📝 Paper Summary
Web agents
RL-based
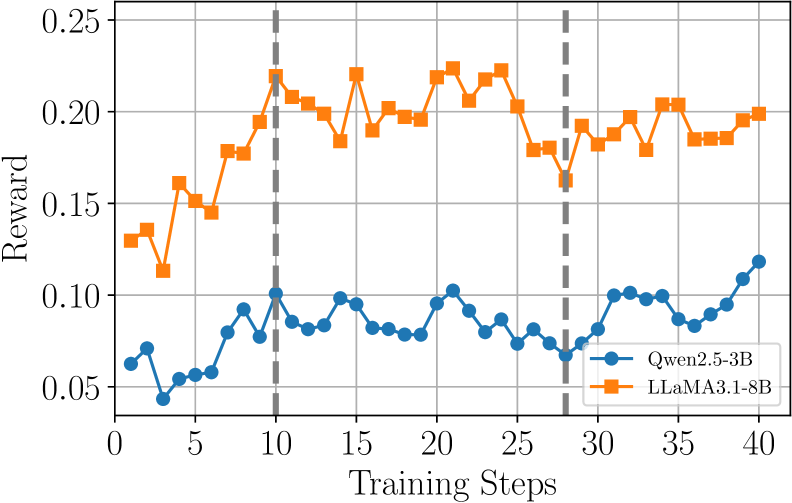
WebAgent-R1 trains web agents via end-to-end reinforcement learning directly from online interactions, using dynamic context compression and parallel rollouts to manage long horizons and sparse rewards.
Core Problem
Training effective web agents is challenging because web tasks involve long-horizon decision-making in dynamic environments where early actions (like logging out) irreversibly change the state, making offline data unreliable.
Why it matters:
- Existing RL for agents (e.g., math reasoning) focuses on single-turn tasks, failing to address the complexity of multi-step web interactions
- Prior web agents rely on prompting or behavior cloning, which lack exploration capabilities, or off-policy RL, which suffers from mismatch between the training data and current policy
- Complex dependencies (e.g., needing to log in before editing a profile) require agents to learn adaptively from their own current actions rather than static datasets
Concrete Example:
If an agent is tasked to log out and then edit a profile, these tasks are interdependent. An agent trained on off-policy data (where it never logged out) might try to access the profile after logging out, failing the task because it doesn't understand it lost access. End-to-end RL allows the agent to experience this failure and adjust.
Key Novelty
Multi-turn Group Relative Policy Optimization (M-GRPO) with Dynamic Context Compression
- Extends GRPO to multi-turn settings by generating groups of parallel trajectories online and updating the policy based on binary task success rewards
- Implements dynamic context compression that simplifies historical observations (e.g., replacing old HTML with a placeholder) to fit long interaction histories into memory
- Uses parallel trajectory rollouts across multiple independent browser instances to efficiently gather diverse experience data for the group-based updates
Architecture
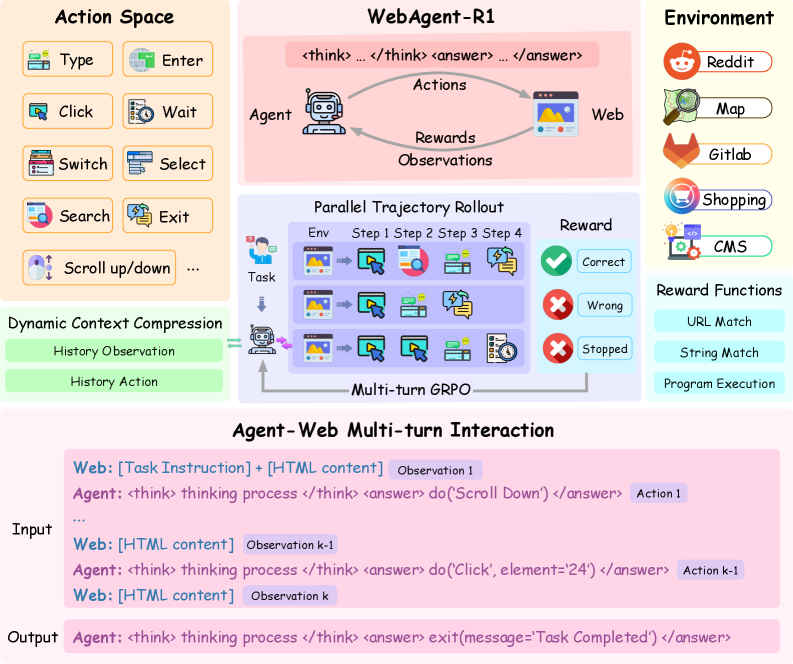
The end-to-end multi-turn RL framework. It shows the flow from Environment -> SFT Policy -> M-GRPO with two key mechanisms: Dynamic Context Compression and Parallel Trajectory Rollout.
Evaluation Highlights
- Boosts Qwen-2.5-3B success rate from 6.1% (base) to 33.9% on WebArena-Lite, significantly outperforming the Behavior Cloning baseline (20.0%)
- Llama-3.1-8B improves from 8.5% (base) to 44.8% with WebAgent-R1, surpassing OpenAI o3 (39.4%) and GPT-4o (16.4%)
- Demonstrates effective test-time scaling: increasing interaction turns consistently improves success rates across prompting, SFT, and RL methods
Breakthrough Assessment
8/10
Significant performance jump over strong proprietary models (like o3) using much smaller open models. Successfully applies on-policy RL to complex, long-horizon web tasks, addressing key memory and stability challenges.