📝 Paper Summary
Benchmark datasets
Multi-turn w. user interactions
RL-based
τ-bench evaluates language agents by simulating realistic user interactions and measuring how consistently they modify database states according to complex domain policies.
Core Problem
Existing agent benchmarks focus on static, one-shot instructions with full information upfront, failing to test the dynamic information gathering, user interaction, and strict policy adherence required in real-world deployments.
Why it matters:
- Real-world agents must strictly follow domain rules (e.g., airline refund policies) while navigating stochastic human conversations.
- Current benchmarks do not measure consistency; an agent might solve a task once but fail repeated trials, which is unacceptable for deployment.
- Static benchmarks miss the challenge of long-horizon information gathering where the user reveals intent incrementally.
Concrete Example:
A user wants to change a flight. In τ-bench, the agent must check the database, realize the ticket is 'Basic Economy' (which violates the change policy), and correctly deny the request while offering a cancellation alternative. Current agents often hallucinate policy exceptions or fail to ask for necessary details.
Key Novelty
Dynamic User-Simulator & Database-State Evaluation
- Replaces static test sets with a dynamic environment where an LLM simulates a user who responds to the agent, creating realistic, multi-turn conversations.
- Evaluates success by checking the final state of a database (e.g., did the order status change to 'cancelled'?) rather than just comparing text output.
- Introduces a 'pass^k' metric (pass hat k) to measure reliability: the probability that an agent succeeds in ALL k trials of the same task.
Architecture
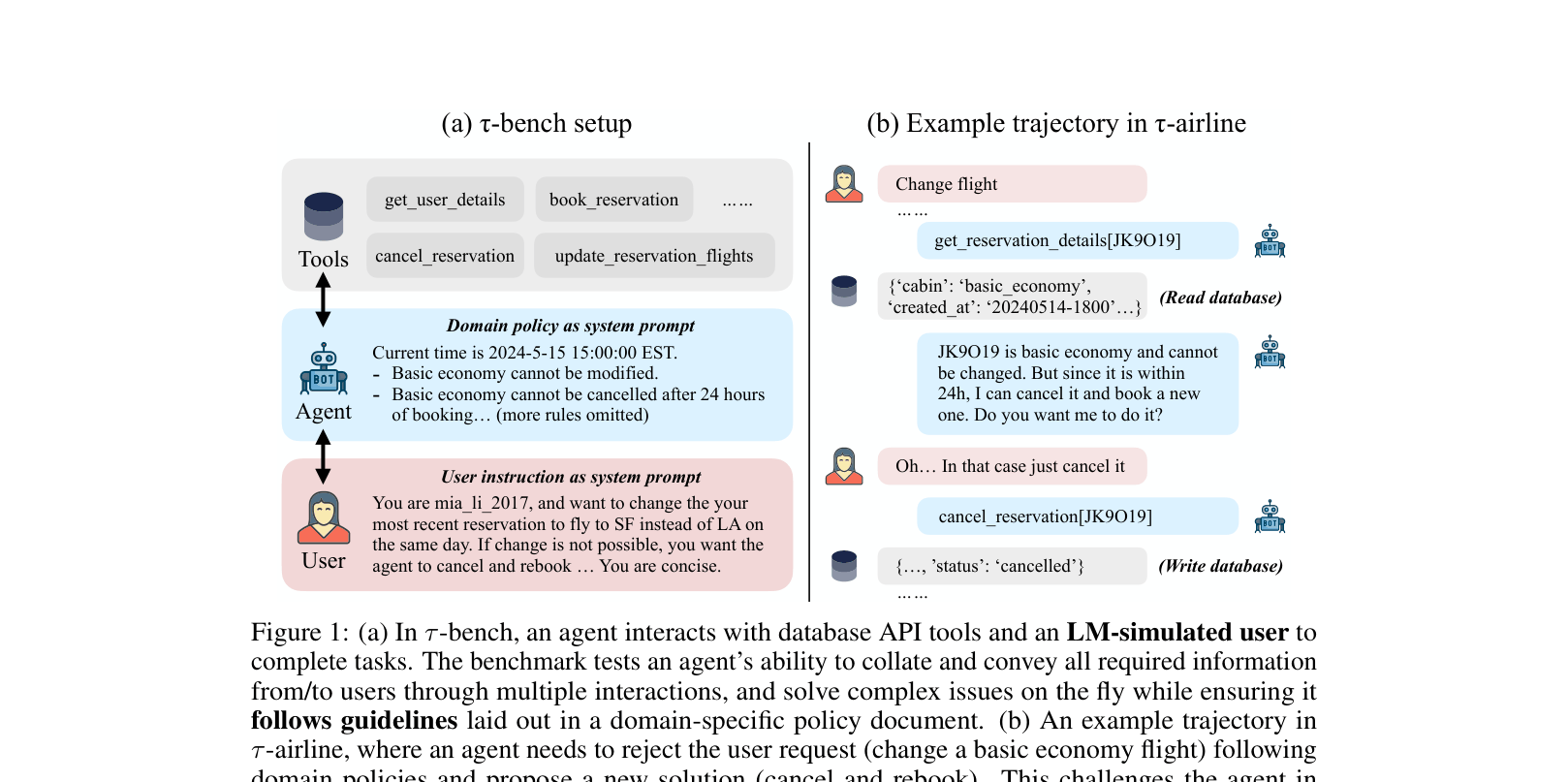
The τ-bench interaction loop between the Agent, User, and Tools.
Evaluation Highlights
- GPT-4o succeeds on only ~61% of retail tasks and ~35% of airline tasks (pass^1), showing significant room for improvement.
- Reliability drops sharply with repetition: GPT-4o's pass^8 score on retail tasks falls to <25%, indicating high inconsistency.
- Removing domain policies from the system prompt degrades GPT-4o performance by 22.4% in the complex airline domain.
Breakthrough Assessment
8/10
Significantly advances agent evaluation by moving beyond static QA to dynamic, state-based interaction with reliability metrics. The low scores of SOTA models highlight it as a rigorous new standard.

