📝 Paper Summary
Multi-call tool use with flexible plan
Tool profiling
Gorilla is a LLaMA-based model fine-tuned on a massive dataset of API documentation (APIBench) to generate accurate, constraint-aware API calls while reducing hallucination.
Core Problem
LLMs struggle to effectively use tools via API calls, often hallucinating non-existent libraries or generating incorrect input arguments when faced with massive, changing API sets.
Why it matters:
- Existing tool-use approaches rely on small, hand-coded sets of APIs in prompts, which cannot scale to the millions of changing cloud APIs needed for real-world tasks
- Hallucinating API calls leads to runtime errors and unreliable system behavior, preventing LLMs from acting as the primary interface to computing infrastructure
- LLMs must adapt to frequent updates in API documentation without requiring full retraining
Concrete Example:
When asked to 'Help me find an API to convert the spoken language... using Torch Hub', GPT-4 hallucinates a non-existent model (torch.hub.load('snakers4/silero-models', 'asr')), and Claude selects the wrong library (Torchaudio), whereas Gorilla correctly identifies 'silero_sst'.
Key Novelty
Retriever-Aware Fine-Tuning for Massive API Usage
- Constructs APIBench, a comprehensive dataset of ML APIs (TorchHub, TensorHub, HuggingFace) with synthetic instructions generated via Self-Instruct
- Fine-tunes LLaMA-7B on instruction-API pairs augmented with retrieved API documentation, teaching the model to parse documentation to answer user queries
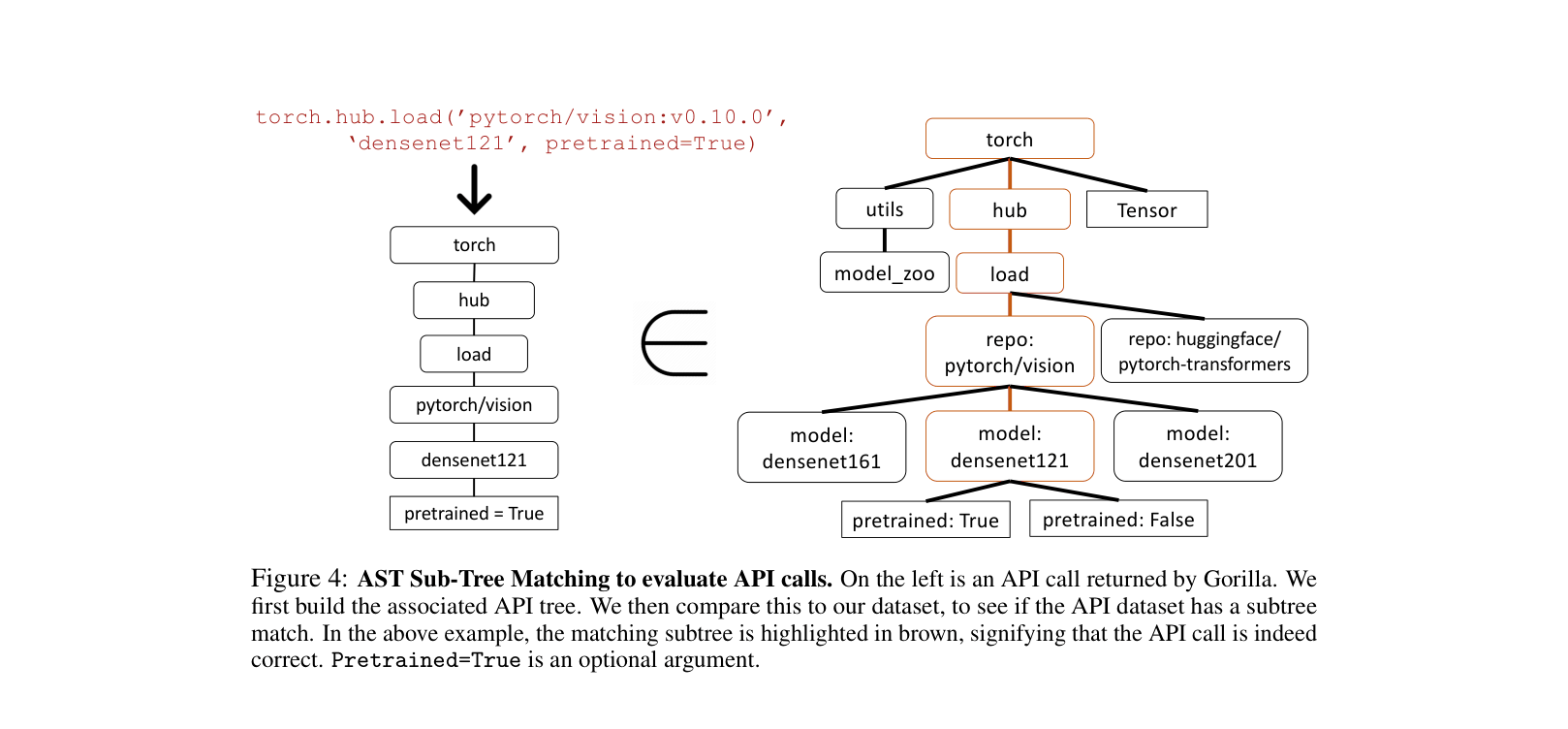
- Evaluates using AST (Abstract Syntax Tree) sub-tree matching to verify functional correctness rather than just string matching
Architecture
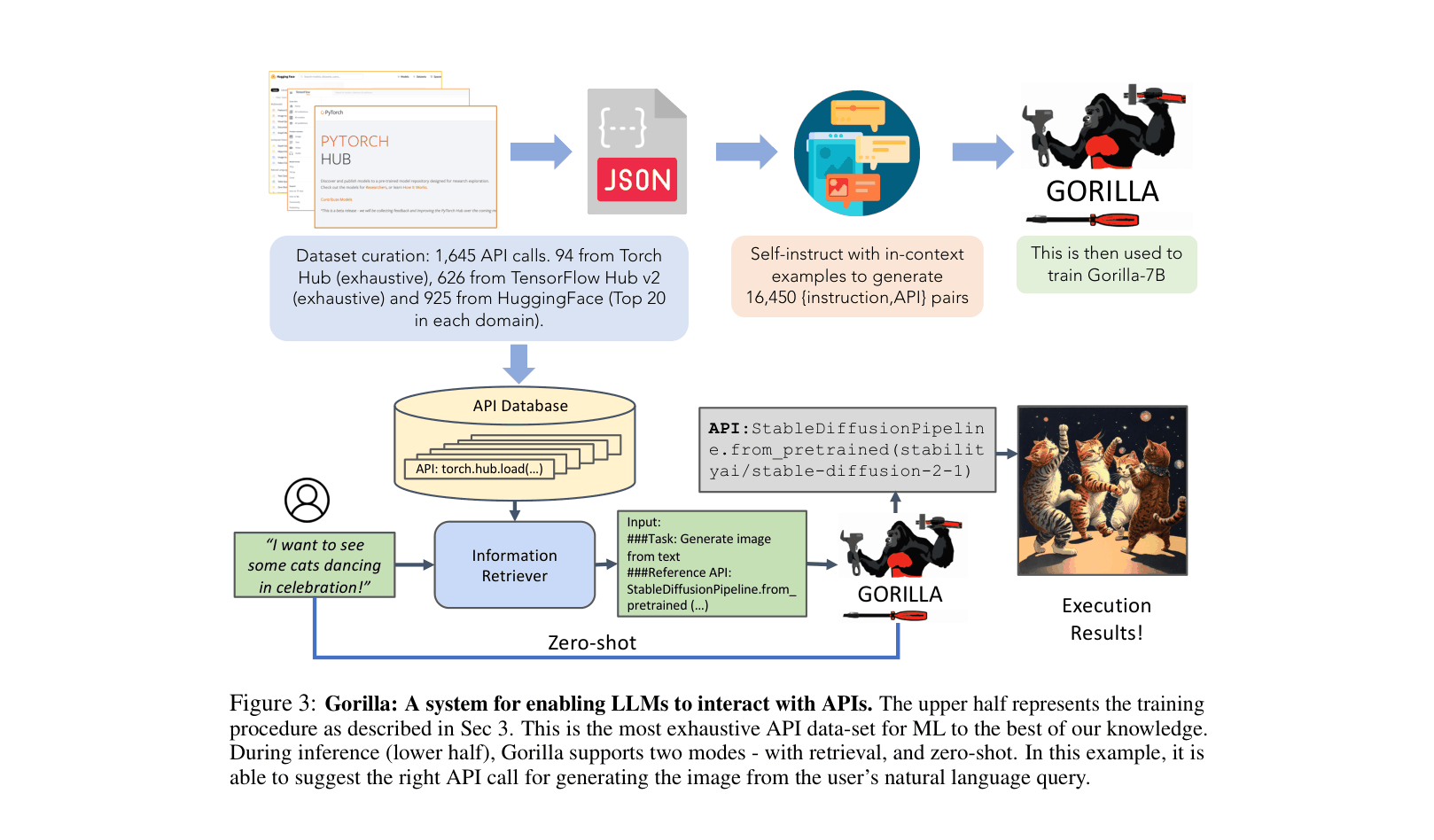
The end-to-end pipeline for Gorilla, covering dataset collection, Self-Instruct fine-tuning, and inference modes (zero-shot vs. retrieval-augmented).
Evaluation Highlights
- Gorilla (0-shot) achieves 83.79% accuracy on TensorHub, significantly outperforming GPT-4 (18.20%) and Claude (9.19%)
- Reduces hallucination errors to near zero (0% on TorchHub with Oracle retriever) compared to GPT-4's 36.55% hallucination rate in zero-shot settings
- Adapts to test-time API changes (e.g., version updates) via retrieval-aware training, unlike static models that fail when documentation evolves
Breakthrough Assessment
9/10
Pioneering work in scaling LLM tool use to massive numbers of APIs via fine-tuning rather than just prompting. Establishes a major benchmark (APIBench) and demonstrates superior performance over GPT-4.