📝 Paper Summary
Agent deployment
Production systems
A systematic study of 86 deployed agents reveals that practitioners prioritize simplicity and reliability over advanced autonomy, favoring static workflows and human evaluation over complex planning and automatic benchmarking.
Core Problem
Despite widespread excitement and research on complex autonomous agents, little is known about how successful agents are actually built and deployed in production, creating a gap between research directions and real-world engineering needs.
Why it matters:
- Agent deployments often fail or underdeliver, yet successful patterns remain proprietary
- Research focuses on latency reduction and complex reasoning (RL, dynamic planning), while industry may value different attributes
- The field lacks shared data on the technical methods that enable reliability in real-world applications
Concrete Example:
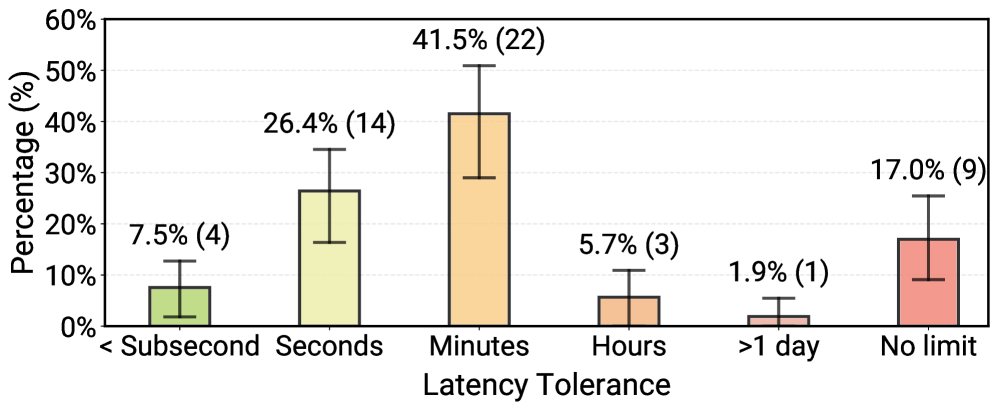
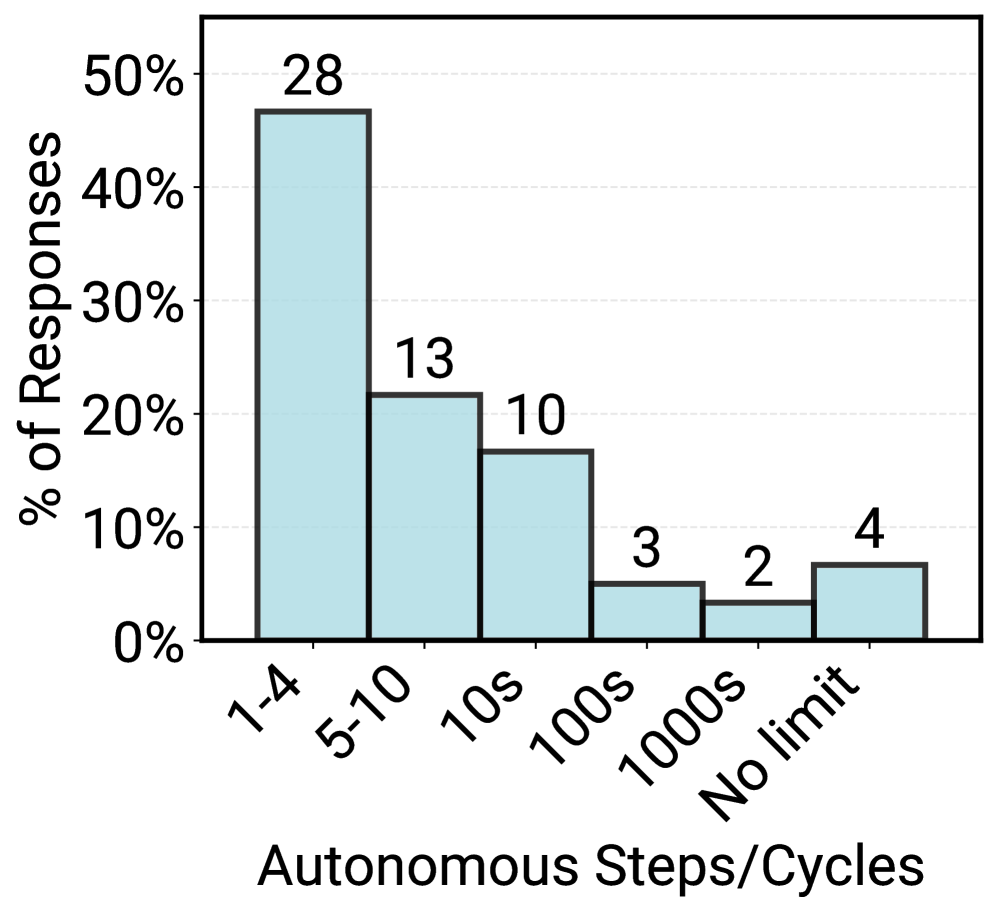
While researchers optimize for sub-second latency, 66% of production agents allow response times of minutes because they replace even slower human workflows (e.g., clinicians seeking insurance approval). Research emphasizes fully autonomous planning, but 68% of production agents are constrained to fewer than 10 steps to ensure reliability.
Key Novelty
MAP (Measuring Agents in Production)
- First large-scale empirical study collecting primary data from 20 in-depth interviews and 306 survey responses (86 deployed systems) across 26 domains
- Characterizes the 'simplicity-first' engineering paradigm of production agents: static workflows, human-in-the-loop evaluation, and reliance on prompting frontier models rather than fine-tuning
Architecture
Prevalence of Model Types and Custom vs. Framework implementations (Visual summary of technical stack)
Evaluation Highlights
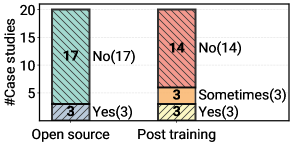
- 70% of deployed agents rely on prompting off-the-shelf models rather than weight tuning (SFT/RL)
- 68% of production agents execute at most 10 steps before human intervention, prioritizing control over long-horizon autonomy
- 74% of teams depend primarily on human-in-the-loop evaluation rather than automated benchmarks
Breakthrough Assessment
9/10
Provides rare, grounded evidence contradicting common research assumptions (e.g., latency sensitivity, need for RL). Essential reading for aligning agent research with reality.