📝 Paper Summary
RL-based tool use
Tool-use post-training
Tool-N1 trains language models to reason and use tools using rule-based reinforcement learning with a binary reward for format and functional correctness, eliminating the need for annotated reasoning trajectories.
Core Problem
Current tool-use training relies on supervised fine-tuning (SFT) with distilled trajectories, which often leads to superficial imitation of reasoning rather than genuine decision-making skills.
Why it matters:
- SFT models struggle to generalize beyond their training data, merely mimicking surface-level patterns
- Existing pipelines require expensive curation of step-by-step reasoning traces from stronger teacher models
- Models often fail to internalize the decision-making process, leading to fragile tool-calling behaviors
Concrete Example:
In supervised training, a model might learn to output a specific tool call sequence for a query like 'stock price of Apple' because it memorized the training example. If the argument order changes or the query is slightly different, the model fails. Tool-N1's RL approach rewards the functional result (dictionary match), allowing the model to learn that `{"symbol": "AAPL", "market": "US"}` is valid regardless of argument order.
Key Novelty
Rule-Based Reinforced Reasoning for Tool Use (Tool-N1)
- Apply R1-style reinforcement learning (GRPO) to tool calling, using a binary reward that checks only formatting and functional correctness (arguments/tool name)
- Eliminate the need for ground-truth reasoning traces during training; the model self-generates and optimizes its own reasoning process via trial and error
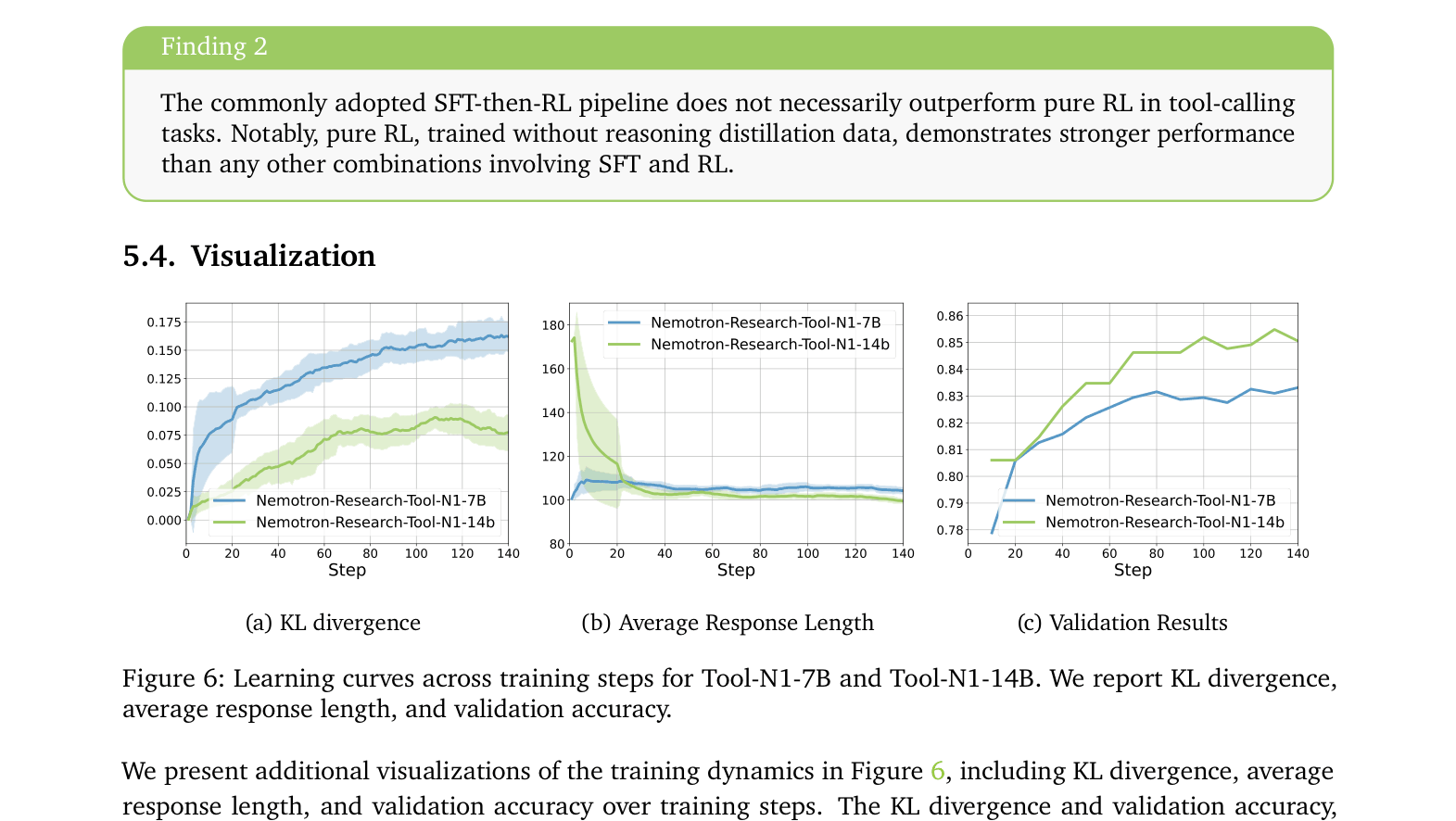
- Demonstrate that pure RL on tool outcomes outperforms the standard 'SFT followed by RL' pipeline for tool-use tasks
Architecture
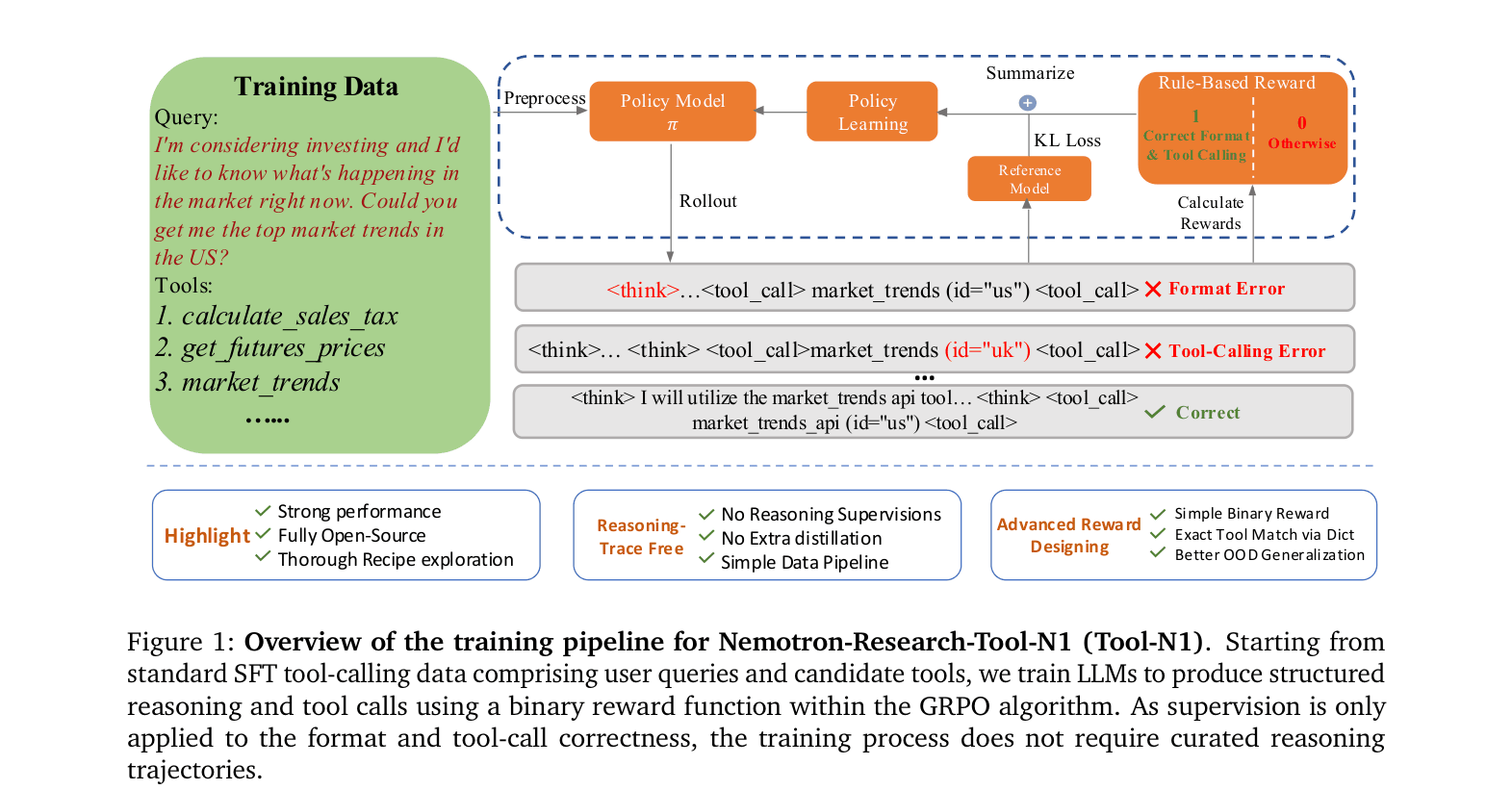
Overview of the training pipeline for Nemotron-Research-Tool-N1. It contrasts the standard SFT approach with the proposed RL approach.
Evaluation Highlights
- Tool-N1-14B outperforms GPT-4o on BFCL (85.97% vs 83.97%) and API-Bank (82.19% vs 77.16%) benchmarks
- Tool-N1-7B surpasses the closed-source GPT-4o on BFCL overall accuracy (84.82% vs 83.97%)
- Pure RL training achieves higher accuracy (83.24%) than the standard SFT-then-RL pipeline (83.17%) on the ToolACE dataset
Breakthrough Assessment
8/10
Successfully applies the 'DeepSeek-R1' reasoning paradigm to tool use, showing that SFT on reasoning traces is unnecessary and potentially suboptimal compared to pure RL. Strong empirical results outperforming GPT-4o.