📝 Paper Summary
Multi-call tool use with fixed plan
Tool-use post-training
The paper boosts open-source LLMs' tool use capabilities to rival GPT-4 by aligning them with programmatically generated API data, using retrieval-based demonstrations, and enforcing code-only generation.
Core Problem
Open-source LLMs severely lag behind closed APIs like GPT-4 in tool manipulation, often failing to select correct APIs, populating wrong arguments, or generating non-executable text.
Why it matters:
- Relying on closed APIs (GPT-4) poses security and privacy risks for enterprise adoption, as internal workflows must be exposed to external services
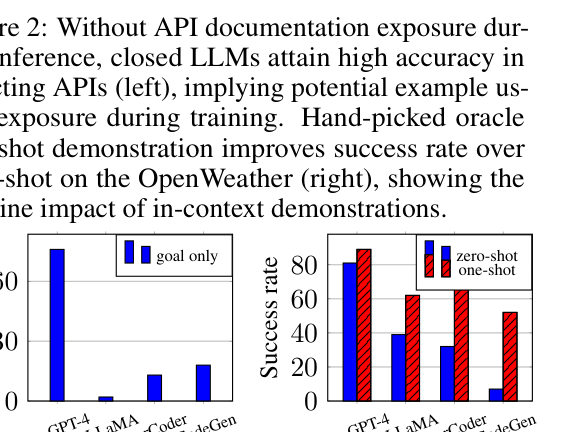
- There is a huge performance disparity: LLaMA fails completely (0%) on a house searching tool where GPT-4 achieves 77%, hindering open-source adoption
- Open-source models struggle with API hallucinations and argument formatting without specific alignment, unlike closed models that seemingly internalize this during training
Concrete Example:
In a weather query task, when asked 'how to move a robot to (20, 30)?', an open-source model might hallucinate 'robot.raise_arm(20)' (wrong API) or 'robot.move_to(30, 20)' (wrong arguments), whereas GPT-4 correctly generates 'robot.move_to(20, 30)'.
Key Novelty
Programmatic Alignment & Retrieval for Tool Use (ToolBench Recipe)
- Bootstrap training data programmatically by creating a few templates per tool and filling them with random values, requiring minimal human effort (approx. 1 day per tool)
- Align open-source models on this synthetic data to internalize API signatures and usage patterns
- Augment inference with a 'demonstration retriever' that fetches relevant few-shot examples based on goal similarity, handling unseen API combinations
Architecture
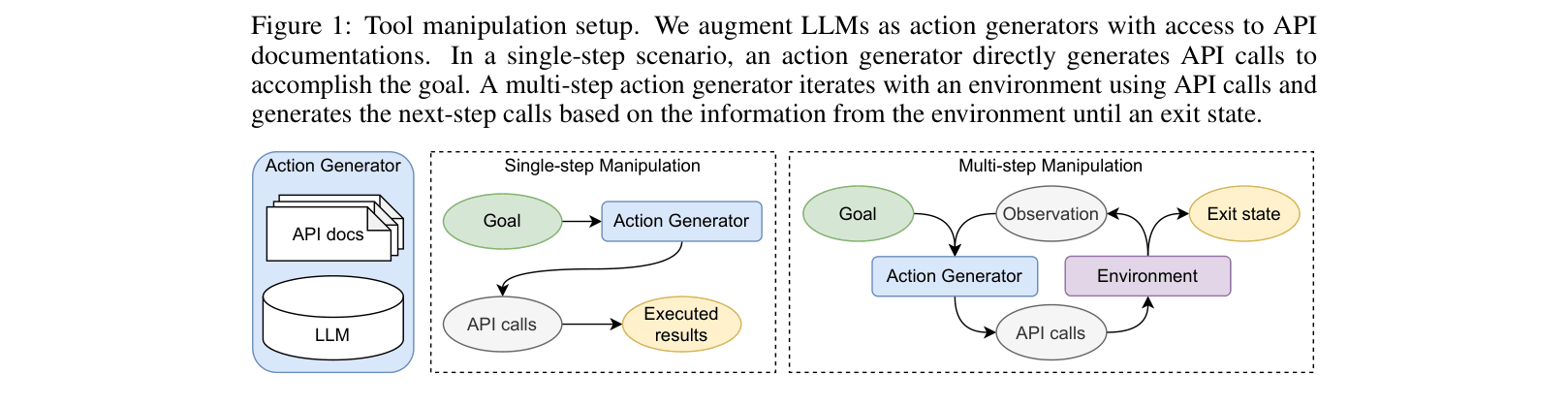
The tool manipulation setup illustrating both single-step and multi-step scenarios.
Evaluation Highlights
- Boosted open-source LLMs (LLaMA-30b, StarCoder) achieve competitive or better success rates than GPT-4 in 4 out of 8 ToolBench tasks
- Enhanced LLaMA-30b improves from 0% to 87% success rate on the Home Search task, narrowing the gap with enhanced GPT-4 (98%)
- Programmatic alignment and retrieval techniques boost open-source success rates by up to 90% compared to out-of-the-box zero-shot performance
Breakthrough Assessment
7/10
Significant for demonstrating that open-source models can bridge the gap to GPT-4 in tool use with low-cost synthetic data, though they still struggle on reasoning-heavy tasks.