📝 Paper Summary
Benchmark datasets
Tool-use post-training
Multi-call tool use with flexible plan
API-Bank is a benchmark for evaluating tool-augmented LLMs that measures planning, retrieving, and calling abilities, accompanied by a multi-agent synthetic data generation method to train a capable model called Lynx.
Core Problem
Existing LLM benchmarks lack a comprehensive evaluation of tool usage capabilities (planning, retrieving, calling) and often rely on limited or unrealistic API sets.
Why it matters:
- Current LLMs (like GPT-3) struggle with API usage without specific instruction tuning, limiting their ability to interact with the real world.
- Manual annotation of diverse tool-use dialogues is prohibitively expensive ($8 per dialogue), hindering the creation of large-scale training sets.
- There is a lack of standardized metrics to measure the gap between open-source models and state-of-the-art closed models (like GPT-4) in complex tool-use scenarios.
Concrete Example:
When a user asks a complex question requiring multiple steps (e.g., 'Check my calendar and book a flight if free'), a standard LLM might hallucinate a response or fail to sequence the APIs correctly. In API-Bank, the model must first retrieve the 'Calendar' API, check availability, then retrieve the 'Flight' API and book it, managing dependencies between these calls.
Key Novelty
API-Bank Benchmark & Lynx Model
- Defines a three-level evaluation grading system for tool use: Call (standard slot filling), Retrieval+Call (finding the right tool), and Plan+Retrieval+Call (multi-step reasoning).
- Introduces a 'Multi-agent' data generation pipeline where five LLM agents collaborate to synthesize diverse domains, APIs, and dialogues, reducing annotation costs by 98%.
- Implements an executable evaluation system with 73 real APIs and databases to measure correctness based on actual execution results rather than just text matching.
Architecture
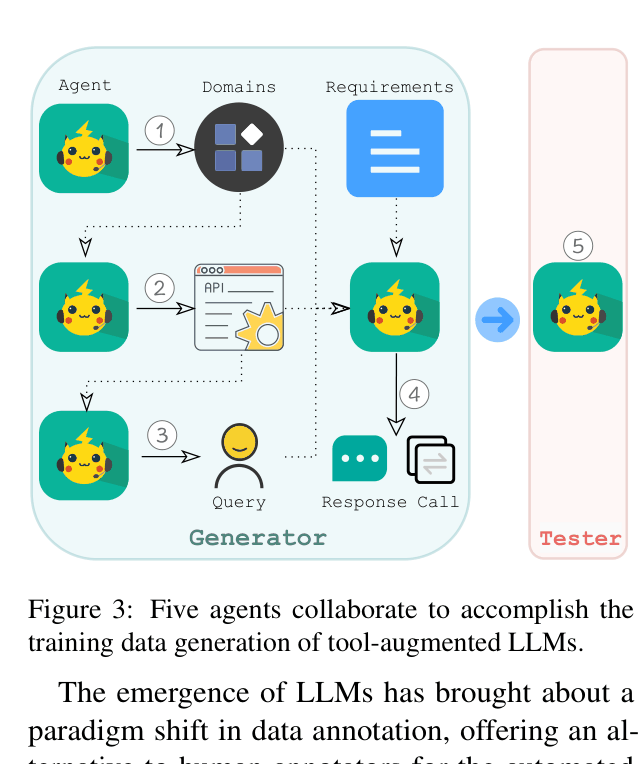
The Multi-agent data generation pipeline used to create the training set.
Evaluation Highlights
- Lynx (initialized from Alpaca-7B) achieves 49.87% accuracy on API calls, surpassing Alpaca-7B by ~26 percentage points and approaching GPT-3.5-turbo (59.40%).
- GPT-4 significantly outperforms GPT-3.5 on the hardest 'Plan+Retrieve+Call' task (70.00% vs 22.00% accuracy), showing superior reasoning capabilities.
- The Multi-agent data generation method reduces cost to $0.10 per dialogue (vs. $8 for human annotation) while maintaining a 94% data availability rate.
Breakthrough Assessment
8/10
A comprehensive benchmark that addresses the critical gap in evaluating tool-augmented LLMs. The executable environment and multi-level ability grading set a new standard, though the primary model (Lynx) is a 7B fine-tune rather than a new architecture.