📝 Paper Summary
Tool-use post-training
Multi-call tool use with flexible plan
ToolLLM empowers open-source models to master thousands of real-world APIs by constructing a massive instruction-tuning dataset via ChatGPT and a novel depth-first search reasoning strategy.
Core Problem
Open-source LLMs lag behind closed-source models (like ChatGPT) in using external tools because current instruction tuning overlooks complex, real-world API interactions.
Why it matters:
- Closed-source models have opaque mechanisms, limiting community innovation and democratization of AI agents
- Existing tool-use datasets are limited in scale, diversity (often ignoring real-world RESTful APIs), and reasoning complexity (mostly single-tool scenarios)
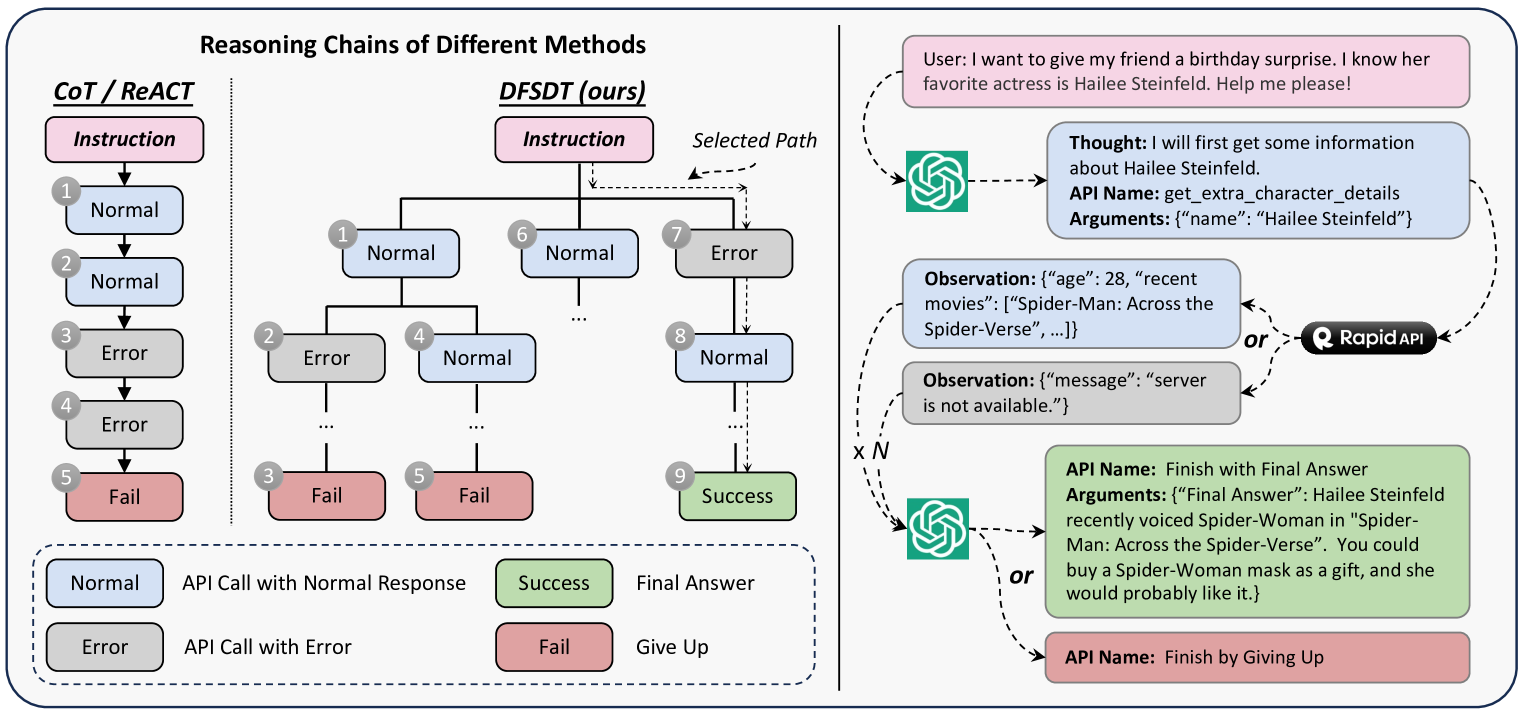
- Standard reasoning methods like ReACT (Reasoning and Acting) or CoT (Chain-of-Thought) struggle with complex planning, often getting trapped in error loops or limited exploration
Concrete Example:
When asked to 'find a movie and book a ticket,' a standard model might fail if the first API call returns an error, getting stuck in a loop. ToolLLM's search-based method allows it to backtrack and try a different API or parameter, finding a valid path where linear reasoning fails.
Key Novelty
ToolBench Dataset & DFSDT (Depth-First Search-based Decision Tree)
- Constructs a massive dataset (ToolBench) by scraping 16,464 real APIs and using ChatGPT to automatically generate instructions and valid solution paths
- Replaces linear reasoning (ReACT) with a decision tree (DFSDT) that allows the model to explore multiple reasoning branches, backtrack from dead ends, and prune bad paths during data annotation
- Includes a neural API retriever to handle the large search space of thousands of potential tools before the LLM plans the execution
Architecture
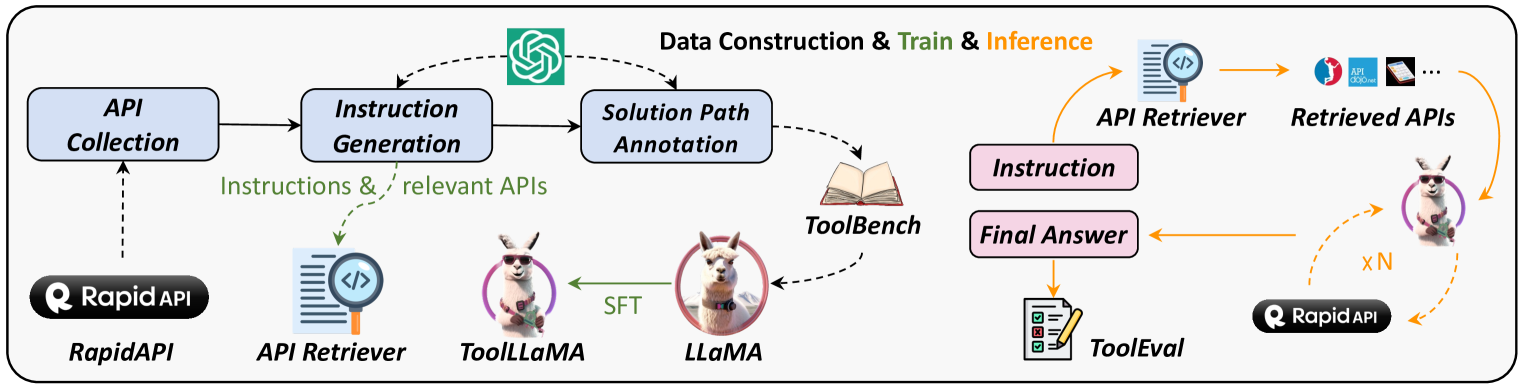
The overall framework of ToolLLM, including the three stages: Data Construction (ToolBench), Model Training (ToolLLaMA), and Evaluation (ToolEval).
Evaluation Highlights
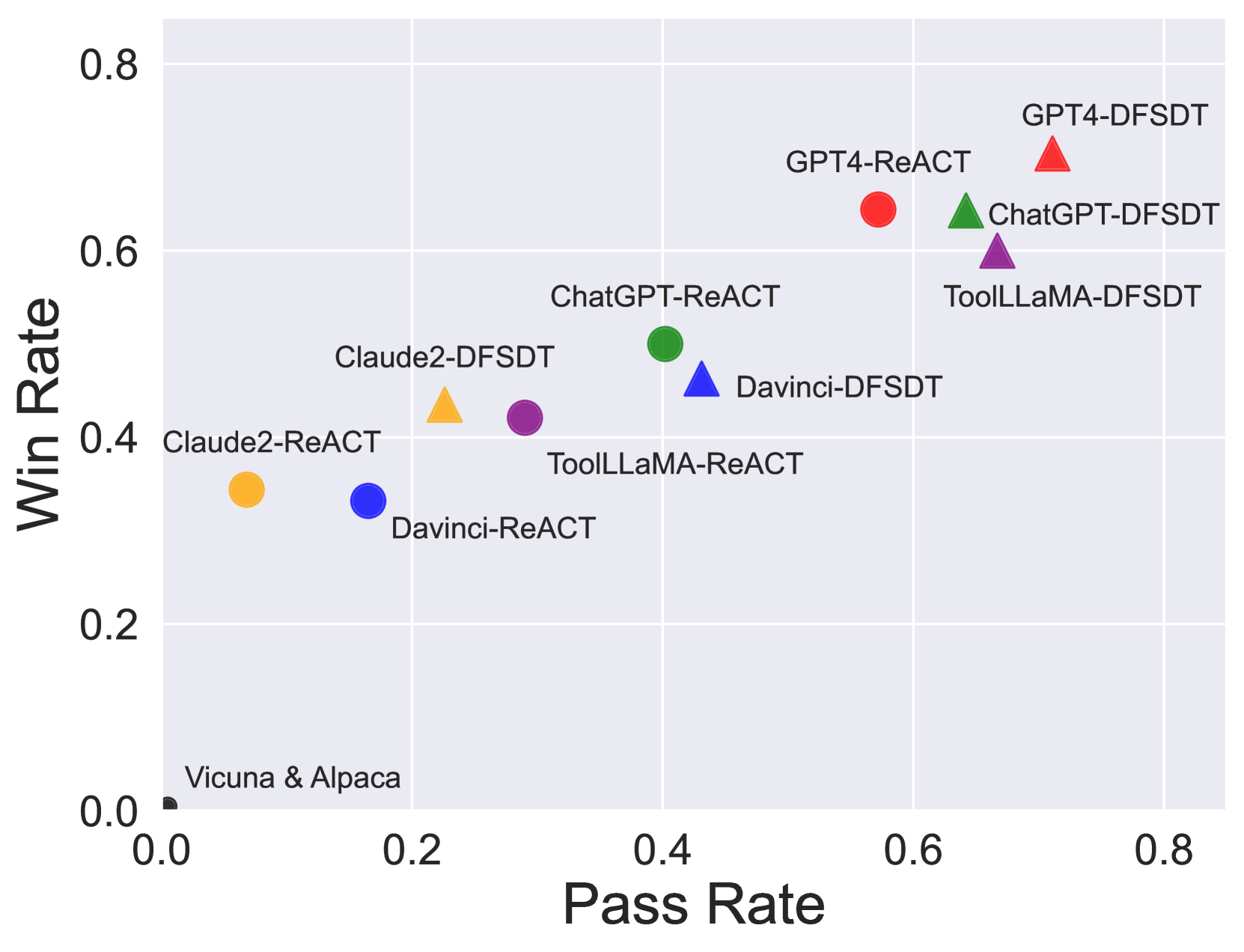
- ToolLLaMA achieves a 50% pass rate on complex instructions, outperforming text-davinci-003 (30%) and matching ChatGPT's performance within the same evaluator
- Achieves 60% win rate against ChatGPT on the ToolEval test set, demonstrating comparable tool-use capability to its teacher model
- Zero-shot generalization: Performs on par with the specialist model Gorilla on the unseen APIBench dataset despite never training on it
Breakthrough Assessment
9/10
A definitive work in open-source tool use. It creates the standard large-scale dataset for the field (ToolBench) and demonstrates that open models can match ChatGPT in API usage via specialized fine-tuning.