📝 Paper Summary
Tool-use post-training
Invoking internalized APIs
Toolformer enables language models to teach themselves when and how to use external tools by generating, filtering, and fine-tuning on their own API calls using a self-supervised perplexity loss.
Core Problem
Large language models struggle with basic functions like arithmetic, factual lookups, and time awareness, but existing tool-use methods rely on expensive human annotation or task-specific constraints.
Why it matters:
- Language models hallucinate facts and lack access to up-to-date information on recent events
- Standard scaling does not resolve limitations in mathematical skills or low-resource language understanding
- Reliance on human annotation limits the generality and scale of tool adoption in LMs
Concrete Example:
When asked 'Who is the publisher of The New England Journal of Medicine?', a standard LM might hallucinate, whereas Toolformer autonomously calls '[QA("Who is the publisher...?")]' to retrieve 'Massachusetts Medical Society' and complete the text correctly.
Key Novelty
Self-Supervised API Bootstrapping
- The model uses in-context learning to sample potential API calls within raw text, then executes them to get results
- Calls are filtered based on whether providing the API result reduces the model's perplexity (loss) on future tokens compared to not having the result
- The model fine-tunes on its own useful, filtered predictions, learning to invoke tools implicitly without human supervision
Architecture
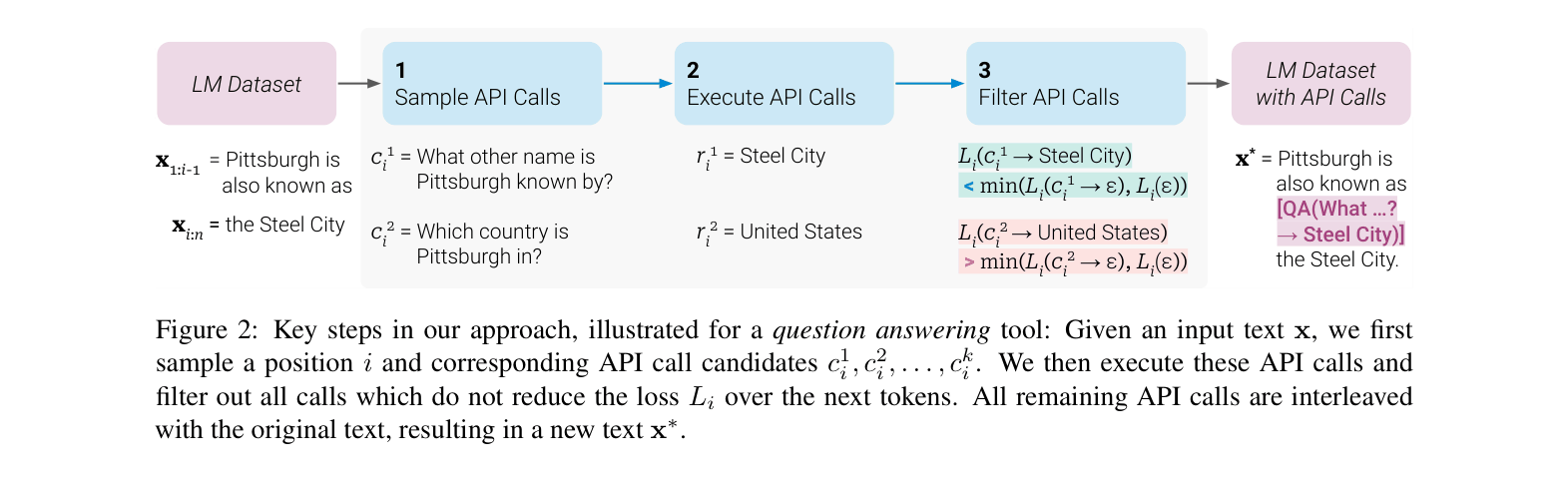
The self-supervised annotation process for creating the Toolformer dataset.
Evaluation Highlights
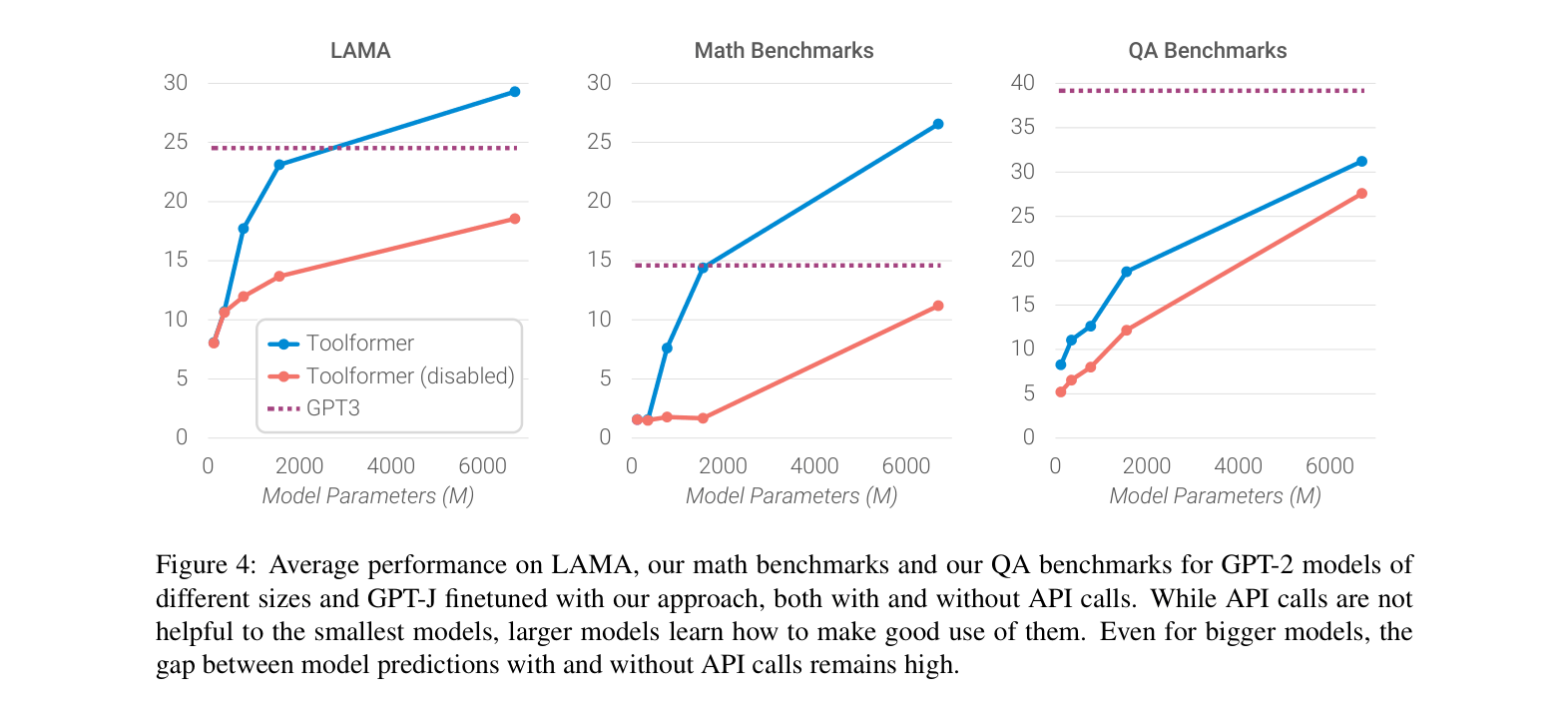
- Outperforms the much larger GPT-3 (175B) on LAMA (factual probing) by 13.7 points (53.5 vs 39.8) using a 6.7B model
- Achieves 40.4% accuracy on ASDiv math benchmark, nearly 3x the performance of GPT-3 (14.0%) in zero-shot settings
- Triples temporal fact performance on DATESET (27.3 vs 0.8 for GPT-3) by leveraging a calendar tool
Breakthrough Assessment
9/10
Pioneered a scalable, self-supervised method for generalized tool use. It demonstrated that smaller models with tools can beat massive models, shifting the paradigm from 'bigger is better' to 'smarter tool use'.