📝 Paper Summary
Tool-use post-training
Multi-agent
ToolAlpaca automatically generates a diverse tool-use corpus via multi-agent simulation to enable compact language models to master generalized tool-use abilities without specific training on unseen tools.
Core Problem
Compact language models lack the generalized tool-use abilities of large models like GPT-4, and existing fine-tuning approaches are limited to specific, narrow tool scopes.
Why it matters:
- Current approaches either rely on closed-source giant models (GPT-4) or fail to generalize to unseen tools when using smaller open-source models.
- Constructing diverse, high-quality tool-use datasets manually is difficult due to the lack of available API scenarios and the complexity of multi-turn interactions.
Concrete Example:
Without training on the ToolAlpaca corpus, a Vicuna-7B model achieves only a 7.9% human acceptance rate on real-world APIs, failing to follow procedures or generate correct responses, whereas ToolAlpaca-7B reaches 63.2%.
Key Novelty
ToolAlpaca: Automated Tool-Use Corpus Generation via Multi-Agent Simulation
- Constructs a diverse toolset by using LLMs to generate structured documentation and OpenAPI specifications from brief real-world API descriptions.
- Generates training instances via a multi-agent simulation where a User Agent (generates instructions), Assistant Agent (selects tools), and Tool Executor Agent (simulates API outputs) interact autonomously.
Architecture
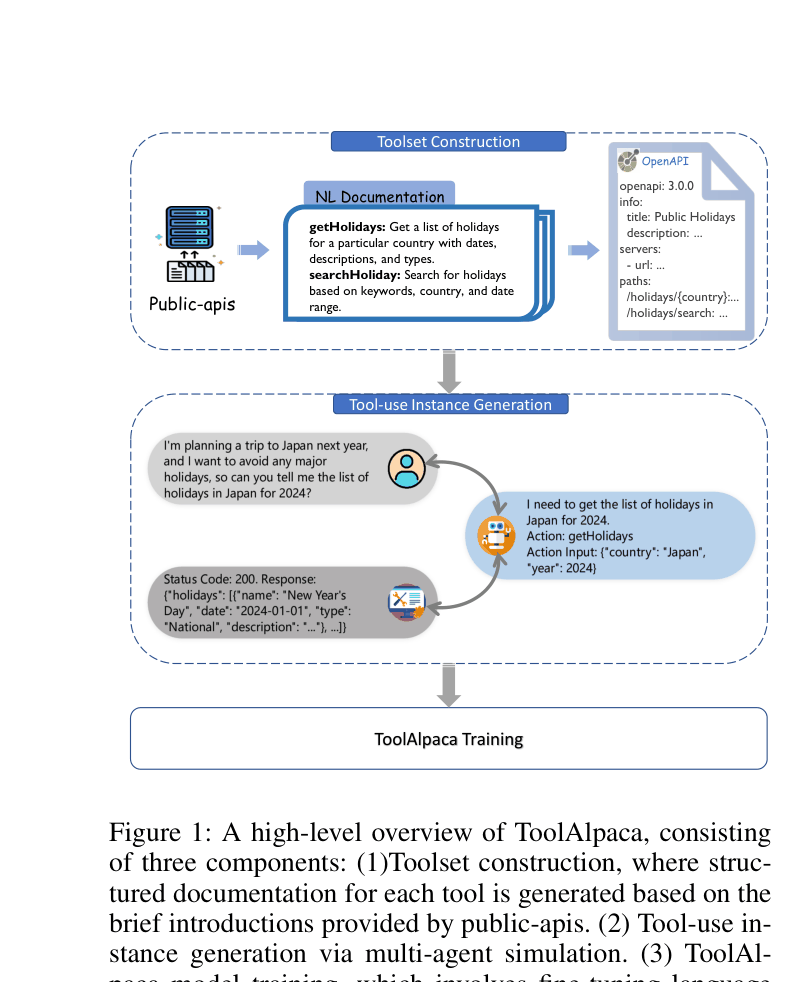
Overview of the ToolAlpaca framework, illustrating the pipeline from toolset construction to instance generation and model training.
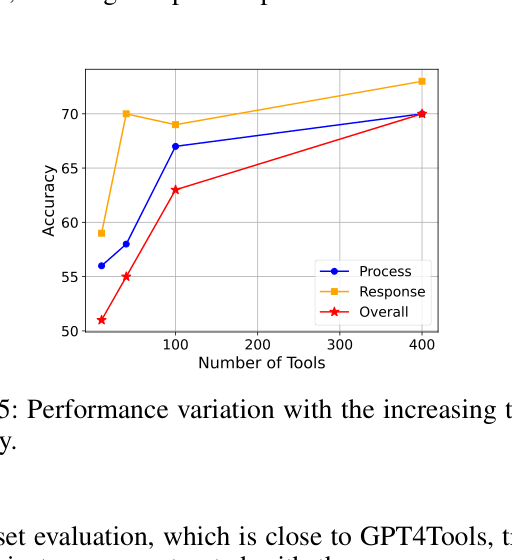
Evaluation Highlights
- ToolAlpaca-13B achieves a 75% overall acceptance rate on unseen simulated tools, matching the performance of GPT-3.5 (75%).
- On real-world APIs, ToolAlpaca-13B attains a 61.4% human acceptance rate, significantly outperforming the base Vicuna-13B model (12.3%).
- On the out-of-distribution GPT4Tools benchmark, ToolAlpaca-13B achieves an 83.7% success rate trained on only 3.9k cases, comparable to GPT4Tools (90.6%) which used 71k cases.
Breakthrough Assessment
8/10
Successfully demonstrates that compact models can learn generalized tool use from a small (3.9k), entirely simulated dataset, matching GPT-3.5 performance.