by Inference Programming with Language Models)
- Separates reasoning into a 'Planner' (writes code) and a 'Follower' (executes code), allowing the model to design its own inference algorithm on the fly.
- Uses probabilistic programming to treat the Follower LM as a likelihood function, enabling precise constraints (like masking or hard constraints) to be enforced logically rather than hoping the model attends to them.
- Orchestrates parallel search (Sequential Monte Carlo) where the program kills low-probability drafts and resamples high-probability ones dynamically.
Architecture

Conceptual comparison of DISCIPL against standard serial (CoT) and parallel (Guess-and-Check) inference methods.
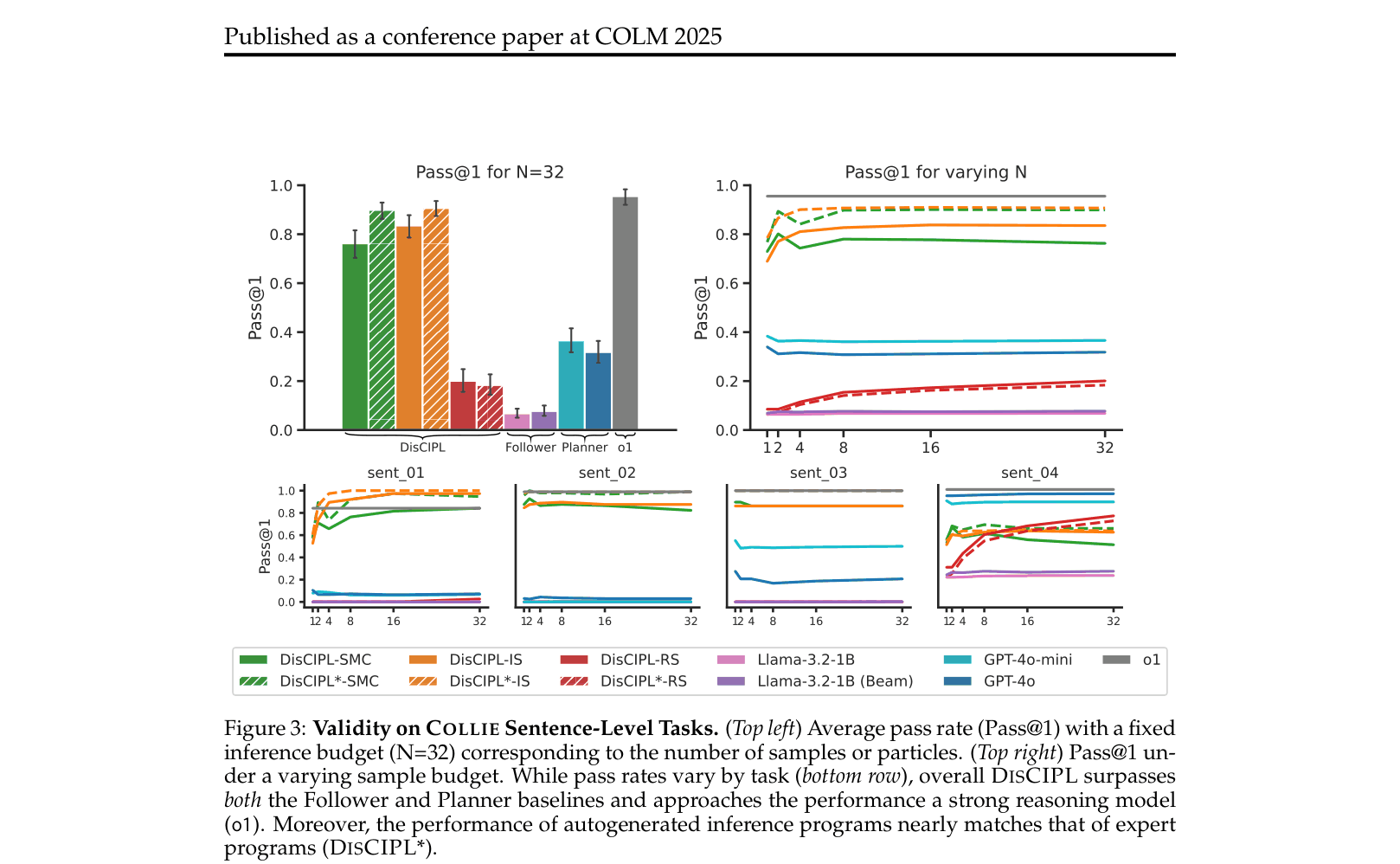
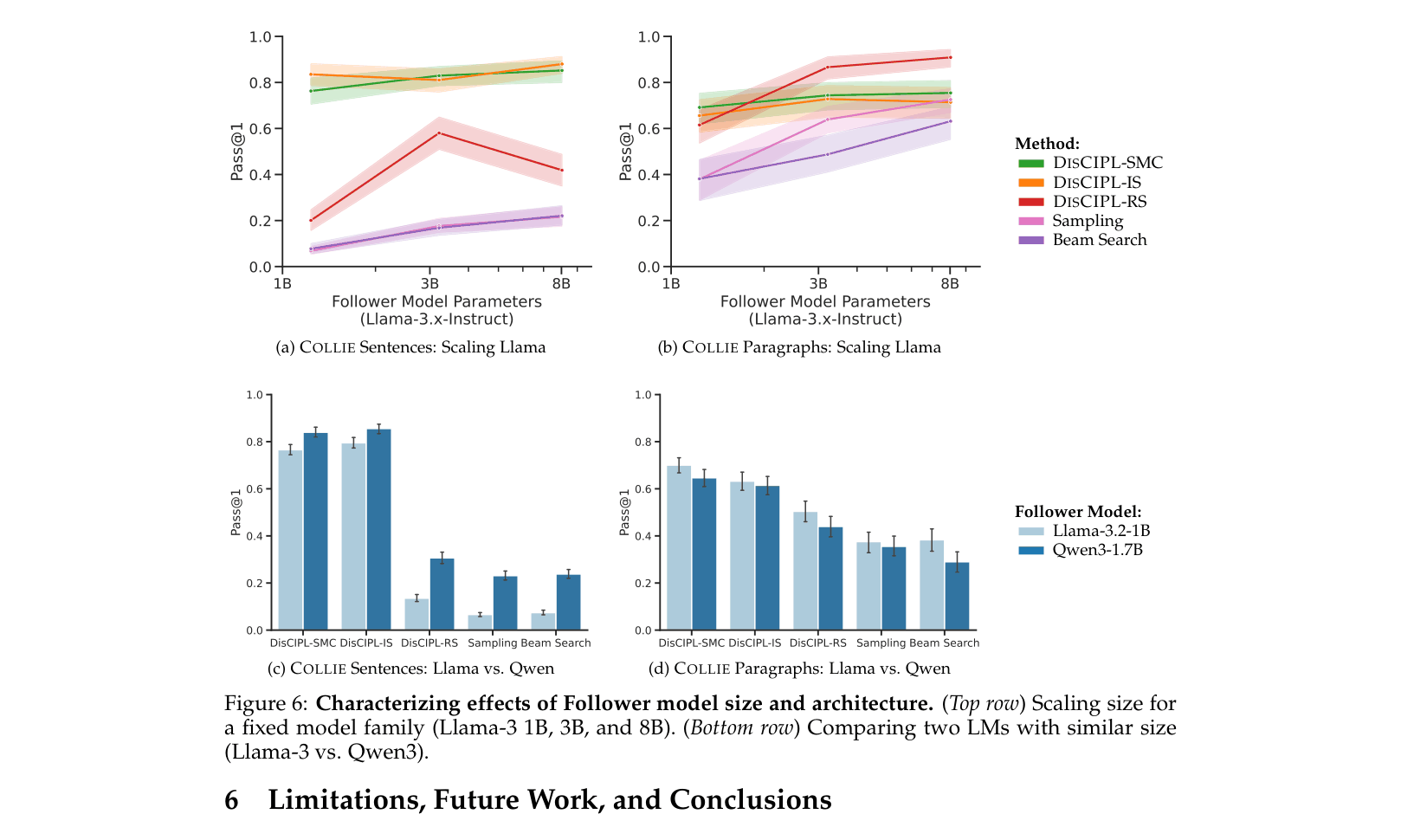
Evaluation Highlights
- On constrained paragraph generation, DISCIPL with a small Llama-3.2-1B model matches the performance of GPT-4o.
- On sentence-level constraints, DISCIPL enables Llama-3.2-1B (0.76 Pass@1) to far outperform its base capabilities (0.07 Pass@1) and approach reasoning models like o1 (0.96 Pass@1).
- SMC (Sequential Monte Carlo) inference consistently yields higher coherency than standard sampling at comparable validity rates by filtering out disfluent partial generations.
Breakthrough Assessment
8/10
Significant step in test-time compute. Effectively bridges code generation and probabilistic inference, allowing small models to punch way above their weight class on constrained tasks without fine-tuning.