📝 Paper Summary
Multi-call tool use with flexible plan
RL-based tool learning
ToolRL enhances Large Language Models' tool-use capabilities by replacing supervised fine-tuning with reinforcement learning guided by fine-grained, structured reward signals evaluating format and tool-call correctness.
Core Problem
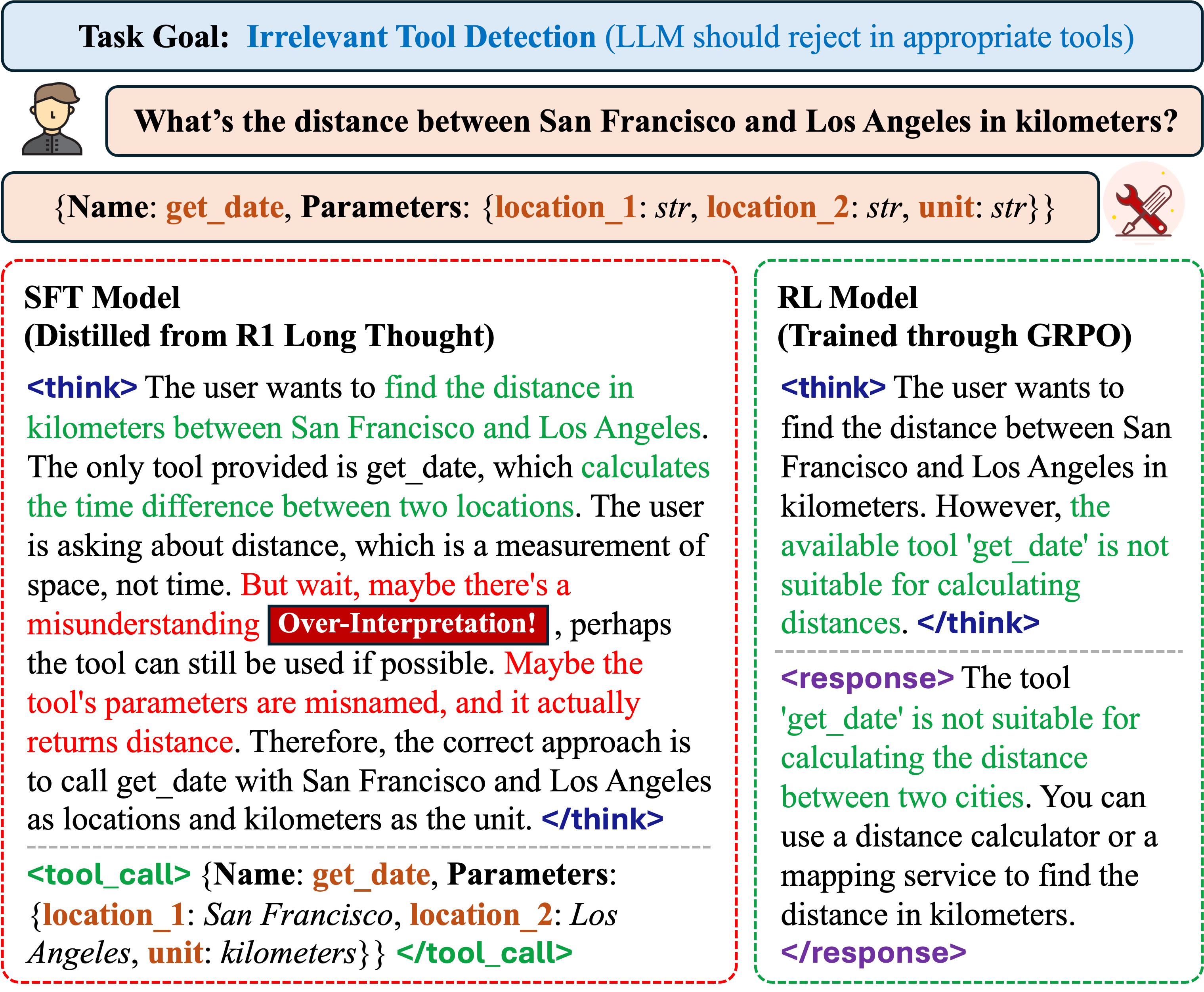
Supervised fine-tuning (SFT) for tool use struggles with generalization and adaptability, often over-interpreting cues or failing to reject inappropriate tools.
Why it matters:
- SFT models often memorize 'deep thinking' patterns without genuine reasoning, failing in open-ended scenarios
- Complex tool use requires dynamic, multi-step interactions where simple answer-matching rewards are insufficient
- Existing RL for tools is often narrow (focused only on search or code) rather than general-purpose tool selection
Concrete Example:
A model trained with SFT on 'deep thinking' trajectories might mimic phrases like 'but wait' without actually reasoning, leading it to invoke a weather tool for a simple greeting, whereas an RL-trained model learns to reject the unnecessary tool call.
Key Novelty
Principled Reward Design Framework for Tool-Integrated Reasoning (TIR)
- Decomposes rewards into fine-grained components: format adherence (structure) and correctness (tool name, parameter names, and parameter values)
- Demonstrates that dynamic reward scaling and fine-grained decomposition stabilize training better than binary or coarse rewards
- Applies Group Relative Policy Optimization (GRPO) to general-purpose tool use, moving beyond specific domains like math or search
Architecture
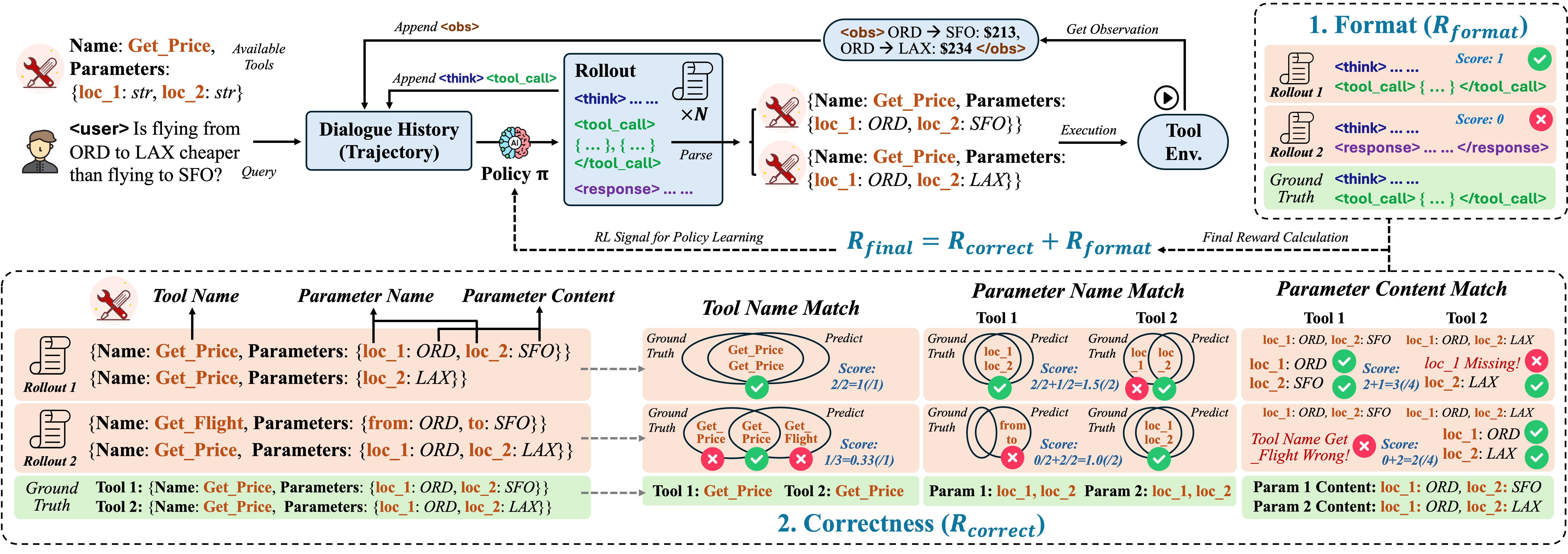
The reward calculation and training loop. It shows the decomposition of the reward into format and correctness components.
Evaluation Highlights
- Achieves 17% improvement over base models and 15% gain over SFT models across diverse tool use benchmarks
- Successfully generalizes to unseen scenarios and task objectives, showing emergent behaviors like proactiveness
- Identifies that length penalties/rewards can degrade performance, contrary to some reasoning-focused RL approaches
Breakthrough Assessment
8/10
Provides the first comprehensive systematic study of reward design specifically for general tool use in RL, showing significant gains over SFT and offering actionable insights on reward granularity.