📝 Paper Summary
Agentic RAG pipeline
Reflective generation
Self-RAG trains a single language model to adaptively retrieve information and self-critique its own outputs using generated reflection tokens, enabling controllable trade-offs between factuality and creativity.
Core Problem
Standard RAG approaches retrieve indiscriminately (even when unnecessary) and lack mechanisms to verify if the retrieved content is relevant or if the final generation is supported by evidence.
Why it matters:
- Indiscriminate retrieval can introduce noise or off-topic information, hurting versatility for creative tasks
- Models often ignore retrieved context or hallucinate answers that contradict the evidence
- Current methods lack fine-grained control over generation behaviors (e.g., forcing high citation accuracy versus fluent continuation) without retraining
Concrete Example:
When asked a personal essay prompt like 'Write about your best vacation,' standard RAG might force retrieval of irrelevant travel guides, lowering quality. Conversely, for a factual query, standard RAG might retrieve a relevant document but the model still hallucinates an unsupported answer.
Key Novelty
Self-Reflective Retrieval-Augmented Generation (Self-RAG)
- Trains an arbitrary LM to generate 'reflection tokens' (Retrieve, IsRel, IsSup, IsUse) alongside text, allowing the model to self-assess the need for retrieval and the quality of its output
- Uses a 'critic' model to annotate a training corpus offline with these reflection tokens, then distills this capability into the generator via standard next-token prediction
- Enables inference-time control (e.g., 'cite more frequently') by weighting reflection tokens during beam search without requiring model retraining
Architecture
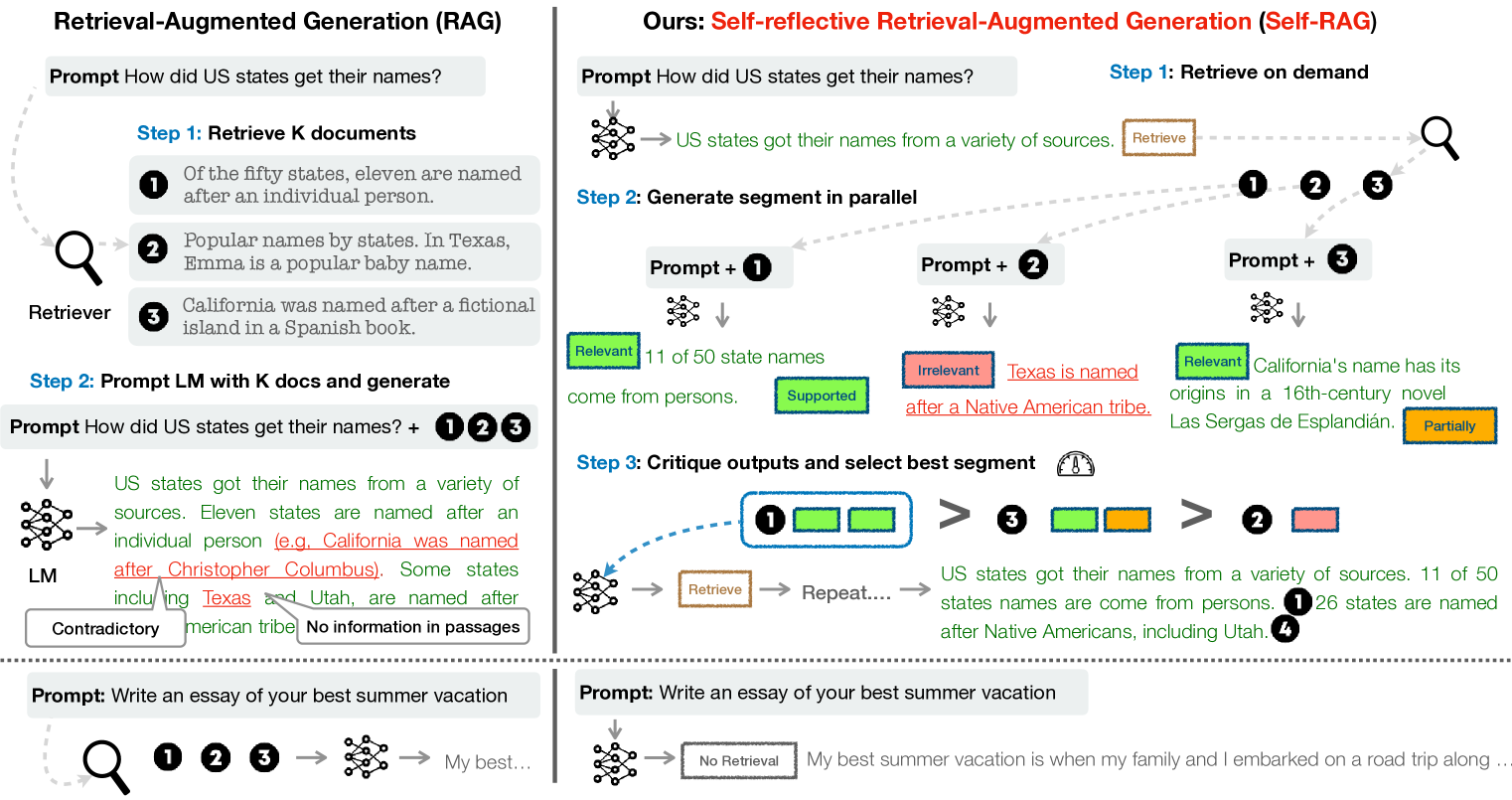
Overview of the Self-RAG inference framework compared to standard RAG. Shows the generation of reflection tokens at each step.
Evaluation Highlights
- Outperforms ChatGPT (retrieval-augmented) and Llama2-chat (retrieval-augmented) on Open-domain QA, reasoning, and fact verification tasks
- Significantly improves factuality and citation accuracy for long-form generation tasks (e.g., biography generation) compared to standard RAG baselines
- Achieves higher performance with 7B/13B parameters than larger proprietary models on diverse tasks like PubHealth and PopQA
Breakthrough Assessment
9/10
Introduces a highly flexible, training-efficient paradigm (reflection tokens) that solves major RAG pain points (indiscriminate retrieval, lack of self-verification) and enables controllable inference.