📝 Paper Summary
Multi-call tool use with flexible plan
Closed-loop planning
AdaPlanner is a closed-loop agent that uses LLMs to generate code-based plans and adaptively refines them in response to environmental feedback without requiring auxiliary training.
Core Problem
Existing LLM agents are either open-loop (rigid plans that fail upon unexpected changes) or implicit closed-loop (correcting only the immediate action without updating the future plan), leading to myopia and error propagation.
Why it matters:
- Open-loop systems cannot handle dynamic environments where actions may fail or have unexpected outcomes
- Implicit closed-loop methods (like ReAct) make local adjustments but stick to an outdated high-level plan, leading to suboptimal long-term behavior
- Training-based plan refiners (like DEPS) require expensive task-specific data and struggle to generalize
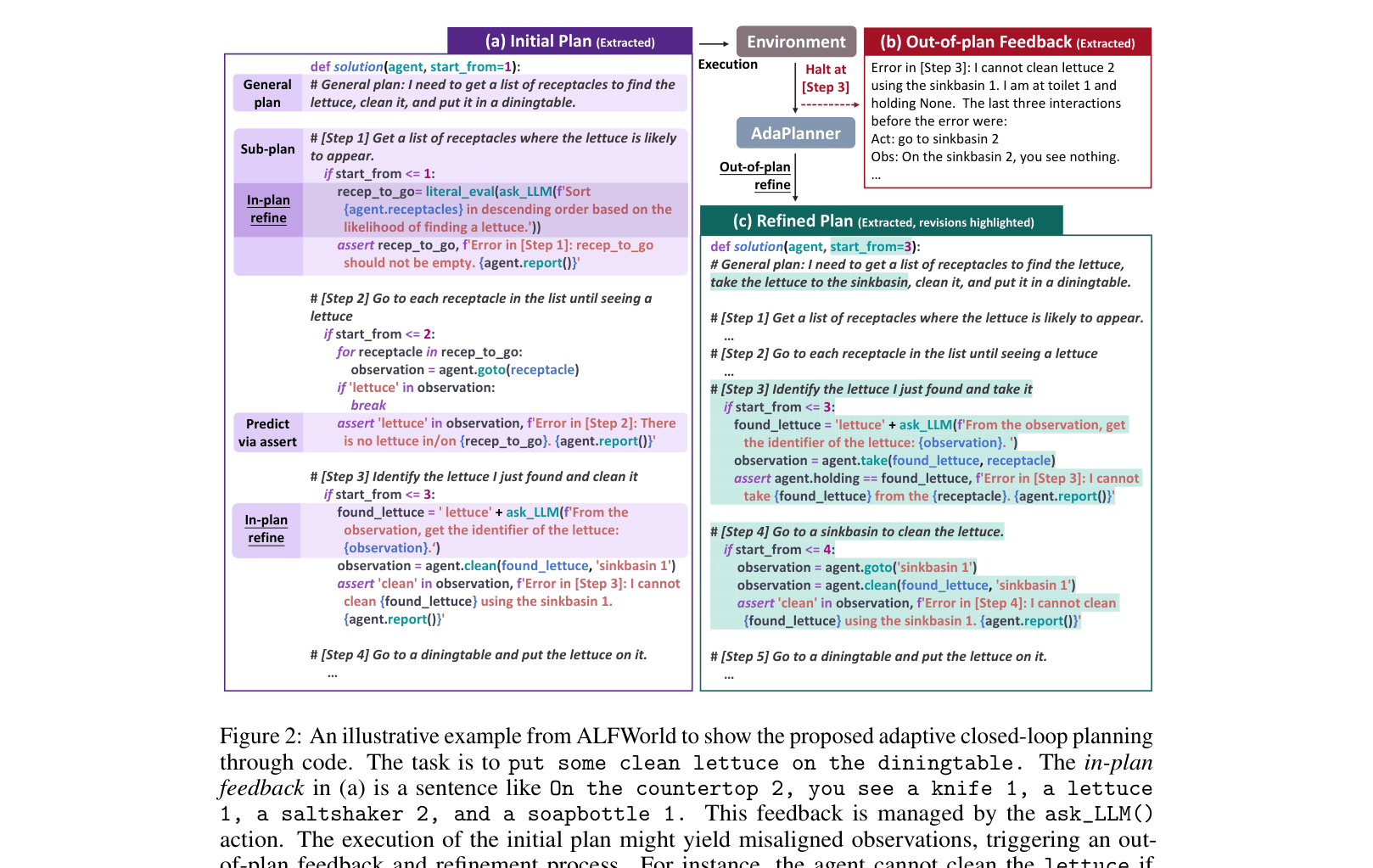
Concrete Example:
In a task to 'clean lettuce', an agent might try to clean it while holding it at a countertop. If the environment returns 'failure', an implicit agent might just retry. AdaPlanner recognizes the failure via an assertion, pauses, and rewrites the plan to first 'go to sinkbasin' before cleaning.
Key Novelty
Adaptive Closed-Loop Planning via Code and Skill Discovery
- Refine-then-resume: The agent generates plans as Python code with built-in assertions; when an assertion fails (out-of-plan feedback), it rewrites the entire future plan and resumes from that specific step rather than restarting
- Dual-role LLM: The LLM acts as both a planner (decomposing tasks) and a refiner (parsing observations via a special 'ask_LLM' function to extract key info for next steps)
- Skill Discovery: Successful plans are stored and used as few-shot exemplars for similar future tasks, reducing the need for extensive human demonstrations
Architecture
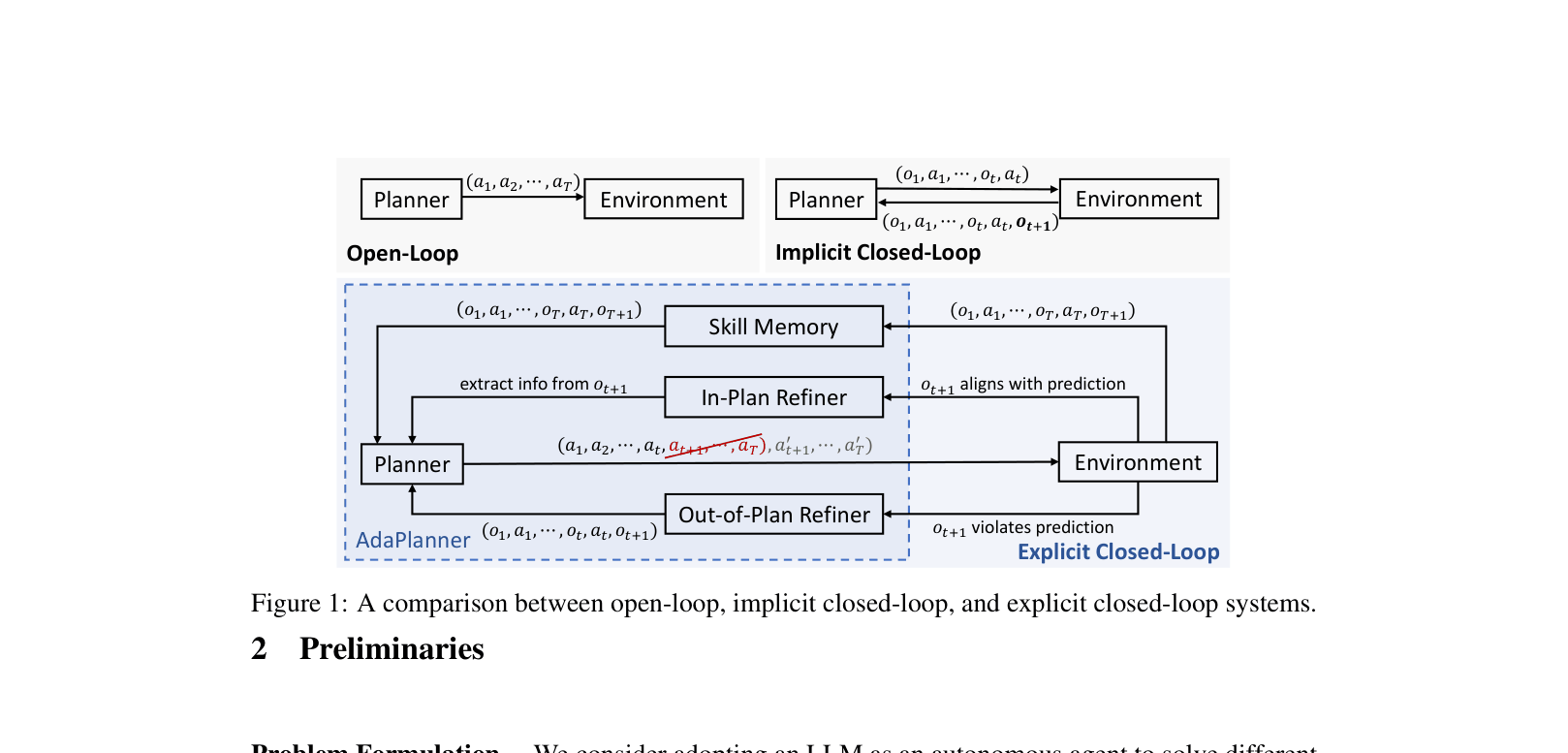
Comparison of Open-Loop, Implicit Closed-Loop, and AdaPlanner (Explicit Closed-Loop) architectures.
Evaluation Highlights
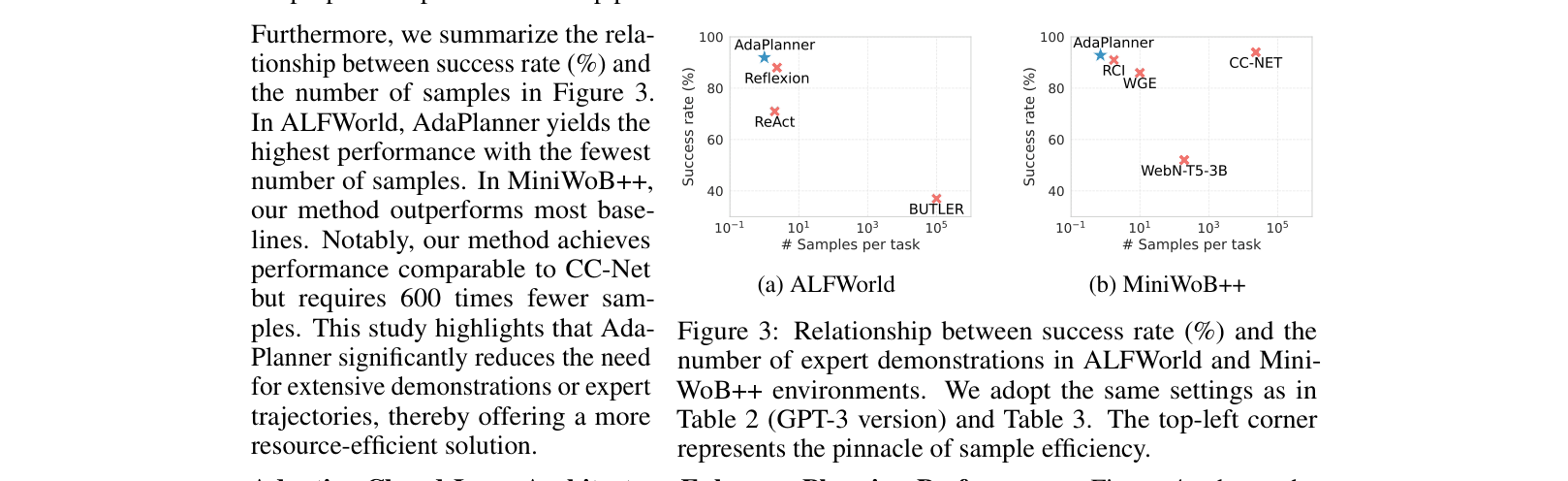
- +3.73% success rate improvement on ALFWorld compared to state-of-the-art baselines (Reflexion) while using 2x fewer samples
- 91.11% success rate on MiniWoB++ tasks with feedback, outperforming RCI and significantly outperforming fine-tuned models like WebN-T5-3B
- Maintains competitive performance (93.22%) on MiniWoB++ tasks without feedback, comparable to CC-Net but using ~600x fewer samples
- Resilient to hallucination: Code-based prompting reduces hallucinations compared to natural language baselines, especially with weaker models like GPT-3.5
Breakthrough Assessment
8/10
Significantly improves sample efficiency and reliability in sequential decision making by treating plans as code and allowing mid-episode correction. The refine-then-resume mechanism is a strong practical contribution.