📝 Paper Summary
Tool-use post-training
RL-based
ReTool enhances LLM mathematical reasoning by integrating a sandboxed code interpreter directly into the RL rollout process, allowing the model to learn outcome-driven strategies for when and how to execute code.
Core Problem
Reasoning models like DeepSeek R1 struggle with tasks requiring precise calculation or symbolic manipulation (e.g., geometric reasoning) because pure textual chain-of-thought lacks reliable verification and computational power.
Why it matters:
- Text-based reasoning suffers from ambiguity and compounding errors in numerical steps
- Supervised tool-use methods are limited to imitating curated patterns and often fail to generalize or adaptively decide when to invoke tools
- Models need to autonomously discover optimal tool invocation patterns (e.g., self-correction) rather than relying on brittle human priors
Concrete Example:
In a complex equation solving task, a text-only model might hallucinate an intermediate calculation step, leading to a wrong final answer. ReTool, however, writes a code block to solve the equation, executes it in a sandbox, and uses the precise return value to continue reasoning.
Key Novelty
ReTool (Tool-augmented Reinforcement Learning)
- Integrates a code interpreter sandbox directly into the PPO rollout loop, allowing the policy to generate 'hybrid' traces containing text, code, and execution feedback
- Utilizes a cold-start data pipeline that converts textual reasoning steps into code-augmented traces to initialize the model before RL
- Optimizes tool-use strategy via outcome-based rewards, enabling emergent behaviors like code self-correction without explicit supervision on tool mechanics
Architecture
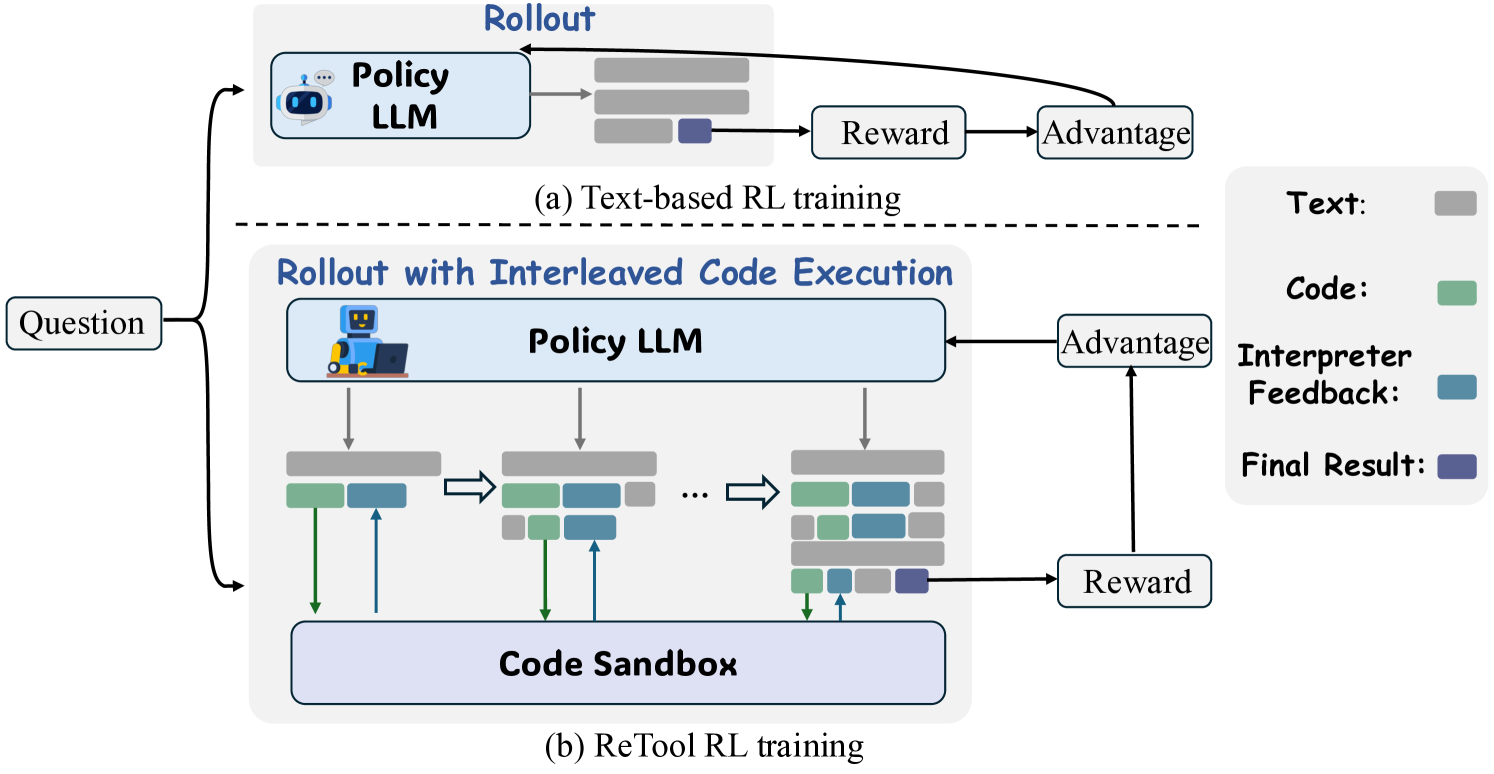
Comparison between Text-based Rollout and Tool-Integrated Rollout (ReTool). It illustrates how ReTool pauses generation to execute code and injects the output back into the context.
Evaluation Highlights
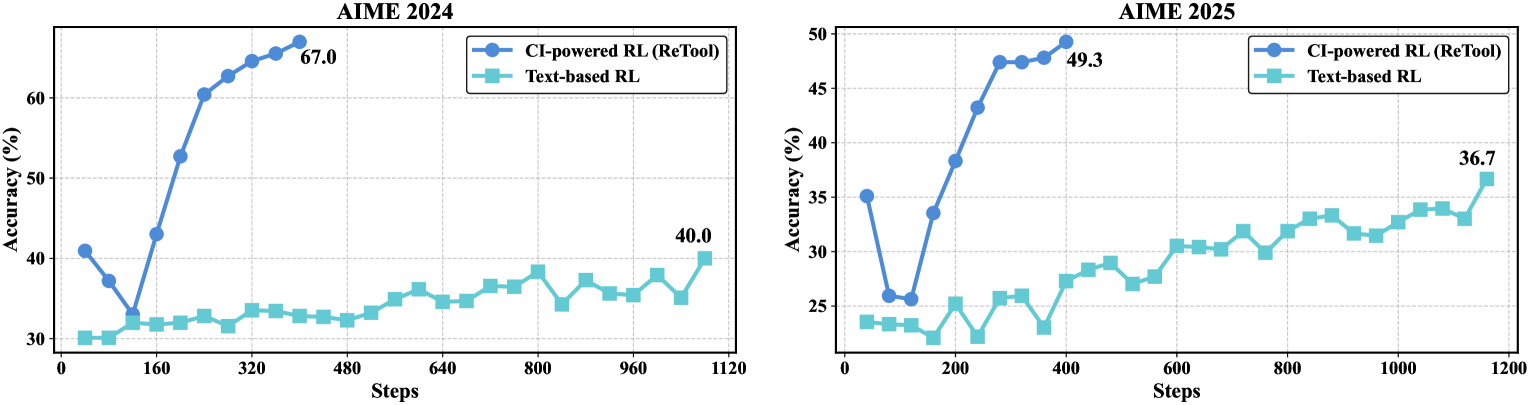
- +27.0% accuracy improvement on AIME 2024 (67.0% vs 40.0%) for Qwen2.5-32B-Instruct compared to text-based RL
- Surpasses OpenAI o1-preview by 27.9% on AIME extended settings using ReTool-32B
- Response length reduced by ~40% post-training, indicating higher efficiency when offloading computation to code
Breakthrough Assessment
8/10
Significant performance gains on hard math benchmarks (AIME) by successfully integrating code execution into the RL reasoning loop. Demonstrates emergent self-correction behavior.