📝 Paper Summary
Synthetic Data Generation
Multi-turn w. user interactions
APIGen-MT generates high-quality multi-turn agent training data by first creating verified task blueprints and then simulating realistic human-agent conversations that strictly adhere to those blueprints.
Core Problem
Training effective agents for multi-turn interactions requires high-quality data capturing realistic dynamics, but such data is scarce, expensive to collect manually, and difficult to verify automatically.
Why it matters:
- Current LLMs (Large Language Models) struggle with complex function calls and tracking long-term dependencies in multi-turn conversations
- Existing synthetic methods focus mostly on single-turn interactions or lack the realistic human-agent interplay needed for robust training
- Without verification, synthetic multi-turn data is prone to error accumulation, where one hallucination derails the entire interaction trajectory
Concrete Example:
In a banking scenario, an agent might need to first authenticate a user, then check a balance, and finally transfer funds. Independently trained models often fail to maintain context across these steps, hallucinating parameters or forgetting the user's initial intent after the first tool call.
Key Novelty
Two-Phase Verified Synthesis: Blueprinting + Interaction Simulation
- Separates task design from conversation generation: Phase 1 creates a 'blueprint' (instruction + ground-truth actions + expected output) verified by an LLM committee and execution checks
- Phase 2 uses this blueprint to seed a simulated interaction between a 'Human' agent (who knows the goal but not the tools) and a 'Model' agent, ensuring the dialogue naturally reaches the verified outcome
Architecture
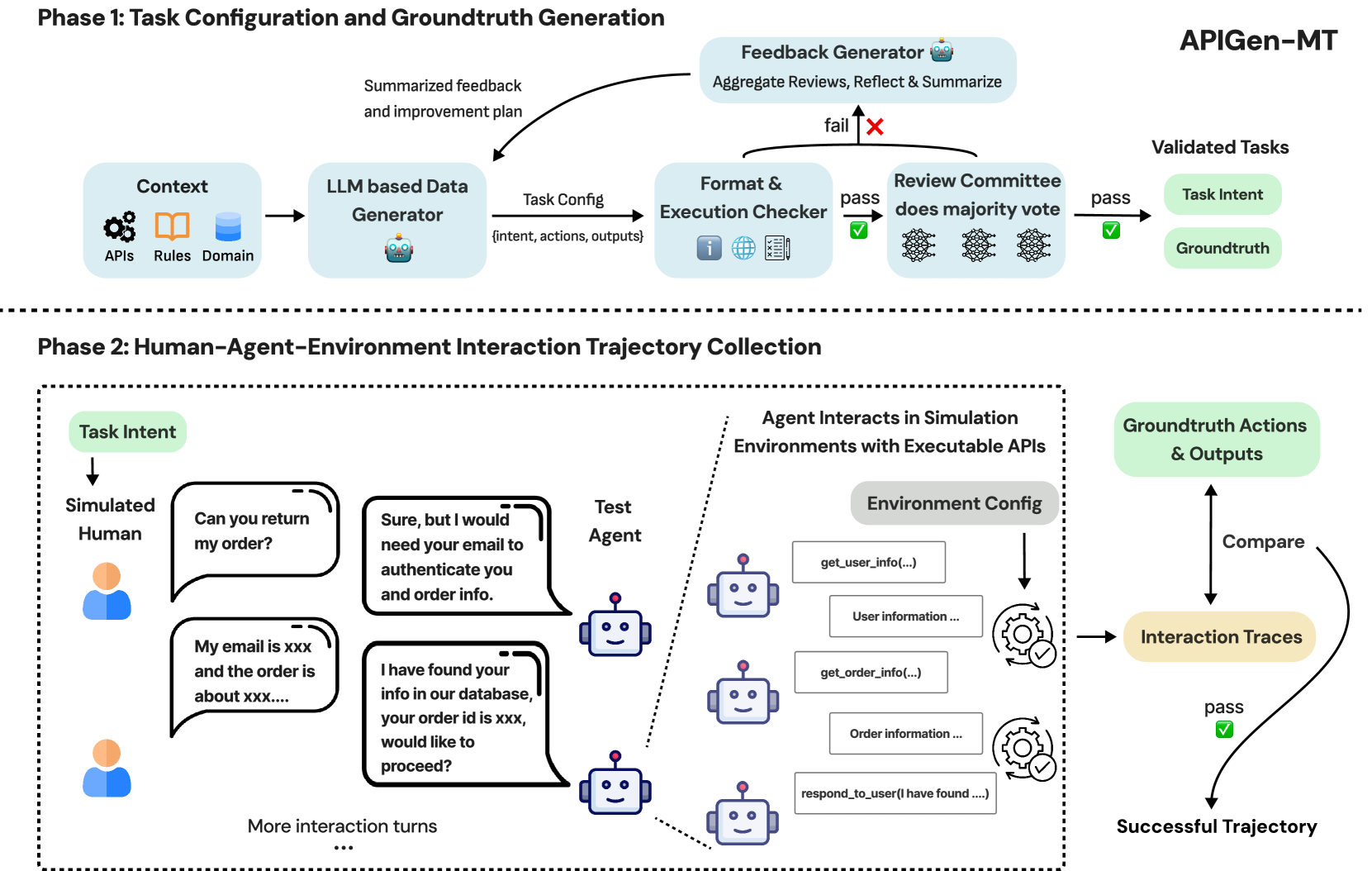
The complete APIGen-MT data synthesis pipeline, detailing the transition from context preparation to final dataset compilation.
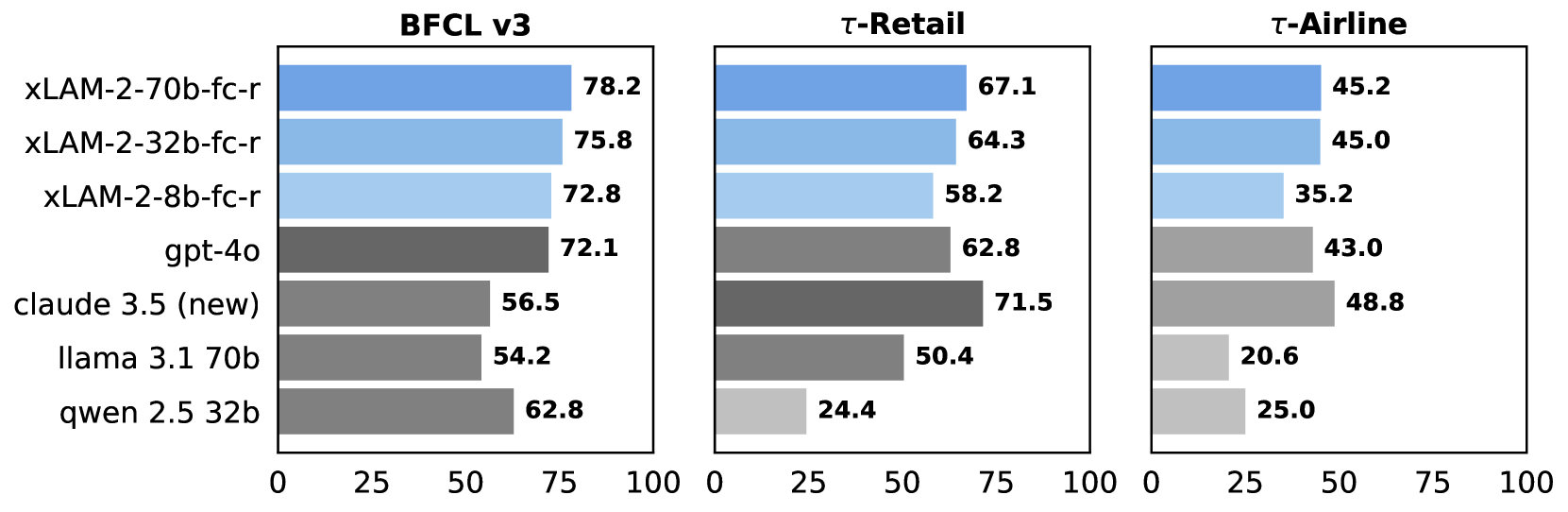
Evaluation Highlights
- Outperforms GPT-4o on the Tau-bench retail domain by +12.5% (success rate)
- Surpasses Claude 3.5 Sonnet on the BFCL (Berkeley Function Calling Leaderboard) multi-turn executable category by +3.54%
- Smaller 1B parameter model (xLAM-2-fc-r-1b) trained on this data outperforms the much larger Llama-3.1-70B-Instruct on Tau-bench airline tasks
Breakthrough Assessment
8/10
Significantly advances synthetic data generation by solving the verification bottleneck in multi-turn scenarios. The demonstrated ability of small models to beat frontier models using this data is highly impactful.