📝 Paper Summary
Agentic RAG pipeline
Multi-call tool use with flexible plan
ReAct prompts language models to alternate between generating internal reasoning traces and external actions, allowing them to dynamically update plans and gather information to solve complex tasks.
Core Problem
Language models separate reasoning (like Chain-of-Thought) from acting (like WebGPT), causing hallucinations in reasoning tasks and inefficient planning in interactive tasks.
Why it matters:
- Chain-of-thought reasoning suffers from fact hallucination and error propagation because it is not grounded in the external world.
- Action-only models struggle with long-horizon goals and exception handling because they lack a mechanism to maintain and update high-level plans.
- Combining both capabilities is essential for general intelligence that can learn new tasks quickly and handle unseen circumstances.
Concrete Example:
In HotpotQA, a reasoning-only model hallucinates that 'Apple Remote was designed to control Apple TV' (wrong). An act-only model searches 'Apple Remote' but fails to synthesize the finding that it controls 'Front Row'. ReAct reasons about what to search ('search Apple Remote'), executes the search, reads the observation ('controls Front Row'), and updates its plan to search for 'Front Row' next.
Key Novelty
Interleaved Thought-Action Loop (ReAct)
- Augments the action space to include 'thoughts'—free-form language steps that do not affect the environment but update the context for future steps.
- Prompts the model to generate a sequence of Thought → Action → Observation, enabling dynamic planning (reason to act) and information incorporation (act to reason).
Architecture

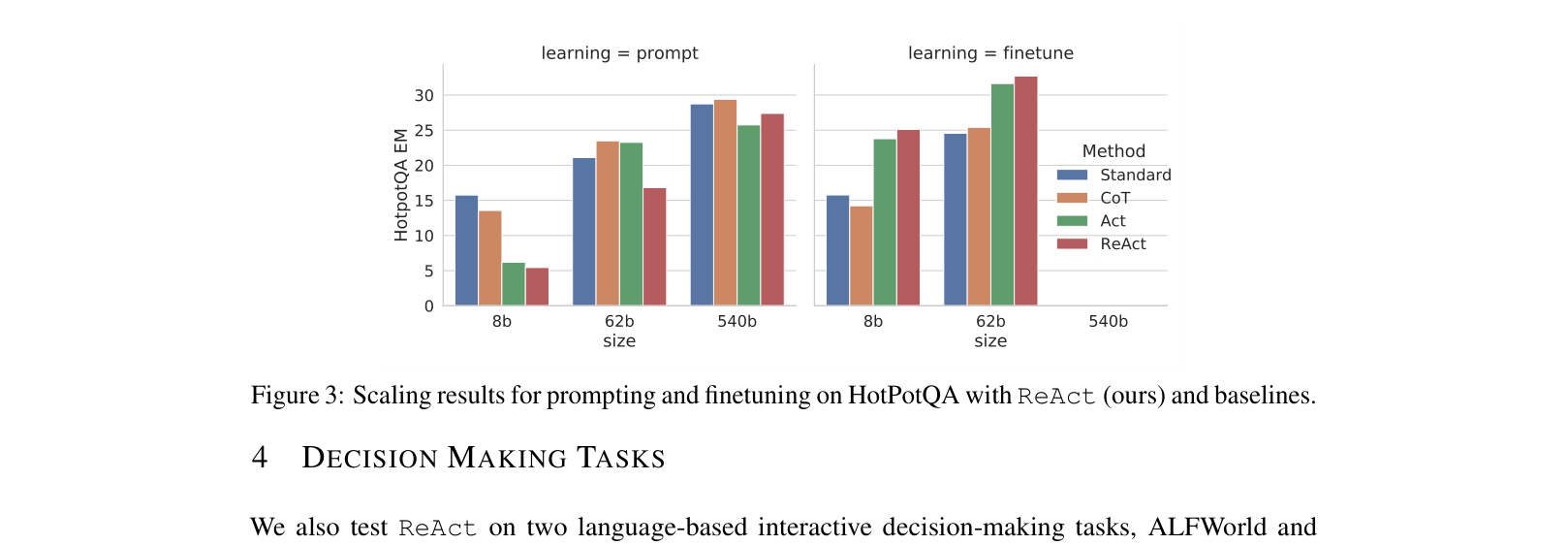
Comparison of four prompting methods (Standard, CoT, Act-only, ReAct) on HotpotQA and ALFWorld.
Evaluation Highlights
- Outperforms imitation and reinforcement learning baselines on ALFWorld (text game) by 34% (absolute success rate) with only two in-context examples.
- Improves success rate on WebShop (online shopping) by 10% absolute over imitation learning baselines using one-shot prompting.
- Reduces hallucination rates in HotpotQA compared to Chain-of-Thought (6% vs 14% false positives) by grounding reasoning in external Wikipedia retrievals.
Breakthrough Assessment
9/10
Seminal paper that established the standard paradigm for LLM agents. It moved the field from static reasoning (CoT) to dynamic agentic loops, influencing almost all subsequent agent frameworks.