📝 Paper Summary
Agent Evolution
Agent Frameworks
Tool Use
This survey unifies agentic AI research into a four-part framework based on whether the agent or the tool is adapted, and whether supervision comes from tool execution or agent outputs.
Core Problem
Current agentic AI systems struggle with reliability, domain shifts, and generalization because general-purpose foundation models lack the specialized adaptation needed for complex, open-ended tasks.
Why it matters:
- Agents failing in real-world deployments due to unreliable tool use or reasoning gaps limits adoption in critical fields like clinical research and software development
- Existing literature is fragmented between modifying agents (SFT/RL) and modifying tools (retriever tuning), lacking a unified guide for system designers
- Static agents cannot effectively handle unexplored environments where they lack prior interaction experience
Concrete Example:
A general-purpose agent attempting 'deep research' might fail because it hallucinates citations (agent failure) or retrieves irrelevant papers (tool failure). Without a structured way to decide whether to fine-tune the LLM or train a specialized retriever, developers rely on trial-and-error.
Key Novelty
Unified 2x2 Taxonomy for Agentic Adaptation
- Categorizes adaptation into two targets: Agent Adaptation (modifying the LLM) vs. Tool Adaptation (optimizing external modules like retrievers or memory while keeping the LLM frozen)
- Categorizes adaptation signals into two sources: Tool Execution Signaled (verifiable outcomes like code success) vs. Agent Output Signaled (final answer quality or reasoning traces)
- Explicitly maps trade-offs between these paradigms regarding cost, modularity, and generalization to guide system design
Architecture
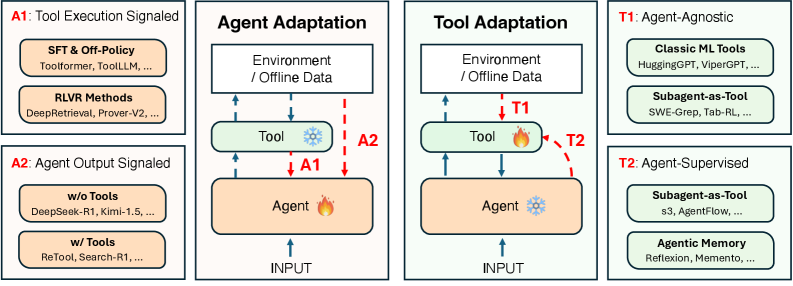
A 2x2 matrix visualizing the four adaptation paradigms.
Evaluation Highlights
- Not applicable — this is a survey paper
- Synthesizes over 100 recent papers into 4 distinct paradigms (A1, A2, T1, T2)
- Identifies key open challenges including unified agent-tool co-adaptation and theoretical understanding of adaptation dynamics
Breakthrough Assessment
9/10
Provides the first comprehensive, structured taxonomy for the rapidly exploding field of agentic adaptation. The 2x2 framework (Agent vs. Tool, Execution vs. Output signal) is highly clarifying and likely to become standard terminology.