📝 Paper Summary
Modularized RAG pipeline
Knowledge internalization
In-Context RALM demonstrates that off-the-shelf language models can achieve significant performance gains by simply prepending retrieved documents to the input context without any architecture changes or fine-tuning.
Core Problem
Standard language models hallucinate facts and lack source attribution, while existing Retrieval-Augmented Language Modeling (RALM) methods require complex architectural modifications and expensive retraining.
Why it matters:
- Modifying LM architectures (like RETRO) complicates deployment and prevents using LMs available only via API
- Factual inaccuracies and lack of provenance hinder the adoption of generative AI in high-stakes or knowledge-intensive domains
- Retraining large models to accommodate retrieval mechanisms is computationally prohibitive for many practitioners
Concrete Example:
A standard LM might hallucinate that 'World Cup 2026 will expand to 48 teams' without evidence. By prepending a retrieved news snippet about the 2026 tournament to the context window, the frozen LM correctly predicts the next tokens based on the ground truth.
Key Novelty
In-Context RALM (Retrieval-Augmented Language Modeling)
- Leaves the LM frozen and unmodified, using the standard input context window to 'read' retrieved documents
- Utilizes off-the-shelf retrievers (like BM25) to select documents based on the current text generation prefix
- Introduces LM-oriented reranking where a model scores retrieved documents based on how well they predict the upcoming text tokens
Architecture
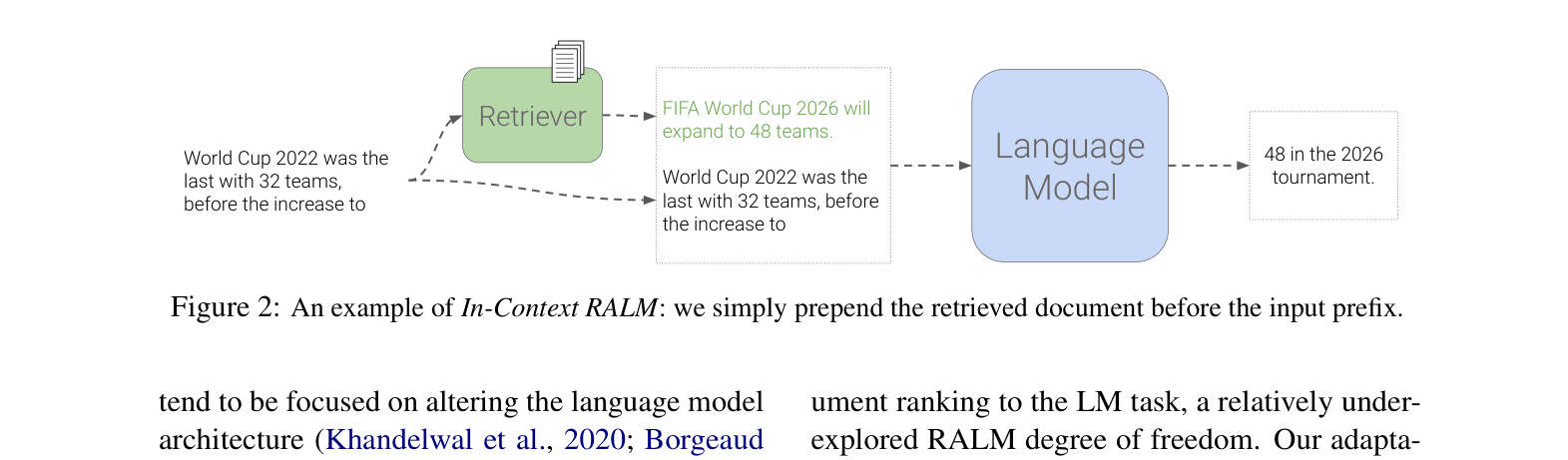
Conceptual diagram of In-Context RALM mechanism
Evaluation Highlights
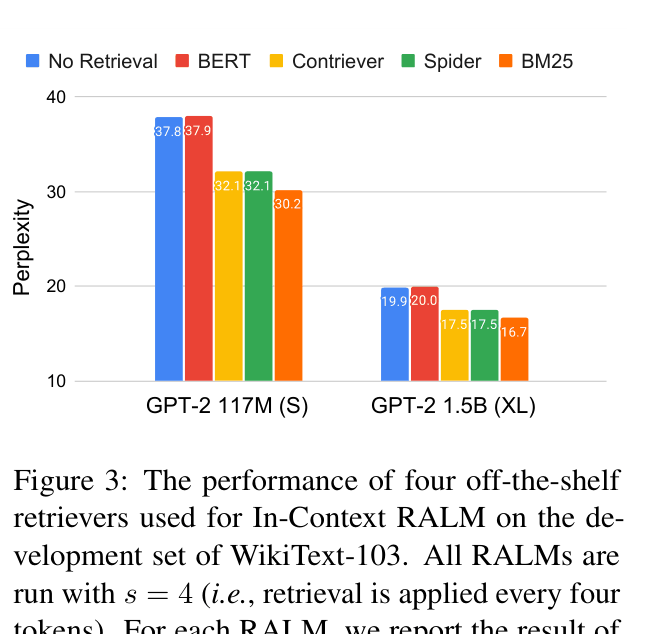
- A 345M parameter GPT-2 with In-Context RALM outperforms a 1.5B parameter GPT-2 (4x larger) on WikiText-103
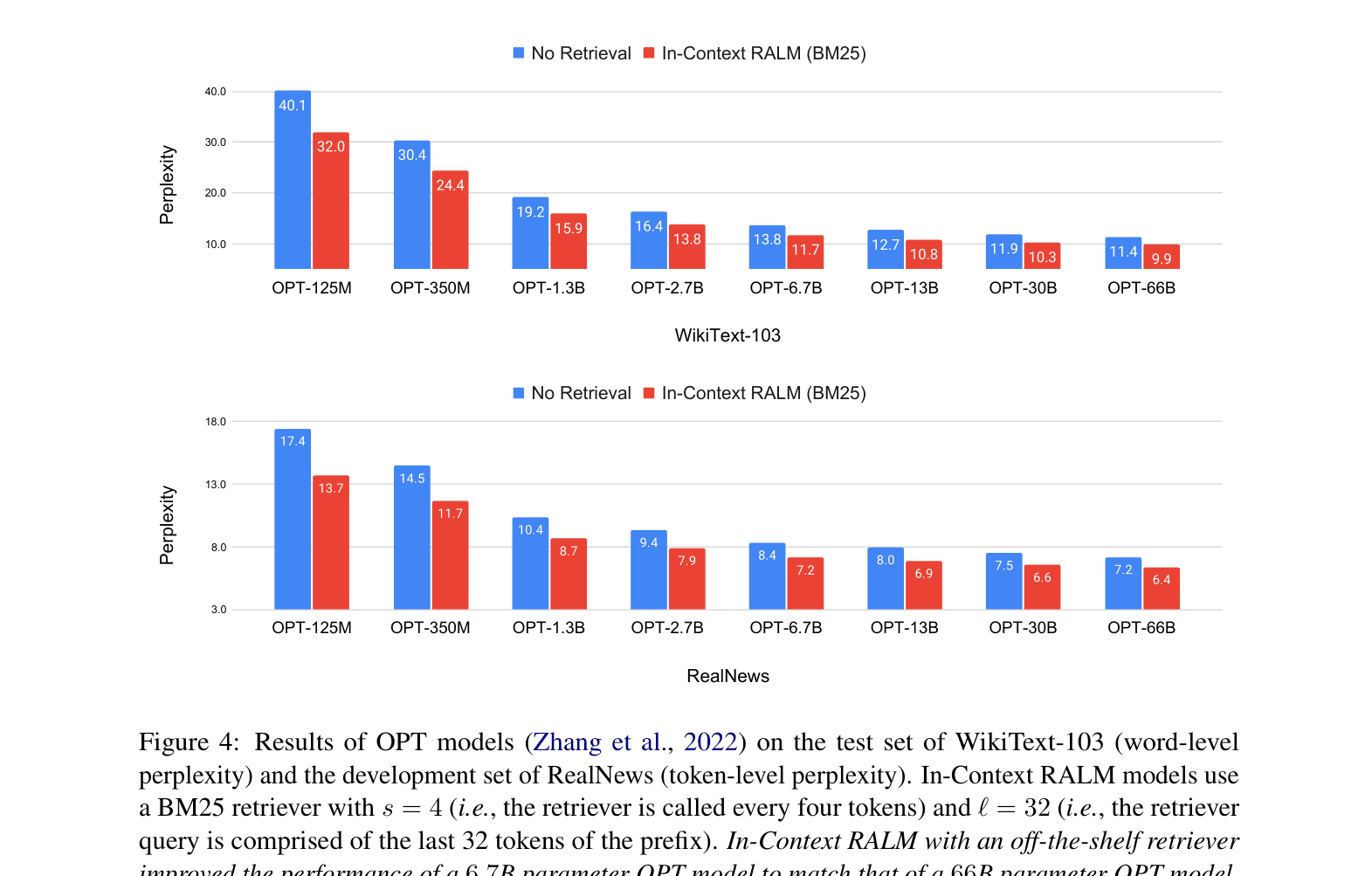
- In-Context RALM with BM25 improves a 6.7B parameter OPT model to match the perplexity of a 66B parameter OPT model (10x larger)
- Sparse retrieval (BM25) surprisingly outperforms dense retrievers (Contriever, BERT) for the language modeling task in zero-shot settings
Breakthrough Assessment
8/10
Highly impactful for practitioners because it unlocks RAG capabilities for any black-box LLM without training, demonstrating that simple context prepending rivals complex architectural modifications.