📝 Paper Summary
Modularized RAG pipeline
Black-box LLM augmentation
REPLUG enhances frozen, black-box language models by prepending retrieved documents via an ensemble strategy and tuning the retriever using the LLM's own output probabilities as supervision.
Core Problem
Large language models (LLMs) >100B parameters are often only accessible as black boxes via APIs, making traditional white-box retrieval augmentation (which requires accessing internal representations or fine-tuning gradients) impossible.
Why it matters:
- State-of-the-art models like GPT-3 and Codex are commercially closed or too expensive to fine-tune (e.g., BLOOM-176B requires 72 A100 GPUs)
- Existing retrieval methods like RETRO or kNN-LM require modifying architectures or accessing internal hidden states, which fails for API-based models
- Black-box LLMs still suffer from hallucination and outdated knowledge despite their size
Concrete Example:
When predicting the continuation for a text about a rare entity like 'Li Bai', a standard GPT-2 model fails because it lacks specific knowledge. REPLUG retrieves a relevant biography, matches the entity name, and improves the probability of the correct next token by 11%.
Key Novelty
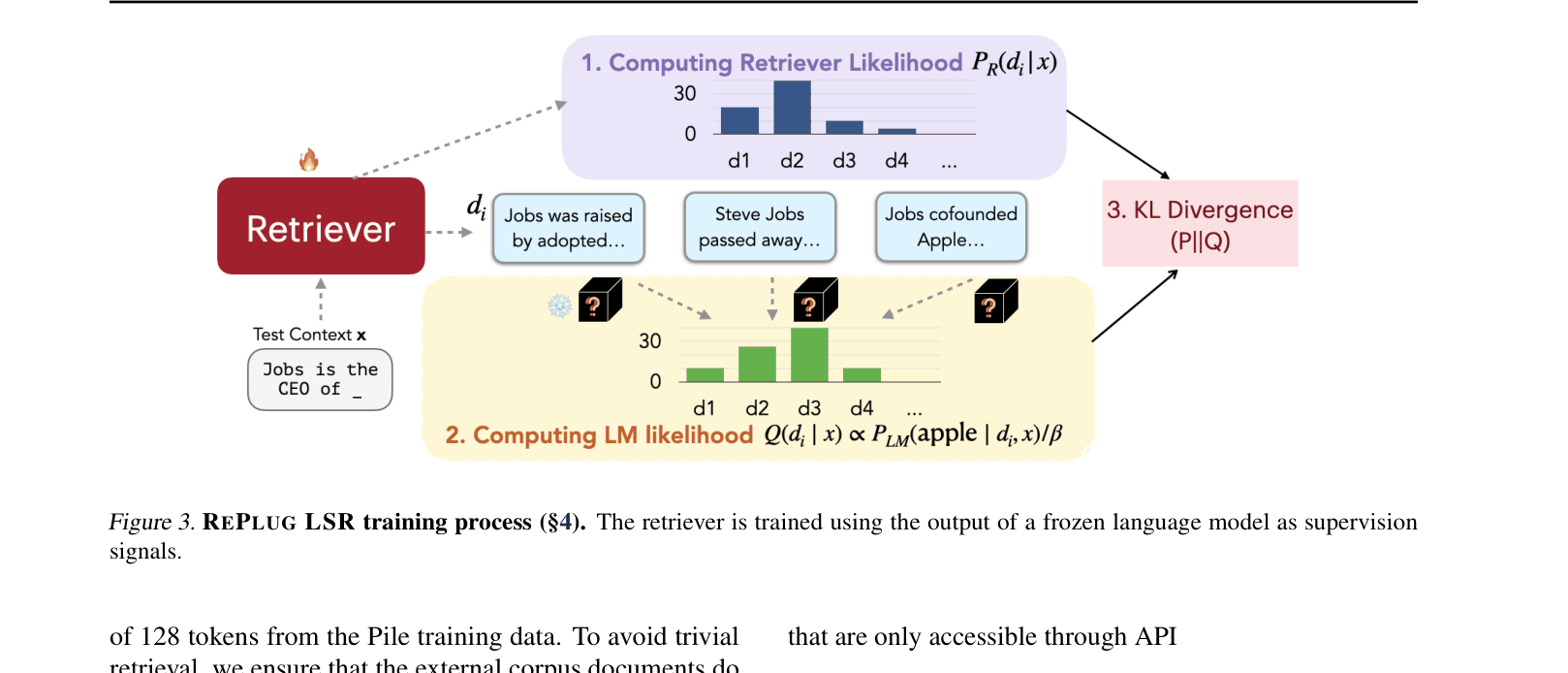
REPLUG (Retrieve and Plug) & REPLUG LSR (LM-Supervised Retrieval)
- Treats the LLM as a frozen scoring function: The retriever is optimized to find documents that minimize the perplexity of the ground truth text under the black-box LLM
- Parallel Ensemble Inference: Instead of concatenating all documents into one long prompt (which hits context limits), documents are processed in parallel passes and predictions are ensembled based on retrieval scores
Architecture
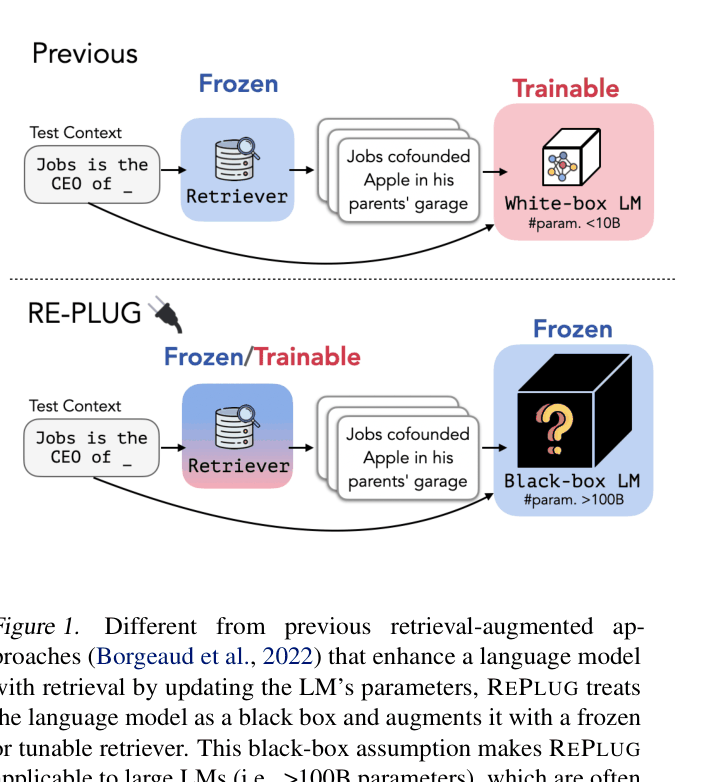
Overview of the REPLUG inference process and the Black-Box assumption
Evaluation Highlights
- +6.3% improvement in language modeling (perplexity) for GPT-3 Davinci (175B) on the Pile dataset using REPLUG LSR
- +5.1% accuracy improvement on MMLU (Massive Multi-task Language Understanding) for Codex (175B) using 5-shot in-context learning
- Achieves state-of-the-art few-shot performance on Natural Questions (45.5%) and TriviaQA (77.3%) using Codex, outperforming the white-box Atlas model trained on 64 examples
Breakthrough Assessment
8/10
First framework to successfully apply retrieval augmentation to >100B black-box models with retriever tuning, demonstrating that frozen LLMs can supervise their own retrieval modules.