📝 Paper Summary
Synthetic Data Generation for Agents
Tool-use post-training
ToolACE automates the creation of high-quality tool-learning data by evolving diverse synthetic APIs and generating dialogs where complexity is dynamically adjusted based on the target model's current capability.
Core Problem
Existing synthetic data pipelines for function calling lack API diversity and often generate samples that are either too simple or too complex for specific models, hindering effective generalization.
Why it matters:
- Real-world APIs are vast and rapidly changing, requiring models to generalize zero-shot rather than memorizing a small set of public APIs
- Models learn best when data complexity slightly exceeds their current capability; static datasets fail to provide this tailored curriculum
- Inaccurate or inconsistent synthetic data causes models to hallucinate parameters or misunderstand API constraints
Concrete Example:
A simple 0.5B model may be overwhelmed by data requiring long dependencies between APIs, while a 70B model learns nothing from straightforward single-turn queries. Standard pipelines generate fixed datasets that fail to address this gap, resulting in unproductive training for both.
Key Novelty
Self-Evolving Tool Synthesis and Self-Guided Complexity
- Tool Self-Evolution Synthesis (TSS): Synthesizes a massive pool of 26,507 diverse APIs by evolving them through a speciation-adaptation-evolution process rooted in an 'API context tree' derived from pre-training documents
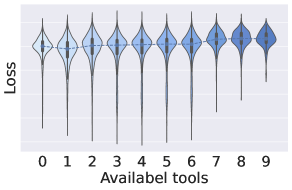
- Self-Guided Dialog Generation (SDG): Uses the target LLM itself as an evaluator to measure data complexity via loss; if a sample is too easy or hard, the generation agents adjust the query complexity dynamically
- Dual-Layer Verification (DLV): Combines rule-based checks (syntax, parameters) with model-based checks (hallucination, consistency) to ensure high data quality without expensive human annotation
Architecture
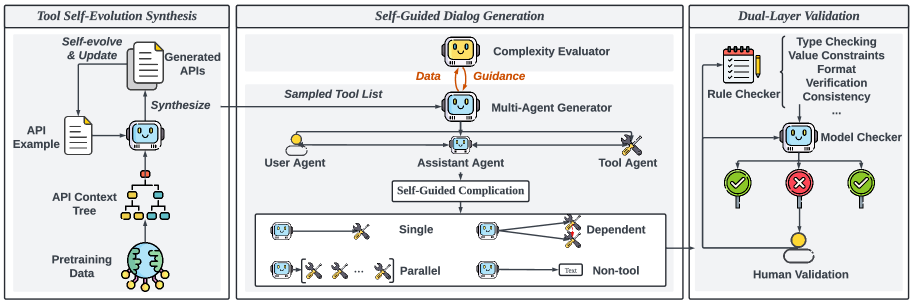
The overall ToolACE pipeline, illustrating the flow from API synthesis to dialog generation and verification.
Evaluation Highlights
- ToolACE-8B achieves 84.67% accuracy on the Berkeley Function Calling Leaderboard (BFCL), outperforming GPT-4-1106-Preview (83.25%) and Llama-3-8B-Instruct (77.83%)
- On APIBank (Level-1), ToolACE-8B reaches 76.51% accuracy, surpassing GPT-3.5-Turbo (72.24%) and largely outperforming the base Llama-3-8B (51.86%)
- In generalization tests (BFCL), ToolACE-8B outperforms the specialized ToolLLaMA-2-7B by a massive margin (84.67% vs 54.81%), demonstrating the value of diverse synthetic APIs
Breakthrough Assessment
9/10
Significantly advances synthetic data generation for agents by introducing evolutionary API synthesis and model-aware complexity control. The performance of an 8B model beating GPT-4 on specific benchmarks is a strong validation.